

JFrogのログ分析をSplunkで

両方を使用することで最良の結果が生み出されます。
単一のユーザーインターフェースで動作するように、すべてのソリューションを統合したJFrog DevOpsプラットフォームを構築しました。Artifactory 7によるこの統合はソフトウェアのビルドパイプラインを完全に制御できます。
また、プラットフォームの運用を維持するためにはプラットフォーム全体の運用状況をリアルタイムで統一的に把握する必要があります。すでにお使いの分析/可視化ツールを利用して、非常に容易に実現できるツールをいくつか提供しています。
ここでは、これらの新しい JFrogツールをインストールし、Splunkを利用したJFrogプラットフォームの動作を監視する方法をご紹介します。
統合プラットフォームのためのログ集約
JFrogプラットフォームは多数のマイクロサービスによって実現されており、それぞれが独自のログレコードを持っています。高可用性のJFLogプラットフォーム・デプロイメント(JPD)のように複数のノードに分散している場合、プラットフォームの全操作はネットワーク上の25以上のログに分散している可能性があります。
運用チームはパフォーマンスを分析し、運用上の問題を追跡するために、このJPDログデータを1つに集約する手段を必要としています。また、小規模な企業のJPDであっても毎日何百万ものトランザクションイベントを記録している場合、オペレータはそのデータの詳細を確認するためには強力な分析ツールを利用する必要があります。
Splunkの準備
Splunkがログデータを受信できるようにするにはSplunkでHTTP Event Collector (HEC) を設定する必要があります。Splunk EnterpriseでHECを設定することができます。
Splunkで既に他の用途でHECが有効になっている場合でも、JFrogプラットフォームで排他的に使用するための認証トークンを作成する必要があります。
HECの設定から以下の内容を確認しておく必要があります。
- HECトークン – 認証のために作成したGUID
- HECホスト – HECを実行するSplunkインスタンス
- HECポート – HECグローバル設定で指定したポート番号
この設定によりSplunkはJFrogプラットフォームからのメッセージを受信できるようになります。
Fluentdの使用
まず、オープンソースのデータコレクタであるFluentdを利用できるようにしました。FluentdはJFrogプラットフォームの各製品に対するログ入力、フィールドの抽出、レコードの変換を行い、このデータをJSONに変換します。
すべてのログデータを共通フォーマットで利用できるため、Fluentdはプラグインを介して、お客様が選択した分析ツールにログデータを送信します。
Fluentdのインストール
各JPDノードにはFluentdロギングエージェントがインストールされている必要があります。このエージェントは様々なJPDログファイルを処理し、新しいログ行を解析後、対応するレコードに変換し、Fluentdの関連する出力プラグインに送信する役割を持っています。
各ノードにFluentdエージェントをインストールするにはFluentdインストールガイドに記載されている通り、OSの種類に応じた手順を実施します。
例えばRed Hat UBI Linuxを動作させているノードではFluentdエージェント 「td-agent」をインストールする必要があります(このOSではrootアクセスが必要です):
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
インストール後、「td-agent」は指定されたディレクトリに存在します:
$ which td-agent
/usr/sbin/td-agent
また、お使いの分析ツールに合ったFluentd出力プラグインをノードにインストールする必要があります。Splunkの場合はSplunk Enterprise用のFluentdプラグインになります。
Fluentdの設定
Fluentdエージェントをインストール後、デフォルトの設定ファイルが含まれています。
$ ls -al /etc/td-agent/td-agent.conf
-rw-r--r-- 1 root root 8017 May 11 18:09 /etc/td-agent/td-agent.conf
この設定ファイルをGitHubリポジトリのJFrog Log Analyticsの設定ファイルに置き換える必要があります。
このリポジトリのfluentdフォルダに設定ファイルのテンプレートが含まれています。ノードで実行されているJFrogアプリケーションにマッチするテンプレートを使用してください。
テンプレートをダウンロード後、Fluentdの設定ファイルにSplunk HECの値を設定する必要があります:
...
#SPLUNK OUTPUT
@type splunk_hec
host HEC_HOST<
port HEC_PORT
token HEC_TOKEN
format json
# buffered output parameter
flush_interval 10s
# time format
time_key time
time_format %Y-%m-%dT%H:%M:%S.%LZ
# ssl parameter
use_ssl true
ca_file /path/to/ca.pem
@type splunk_hec
host HEC_HOST
port HEC_PORT
token HEC_TOKEN
format json
# buffered output parameter
flush_interval 10s
# time format
time_key timestamp
time_format %Y-%m-%dT%H:%M:%S.%LZ
# ssl parameter
use_ssl true
ca_file /path/to/ca.pem
#END SPLUNK OUTPUT
Fluentdの実行
設定ファイルが作成されたのでシステム上のサービスとして「td-agent」を起動できます:
$ systemctl start td-agent
設定ファイルを指定して、直接「td-agent」を実行することもできます:
$ td-agent -c td-agent.conf
これでFluentdのロギングエージェントが起動し、JPDのログをSplunkに全て送信することができます。
Splunkの使用
集約されたログデータがFluentdを通して利用可能になった後、Splunkを使ってデータの検索、分析、可視化を行うことができます。
Splunkbaseで利用できるSplunk用のJFrog Logsアプリをインストールし、JFrogプラットフォームのログデータをSplunkアカウントに接続する必要があります。
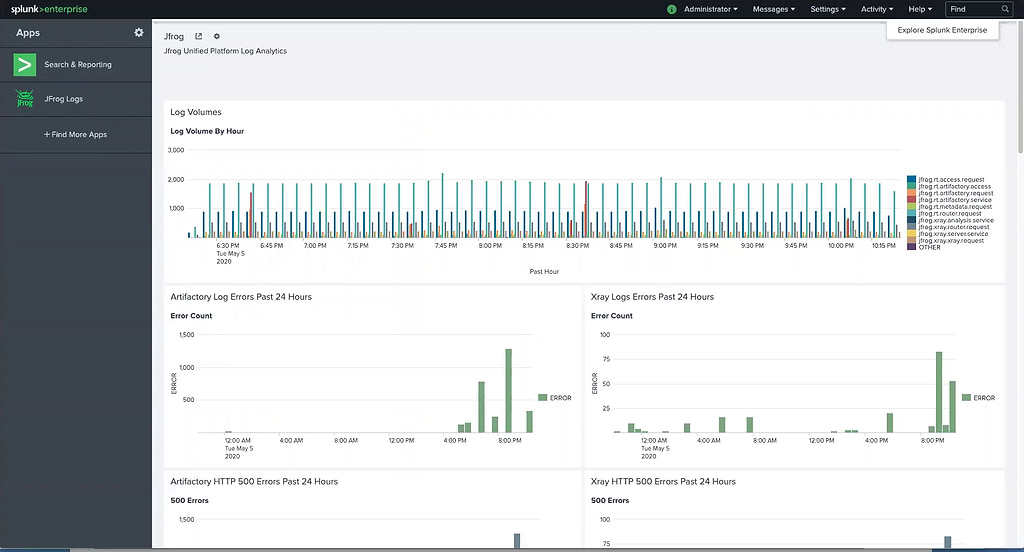
インストール後、JFrog Logsダッシュボードには主要なメトリクスのタイムラインとカウントデータが表示されます:
- タイプでフィルタリング可能なLogボリューム
- サービスエラー
- HTTPレスポンスコード
- アクセスしたイメージ
- アクセスしたリポジトリ
- アップロード/ダウンロードしたデータ転送量(GB単位)
- アップロード/ダウンロードしたトップ10のIPアドレス
- ユーザー名による監査アクション
- IPとユーザー名による拒否されたアクションとログイン
- デプロイしたユーザー名
集約されたデータを使用してSplunkで独自のカスタムダッシュボードを作成し、運用に必要な情報も取得できます。
集約
ログ分析のインストールによって、JFrogプラットフォームはすべてのサービスと実行ノードの監視が非常に簡単になります。
この完全なソリューションはArtifactory 7とJFrogプラットフォームの他のコンポーネントでのみ動作します。Artifactory 6からのアップグレードをご検討している場合、これをアップグレードする理由の一つに加えてください。
See what JFrog & GitHub can do together



