

特徴量のライフサイクル全体を1つのJFrog ML Feature Storeで管理
JFrog ML Feature Storeは、特徴量のライフサイクル全体を最適化し、特徴量のコラボレーションを可能にし、一貫性を確保し、特徴量のエンジニアリングとデプロイの信頼性を向上させます。
JFrog ML Feature Storeは、プロジェクト間のコラボレーションと特徴量の共有を容易にします。運用モデルで使用される検出可能な信頼できる唯一の特徴量の情報源になります。
チームの規模やデータセットの複雑さに関係なく、特徴量の管理を迅速化および簡素化します。


保持しているデータを変革
データパイプラインを構築およびデプロイする特徴量を簡単に作成できるため、インフラストラクチャではなくインサイトに注力できます。
 Manage the entire model lifecycle with a single centralized registry
Manage the entire model lifecycle with a single centralized registry- Gain visibility into training parameters, hyper parameter tuning and model metadata
- Manage model and traditional software artifacts in one system
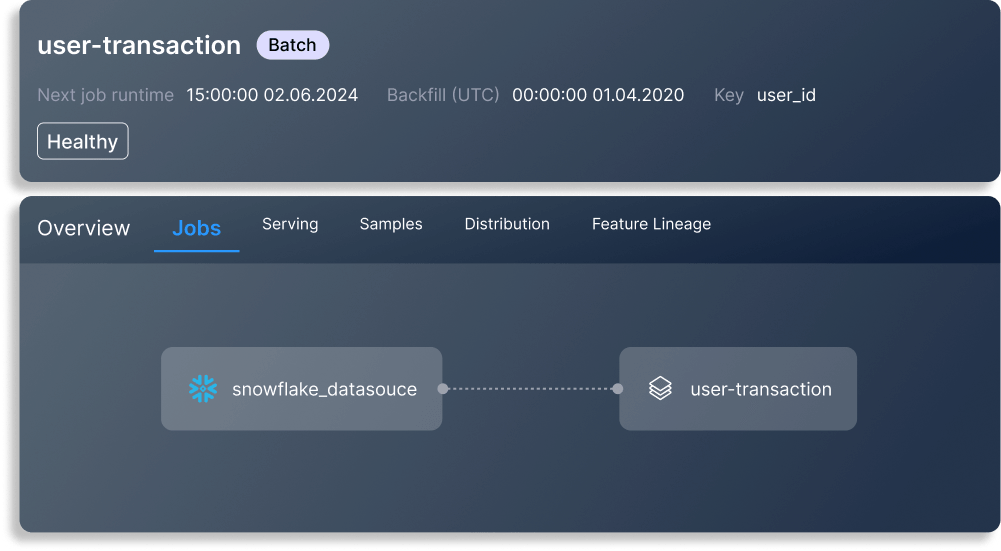
特徴量の保存と提供
すべての特徴量を1つのシステムで保存、管理、提供します。データサイエンティストとMLエンジニアが簡単にコラボレーションし、プロジェクト間で特徴量を共有できるようにします。
- Large scale and cost-effective offline store for training data
- Lightning fast, low-latency online store for inference data and online serving
- Automatically maintain feature consistency across environments
- Fill in missing values for high-quality data accuracy for robust model performance
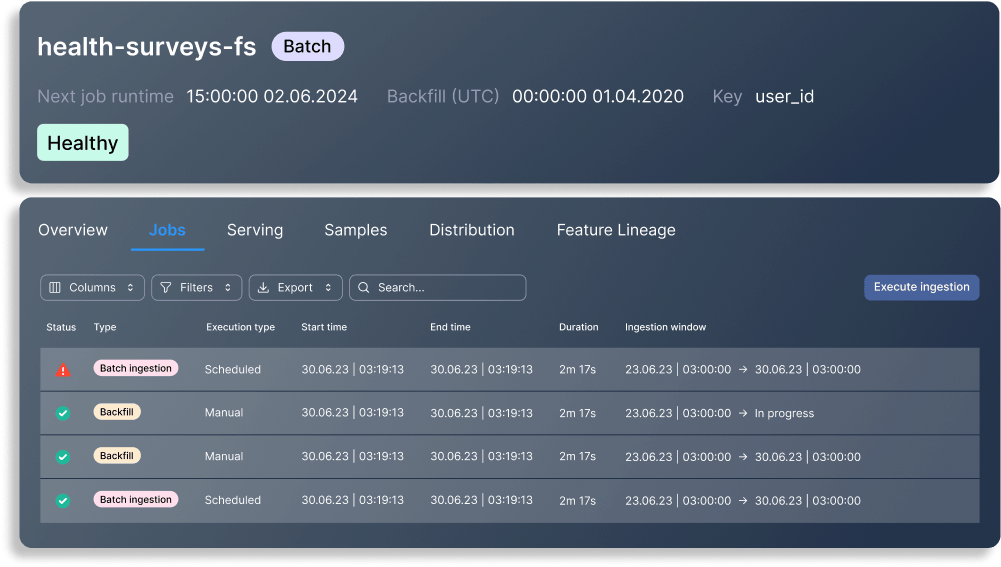
データの取り込み
データウェアハウスや複数のソースからデータを取り込みます。関連する特徴量を処理、抽出、変換し、それらを特徴量ストアの集計値に格納します。

この流れに乗り遅れないように。AIによるデータ分析には柔軟なインフラが必要です。先手を打ってください。
大量の特徴量データ
お客様のセグメンテーションレポート、履歴データの分析、スケジュールに従った大規模データセットの処理など、定期的なタスクの大量の特徴量データを効率的に処理および管理します。大量の特徴量が一貫して更新され、モデルのトレーニングと推論に使用できることを確認します。
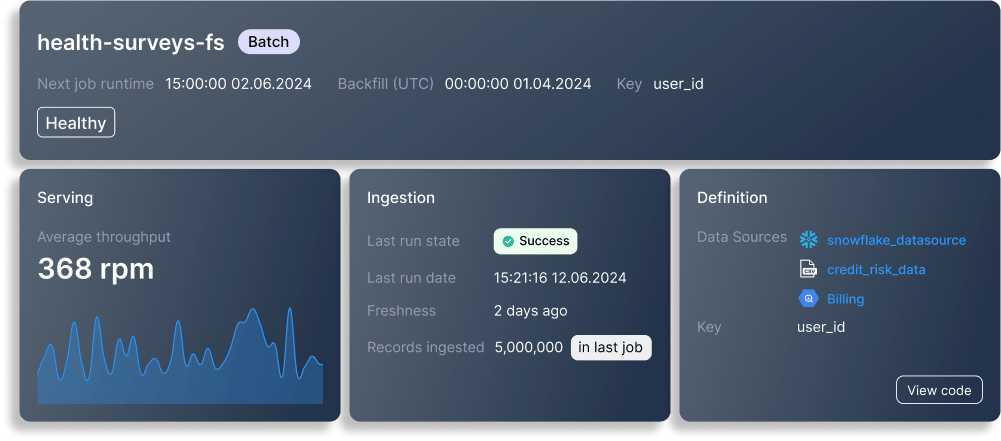
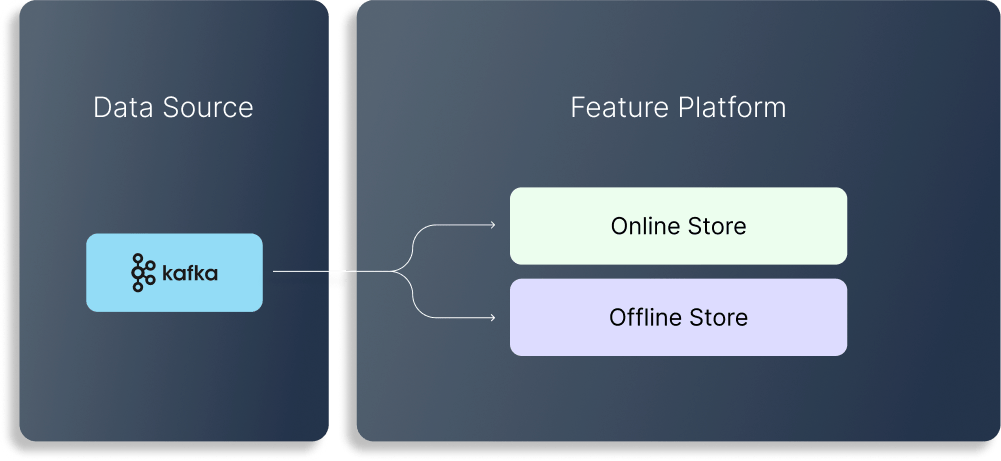
ストリーミングの特徴量セット
Kafkaからのストリーミング データを使用して、リアルタイムの特徴生成と処理をサポートします。生成されたデータを継続的に収集して処理し、リアルタイムの分析を可能にします。リアルタイムのインサイトを必要とする用途に最適です。
マルチクラウド:当社のクラウド、それともお客様のクラウド
JFrog MLはAWSとGCPをネイティブにサポートしており、当社のプラットフォームまたは独自のインフラストラクチャにデプロイしてフローを効率化することができます。



