

Improving microservices DevOps with Dapr and Java
Certain DevOps practices became a must-have in distributed cloud native development.
Others are crucial for high code quality delivery.
Let’s explore them and their impact on making your projects successful

Video Transcript
Hello, and welcome. Thanks for joining the session today, today, Artur and I will be talking about improving microservices and the DevOps process with a new technology called Dapr together with Java. My name is Paul Yuknewicz, I’m one of the product leads on the Azure team. My focus is on the Dev platform and on frameworks, I’m also a Dapr community member.
I’m Artur Souza, I’m engineering manager in the Dapr team and also a Dapr maintainer.
All right, so jumping into this, Artur and I being on the team for a while, we’ve been working with a number of developers and operators over the last few years, and we’ve been learning about the needs and the top challenges. One thing that we hear very often is that teams need to be very productive building and deploying and automating the process around building microservices. And we hear very often that what’s holding them back is a limited set of tools and run times to build these more distributed applications using microservices. Even when there are runtime choices that exist, we also find those tend to be very limited with either tightly controlled feature sets or maybe they only support one particular language, and not the language that you happen to be using with your team.
Another need that we hear is really common, is we need to target a number of different platforms and a number of different environments in our process. So for example, a more modern target right now is Kubernetes, and a lot of workloads are trying to target Kubernetes, but we also have a number of workloads that are running on VMs that are running on the cloud, that are running on the Edge, and even mixes of all together. And so we set out to mitigate that challenge of running on a number of different environments and to ensure greater portability.
So with that said, next comes in Dapr. Dapr literally stands for Distributed Application Runtime, so that’s what the acronyms for, and Dapr is really all about building distributed applications faster, that’s why we choose Dapr. What Dapr specifically is, Dapr is a set of APIs, and the APIs are really focused on building reliable microservices and ensuring that your microservices are very portable. Taking a closer look at this, the kinds of things that we see in Dapr, so the first of all, like we mentioned, we have a set of the APIs, and APIs are there for the most common scenarios, so whether that’s service to service calls, if we build out the picture, we’ll see that.
Also a very common application type is Pub/Sub, where we have asynchronous messages and a broker, and some guarantees about what will be received. An overall feature that we have across Dapr and across the Dapr runtime is resiliency. That’s things like retries, resilient calls and things like having circuit breakers and back offs and different policies. And that’s something that we’re going to make an ongoing investment, so that as we build out Dapr, there’ll be more and more resiliency at every step of the way.
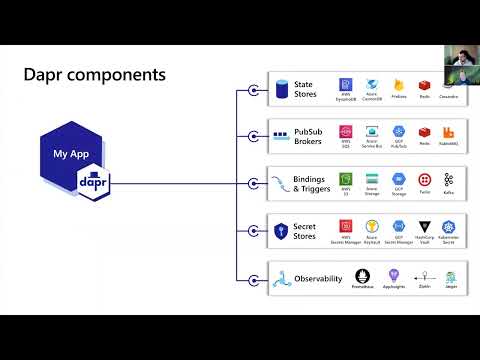
Messaging, as I mentioned with asynchronous, is very important, so whether using messages or you’re using events, there’s a number of integrations that are built in. As we can see in the picture, if your favorite happens to be Kafka or RabbitMQ, or using one of the public clouds, we support really a number of these integrations and they’ll be growing over time. And as I mentioned in the challenges slide, we really set out to make Dapr portable.
So Dapr itself is portable as a runtime and you can run it in a number of different environments, so you could run it locally on your machine, just using a CLI, you could install it in all your different environments from staging, pre-prod, all the way to prod, and you get to have a number of environmental differences. So for example, you could run in environment in a different cloud, you could run multi-cloud, you could run in Kubernetes, you can run with no Kubernetes, and you can run on the Edge.
So really running Dapr everywhere, and then hence, being able to run your microservice everywhere, was a really important goal. And not only is it the app and the host environment, it’s also about your tendencies, right? So we talked about things like your event brokers. We want to make sure that the free, open source storage and state management services, well, the Pub/Sub brokers and the secret stores, that the favorite ones of your choice also work super well with Dapr, and you write your code once against a standard set of APIs, and we can dynamically bind through config to your software of choice.
Here, when we zoom out, we can see a few different layers in how this is working. So our application code, as we know, we write it in one of our favorite languages. Today we’re really going to focus on Java and Spring as our stack, however, it’s important to see that many of the common languages that we use and love today, whether it’s Go or Note or Python or .Net, even C++, as a native language, you can write your application code in any of these, and you can call the APIs from Dapr in a restful way. As we show in the middle of the diagram, you can make calls restfully, either using HTP or using gRPC, and so we support two of the most common API styles. And you’re seeing a set of the scenarios that we enable in the Dapr box, so the most common ones that we see developers and ops start with, would be service to service calls, which would be at the far left. Towards the middle, publish and subscribe for writing that asynchronous message and event based app, that’s also very common.
But as you evolve and deepen your engagement with microservices apps, you’ll be adding things like observability, you’ll have secrets. If you have thousands or tens of thousands of objects with state, you can use things like actors, so the API set is pretty broad and it’s going to keep growing, and like I mentioned, it’s there to make you productive doing common tests. And then last, if we stay on the hosting infrastructure, I just want to point out that Dapr can and run on a number of different hosts, like Kubernetes, I think would be an important one to think about, but also all of the, or many of the container and PaaS services we can run on, whether that’s in AWS, Google, Azure, Alibaba Cloud, and you can also run on VMs, you could run on the Edge. So really, Dapr is going to give you that flexibility to run the same application, the same code in all these different places without rebuilding it, and that’s one of the strengths and sweet spots of Dapr.
So as we go on next, one of the ways that we enable this portability, is through a component model. So if you think about it, Dapr has a set of APIs, which I mentioned are restful and they’re consistent, so each one of these things, whether it’s state stores, for state management, or Pub/Sub, that’s an API, but we also have a set of components, which is like a one to many relationship where you can back the eight API with your favorite component, and let’s take the case of Pubs/Sub, it could be on my local machine, it could be Redis, and in production, it could be RabbitMQ, because that’s what my team has chosen. And just using a swappable YAML file, I can configure the environment and effectively and bind mount to my favorite component without changing the application code at all, so that’s one of the ways that we enable an end to end portability of the application. Today we have over 70 components available, many of the most popular open source and also cloud vendors have components provided, and we plan to work with the community to grow this over time.
Now, one of the important technical underpinnings, and I know Artur will spend more time showing you this in action, is the sidecar model. Now, oftentimes when you hear sidecar, we think about Docker and Docker containers as sidecar. I want to be careful and just point out, here we’re talking about processes. So my application and binary starts as a process, let’s say I run Java on my JAR file and that starts as a process, but also the Dapr sidecar starts as its own process, and that becomes a very important process that can do things on our behalf, like an ambassador. It can make calls, it can make the calls more reliable, it can work with the different components we have and basically provide this extra layer of resiliency and portability for our application. So as a developer, I think about just making that restful call. So if I’m going to call the Dapr process, let’s say on my development machine, by default, it would be on local host, and on a default port of 3,500. And then I just call the restful APIs. So if I want to make service call, I would call invoke as that shows, and then I call the service and the action that I want.
If I want to do some state management, same thing, I call the same endpoint, but this time I’m going to call the state API. I’m going to index by item 67 and consistently this approach moves on, so for Pub/Sub, I can do a publish this way and I can make another function be a receiver and a subscriber. So as you can see again, the sidecar process sits next to the app and it provides that consistent API, and it is the thing that is very portable and re-bindable to a number of components. And just to reinforce, you can use this in containers, but containers actually aren’t required at all, and I think that’s one of the sweet spots of Dapr. So that said, I’ve given you an overview. I want to hand off to my colleague Artur who has a lot more hands-on things to show.
Okay Paul, thanks for the great introduction to Dapr. Now we’re going to go and see a demo of Dapr working in a Java application. So we going to use the Twitter processing pipeline example, it’s example that you can find also implementing different languages. Today we’re going to go and show again the Java version of it. And so, let’s go through some of the components so you can understand how this application works.
So we have a Twitter provider application that received tweets from the Dapr sidecar via the Twitter binding, which is a component that’s implemented in the Dapr sidecar already, and that receive the tweets through each vehicle. You’re going to process that by make a servicing vocation to the settlement processor, to get a settlement score, to see if the tweet is positive, neutral, or negative a sentiment, and then you’re going to save the tweet to the state store and publish that to the Pub/Sub using Redis as example. And then there’s another component called tweet viewer that has a sidecar as well, and that will basically render a website, that are going to subscribe to the events and show them on the website using web sockets. So that’s basically it, you subscribe to the tweets, get the sentiment score and display them on the website.
So let’s run this example. So you require secrets, so we’re going to use in this example, because we’re running locally, we’re going to use a [inaudible 00:12:47] file, and all the attributes you can get from your Twitter development account, and there instructions on the website on how to get that. We’re going to keep those hidden here for security reasons. And we also going to use the Azure Cognitive Services API to get the sentiment analysis for the text.
So now we’re going to actually run the first component, which is the sentiment processor. In this case, we’re also simulating the compilation of the application, we’re using Maven in this example. As you can see, the build succeeded, and now we’re going to do a Dapr run to run the process. As you can see, I specify the path of the components, the application port that the app is going to listen to, and also give the ID, sentiment processor, which is very important.
And Artur, if I look at that, I’m used to doing a Java/JAR and passing in my JAR just to run, and it looks like you’ve prefixed that with just a Dapr run and things like the name of the service in front of it. Is that how I think about it?
Yes, that’s a great observation. So you still run the process the way you use to do by Java JAR, but Dapr run is prefixed, so it can get the nice Java environment variables that enables DES2K to work out of the box.
That’s good. And I think that starts the sidecar too, right?
It all starts a sidecar, yes. Great question. And I’m going to do a Dapr run again for the next process, which is following the same strategy, but the port is different, as you can see. The components path can be shared, it doesn’t need to be unique per run, and as you can see, so you got some tweets, look at that. And you get the sentiment analysis as well, okay.
So now let’s run the actual web UI and we can see these tweets and the sentiment analysis being displayed together, and we always run with Dapr run, again, components path and application port and this port of the sidecar is randomly determined by Dapr run, so I don’t need to worry about the conflict of the sidecar port. Okay, so we’re getting the display, now we’re going to show this on our web browser. And as you can see, the icon, it’s like a face with red, blue or gray. There you go, show you the sentiment of each tweet, and it’s getting tweets from different languages, of course. And that is how you run an application using Dapr locally.
So let’s go a little bit deeper into how the Java SDK works for Dapr. So if you have a Java application, you can integrate with Dapr in different layers, you can use the basic SDK, which will allow you to do things like state store, Pub/Sub, secret, and even binding to some extent. Now, if you want to use actors, you can now depend on another artifact, which is a Dapr.sdk actors, which includes also the basic SDK, and in this way, you can also invoke actors, or you can also serve actors by having the actor runtime built in.
If you want to use Dapr with Spring Boot, you can even have even more convenience by depending directly on the Dapr SDK Spring Boot artifact, where you will automatically have the controllers that Dapr requires. For example, for you to handle Pub/Sub subscribe via a topic annotation, or for you to have the actor runtime handles also implemented automatically Spring Boot for you. And it’s a smooth integration if you want to use Spring Boot, if you don’t use Spring Boot, you just depend on the other versions, but it might require some manual implementation of each of the controllers. But again, we can add more in the future, but right now we’ve really focused on Spring Boot applications. So the way you depends on the artifacts is the same way you would depend on any other Maven dependency, either in Maven or through Gradle, it works either way. And the latest version that we have for the SDK is 131.
So how can you use, for example, state store as we saw in this example. So you have a Dapr client that in a sense, that you can reuse, and you call save state, you pass the state store name, you pass the key, in this case it’s Planet, and you pass the object, in this case is a complex type called Planet, that is going to be serialized by that SDK automatically into chasing, and the state store, you’re going to get a key with the application idea as a prefix and the key of the item as a suffix, and then you can have the value as a serialized object. And this works for multiple state stores, you decide that with the configuration, your code does not change.
And to do a get is the opposite, where you do a .get state and then you do the same thing, pass the state store name, the key and then pass the class type that you’re reading so the SDK knows how to de-serialize it back to the object you request, the same pattern you have for any serialization API in Java. And just want to call this out, that we are using Project Reactor, so that’s why you’re going to see the .block in this case to make the call synchronous in this example. So if you want to use a asynchronous API via Product Reactor, that’s already built in the API, don’t need to make any adapter to it.
And the Dapr client, you just use the builder, and here you don’t need to pass any argument at all, so only if you’re doing anything different, then you might require to specify a different port, but if you’re using the standard way that Dapr adoption is, you just call the builder.build and you’re good to go. The builder will know what is the port that the sidecar is running because Dapr run injects the environment variables that the builder knows how to parse.
So now we’re going to go through Pub/Sub. In this case, we’re going to publish an event and very similar to save state, the pubs up name, which is the component name, in this case, the topic name, which topic we’re going to publish [inaudible 00:20:22] and which object that’s going to be serialized into JSON. And then on the subscriber end, we’re going to use now the Spring Boot example here, where we have the add topic annotation, that is a Dapr annotation will tell that this endpoint path should receive events from the order topic via the Pub/Sub that I pass as the Pub/Sub name here. And to have the event, I also received the event as a cloud event. So Dapr uses cloud event abstraction, so you can have annotation and extra attributes to your cloud event, including tracing. So that is why we get tracing, even with Pub/Sub, because we use the cloud event abstraction.
And that’s really cool, the cloud events, to get that standard interface. And if I want to get to, let’s say, the raw underlying event, can I do that too?
Yes, if you want to get the raw event you can. In this case, you get event.data and get the event right away.
Sounds good. Because I think we get a lot of questions like, “Hey, does Dapr hide too much of my object model?” Let’s say.
Yes, there is another way to handle this, if you want, which is let’s say you’re subscribing to a topic in Redis where the publisher does not use Dapr and does not use a cloud event abstraction. In that case, you can configure your subscription to say I’m subscribing to raw events, and then the double sidecar will automatically wrap that to a cloud event that should be compatible with the Dapr subscription. So you can subscribe to even events that, from publishers that are not using Dapr. So that goes back to what initially introduced, where you say you can incrementally adopt, so you don’t need the whole company to adopt Dapr. For example, for Pub/Sub, you can say, “Okay, I going to subscribe with Dapr, even though my publisher, which it is auditing does not use Dapr.
That’s awesome. It sounds like it makes my API more a bit standard too in the process.
Yes, yes, and now we can go to service invocation. Service invocation, there are two ways of doing that. One way is you can use the invoke service API in the SDK, which is for HTTP, and then you can pass the application ID, the checkout or the path, the full path, and the update you’re passing and the HTTP method you’re using. Now you might argue, “So what’s the advantage of using that over standard HTP call?” And I would say the advantage is that your application does not have to configure at the endpoint for the service. So as you can see, I don’t know what host the card service is, and I don’t need to know, the service discovery feature of Dapr will handle that for me.
Now, if you want to use without the SDK, you can say, “Oh, I’m already doing, they should be called correctly to my service, why should I even bother choose the Java SDK, just to make HTP call?” It’s a good argument, and for that reason we created a proxy solution for HTP invocation and JRPC as well, where existing code that makes a service invocation does not need to change, except from an extra header in the endpoint. So the endpoint you pass the same way, you were passing to your service, but you call local host in the port of the Dapr runtime. In this case, we’re going to use the standard 3,500, but it can be configurable, you can get this from the environment variable as well, if you want, and then you pass the header, Dapr app ID.
[inaudible 00:24:24], so what’s going to do is, that part going to behave like a HTP proxy now, Dapr going to receive the request, you’re going to understand that, “Oh, this request is not actually for the sidecar.” This actual request now has to be forwarded to this other application by type ID card. And it’s going to do the translation and make HB call on your behalf and forward it back to you, the response. So there’s very minimal change that you need to do in your code to make your service invocation with Dapr, and don’t require even to use the SDK.
Just to add to that, we’re seeing, I think, a number of developers who are starting to use this approach because they have HTP, they have gRPC and proto code already, and so they could start using Dapr by adding the header, like you showed, which is a perfectly good approach, right? And then, if I want to write succinct code for brand new code, I have the other SDK approach. So you have good options either way.
Yes, that is correct. And if we go next, so how do we do the same thing that we did using Kubernetes? And do I need to rewrite my application, use Kubernetes? And the answer is no. Your application works with the same code, the same bits. You can run locally, or you can run a Kubernetes, and we’re going to show how. So same example, but everything on Kubernetes. Okay, so let’s get the pods. So Dapr installed in the Dapr system name space, as you can see the dashboard, the operator, placement, sanctuary and sidecar. We also have the Redis installation in the default name space, and we also then have the components, the binding, the pressor and the Pub/Sub component. So if you can look at the binding, we’re going to see that we use the secret reference here. So again, no hardcoded secrets, it’s all part of the Kubernetes secret store.
If you look at processor, sorry, I made a mistake here as it was typing, you can see that we also use a secret store. Sorry, in this case it was just the deployment. Sorry, it was the deployment. Now we have the deployment for the provider and you can notice that they all have the annotation, the Dapr annotations. That would tell the Dapr sidecar injector that you need to inject a sidecar, so none of the deployments you have to declare the Dapr sidecar, that gets automatically injected after you add the annotation, and the [inaudible 00:27:18] component also using Redis.
Now let’s look at the viewer deployment, same annotations for Dapr, and I have to call out the app ID is also specified. And in this case, we also have a service so we can have an ingress. Okay, so we’re going to simply apply all these MLs, and if you look at the pods, we now have the pods being created. And now look like it has two containers, see? Even though we only should find one for the application, now it has two because the sidecar injector detected the annotation and say, “Okay, let me inject now the dapr sidecar into this spot.” Now they’re all running.
Now let’s look at the logs. Let’s start with the processor. Oops, I forgot to, for the name, okay. Okay, parser has started. Oops, I think I need to copy SOL, the whole provider URL, give a second, let me fix that, klogs, provider, okay. Wow, okay, we get a tweet. Some of it is in Portuguese, I can tell.
It’s always thrilling to have real live Twitter coming into a demo.
Yes. Okay, and now we are going to get the endpoint for the viewer. We’re using minikube in this example, so let’s use the minikube IP.
But this could run on any Kubernetes, right?
Yes, it could run on any Kubernetes with a public IP as well. And then we start getting the tweets as well. Okay, so that was the demo on Kubernetes.
Let’s dive deep into each component for us here understand how the code looks like. So here we see the Twitter components, for the binding component for Twitter. So none of the secret is hardcoded. We use the secret reference here, that goes to Kubernetes directly. And if you’re running local host, you will fetch from a local file. So you don’t need to worry about, “Oh, where the secret is coming from.” That’s another configuration just for that. You also have the message buzz component, which we use Redis in this example, and we just using local host here with empty password, but if you want to do this in production, you can just replace this YAML with one that is a secret as well, and your code has no change. Same thing for state store, we have Redis using local host, and if we’re in a secret store, you can have the secret store, in this case, define it from local host in adjacent file. So you don’t necessarily need to use Redis secret store for when you’re running locally, of course, you’re going to use this file.
So when you get a tweet, remember you receive a tweet from the binding, and I just pass a tweet object here, and it’s automatically de-serialized for me by Spring, and when I do Dapr client revoke service, I will revoke the sentiment processor with the sentiment path, passing the tweet object, using post and receive back the sentiment object, and then I do some Reactor through here, and then I translate and take the response, save state, use the state store, pass the tweet ID and analyze tweet, and after that I published the event message bus, okay.
I think you can really see here, you had a pretty interesting workflow, but the code looks just like the workflow you want versus more of the machinery that you’d have to do through HTP, your gRPC, just to do the connectivity, so that’s pretty cool.
Yes, yes, so we are using here, the features from Reactor, and the Dapr sidecar is injected. And I can see, I going to show now how I do that. There’s a Dapr config and I have a builder and I send a client back to, via autowire, okay?
And the application, in case of a Spring Boot application, all the difference is that you need to add the package path for Dapr’s io.dapr For the Spring Boot, and Dapr automatically loads all the controllers that Dapr needs to work and receive all callback calls and handle the topic annotation for you. So all this goodness happens just by adding your list of scan packages.
Now let’s look at the sentiment processor. Again, the secret store. And in this case, we get the endpoint and the subscription key from the controller, and then we make the HP call. We receive the sentiment like it was saying, via HTP, and then we make HP call to Azure Cognitive Services. And then we get the response back, we return the sentiment object back to the user. So if you look at this code, there’s actually nothing here that is specific to Dapr.
And that is one way that you can see how service vocation with Dapr works. You don’t need to rewrite the receiving end, so it still works as this, but in this case, we are using the secret feature for Dapr. So remember, you need the endpoint secret and need the subscription key secret, so all of that is coming from the Dapr get secret API. So you don’t need to hardcode any secret in your environment variables. You just let Dapr get the secret for you. So that was how this application is adopting Dapr, is for the secret store.
And quick question from an ops perspective, so we’re showing the developer local machine, but if I have more environments, let’s say I’m in a CI/CD pipeline, I have staging, pre-prod, all the way to prod, what would this look like?
The difference for you will be that the secret store file will be different, or if you’re going to Kubernetes, you’re going to put the secrets on Kubernetes with different values. So this way, the application work with different configurations, with no code change. So all of the secret store component will need to be changed.
And if I use something like Vault or Key Vault, could I use those too?
Yes, you could use Vault as well. I use Vault instead of using Kubernetes secrets. You can also do that too. So, and all that is handled within the YAML of the component. Great question.
And now let’s go the tweet viewer, the tweet viewer uses the subscription feature, where it has a topic. So we have the special notation that is a part of the Dapr SDK for Spring Boot, and you got to subscribe to the tweets, receive the message name, the Pub/Sub name, go to his message bus, the same one as you see in the YAML on your left. In this example, is going to come from Redis or local host, but it can come from other sources as well. And the same strategy of replacing the component YAML, if you want to run in a different environment also applies here.
We also have a web socket, but I keep that abstracted because it’s not Dapr specific logic, and we also receive… In this example, we have a different way to handle the cloud event. We receive the cloud event as bytes, and we de-serialize in the code, that’s another way that you can do that as well. We can receive directly, already parsed, or you can call the additional de-serialized method of the cloud event object that we provide, sorry, cloud event class that we provide in the Dapr SDK. And these days, also important to call out that we use SLF4J, not Log4j, so there was just a good example, given the times.
And now let’s use RabbitMQ. So if you like to use RabbitMQ instead, you change your YAML, and nothing else. So let’s say, in local host, you use Redis and in your test environment, use RabbitMQ, no problem. You just have a different YAML for your different environment, and again, this makes the DevOps life easier, because you don’t need to also have developers who mimic your environment a hundred percent locally.
It sounds like the, again, the sidecar is doing a lot of the heavy lifting, like you mentioned to different frameworks and things, so even if something need to be patched, something need to be updated, sounds like the Dapr team’s going to take care of that and keep updating the sidecar.
That is another great example, too. The RabbitMQ component is evolving, so in the next release of Dapr sidecar, there are already fixes for RabbitMQ component in Dapr. You get those for free, so you don’t need to worry about do I need to update my dependency? Am I [inaudible 00:37:51] the latest? Is this ready for production use? All of that is handled by Dapr, and you actually can see which components are considered stable for production use, which ones are not yet, and we are working on evolving more and more of those into stable version. And another thing is that, when you’re using the sidecar pattern, you don’t have to manage dependency conflict in your application. So let’s say you’re bringing in a third party library connection, RabbitMQ, and that’s using a conflicting version of one of you dependencies. Let’s say your JSON serializer, let’s say is a conflicting version of that. You don’t need to worry with dependency conflicts anymore because all of that is isolated in a separate process.
Okay, so let’s look at Zipkin. So we opened the URL, local host 9 4 11, and we’re going to our inquiry to see the events from Dapr. And if you look at, let’s say, the provider, you can see how much it took for the tweet event should take place. And in this case, you can take look at the sentiment analysis, how long it took. If you do a show, you can see it took about 1.5 seconds, and most of it was about in the sentiment processor call.
If you go back, we can look also at the publish event, and you can see here how the provider, once the payload was already serialized after the sentiment analysis, the publish event took about 1.3, 1.4 milliseconds. And then later on, as you can see, there’s a small delay, it was the viewer received that in 1.6 and process that in 1.6 milliseconds, and all this is done automatic for you by Dapr sidecar.
Now, if you want to have a great a context on these events, you can, of course, instrument your application, let’s say with the open telemetry SDK, and then that would wrap all this trace events within a parent span, and that context has to come from an application. But again, Dapr will add those events as child events for you, and in this case, Dapr handled that automatically for you, for the Pub/Sub, how the subscriber event is a child of the publisher event.
So now if you want to get started with Dapr, look at our documentation. You can see quick starts, getting started guides, trouble shooting, and examples of how choose components. Take a look at our GitHub page, you might be able to get started by look at your issues, or we want to do a good first issue there as well. If you are Java a developer, take a look at our Java SDK [inaudible 00:41:00], there are many opportunities for contributions to the SDK. You can even evolve to become a maintainer as well, if you want to put on the commitment, you can also look at this example while you’re looking at aka.ms/dapr-java-example, and our community is very active on Discord, so please check our Discord channel, and we also have a community repository where you can find the community call URLs and the schedule. So you’re free to join our community calls as well, that usually is a good place also for you to have a live question answered by one of the maintainers, and of course, our tweet account, Twitter account, daprdev. Paul, would like you add anything?
No, I love the point you make. I think the community’s one of the greatest assets, I think, for Dapr, one of the biggest features, so love to join you there and really keep in mind a lot of Dapr’s actually built by the community too, so that’s been a really neat thing so far.
Yes, a lot of the components actually came from the community or came from demands for the community for legits and errors, also, the community does a really good job reporting bugs, so it’s a very critical path for us to make things as stable, is they actually reporting bugs and the community does an outstanding job doing that too.
Oh, and that just reminds me too, I think one testament of things going well, growing the communities, is we just joined the CNCF as an incubator, and so that’s pretty exciting, and hopefully we’ll have even the next notch of community join us after that.
Yep, that is true. There was a great accomplishment by the Dapr team and also the community.
Yep.
Okay, thanks everyone, and…
Thank you.
Hope to see you around.



