

Our Solution for Scalable Multi-Region SaaS Deployment
From one instance to a global network: Distribution, Promotion and Deployment to SaaS
 Just like many other production DevOps engineering teams, our JFrog team deploys new version releases several times a day to AWS, Azure and GCP, across more than 20 cloud regions. This process used to take us many hours and could have even failed if it was done alongside maintenance by other teams.
Just like many other production DevOps engineering teams, our JFrog team deploys new version releases several times a day to AWS, Azure and GCP, across more than 20 cloud regions. This process used to take us many hours and could have even failed if it was done alongside maintenance by other teams.
As part of our ongoing cloud improvements in 2021, we decided to change our single-instance setup we use to handle cloud deployment in our own SaaS environment, which means SaaS deployment of software releases of any kind to end users. We wanted to distribute our software from one main site across a large scale of regions, which would require heavy automation and use a full proof, tested, scalable infrastructure.
We decided to “eat our own dog food” and upscale our single-instance JFrog Artifactory to multi-instance JFrog Platform and also set up Distribution Edges.
Our Use Case
In the past, we enjoyed the many benefits of working with one JFrog Artifactory instance as our private Docker and Helm registry in the production environment. It allowed us to store, share and deploy our binary artifacts from one single source of truth to any JFrog cloud region.
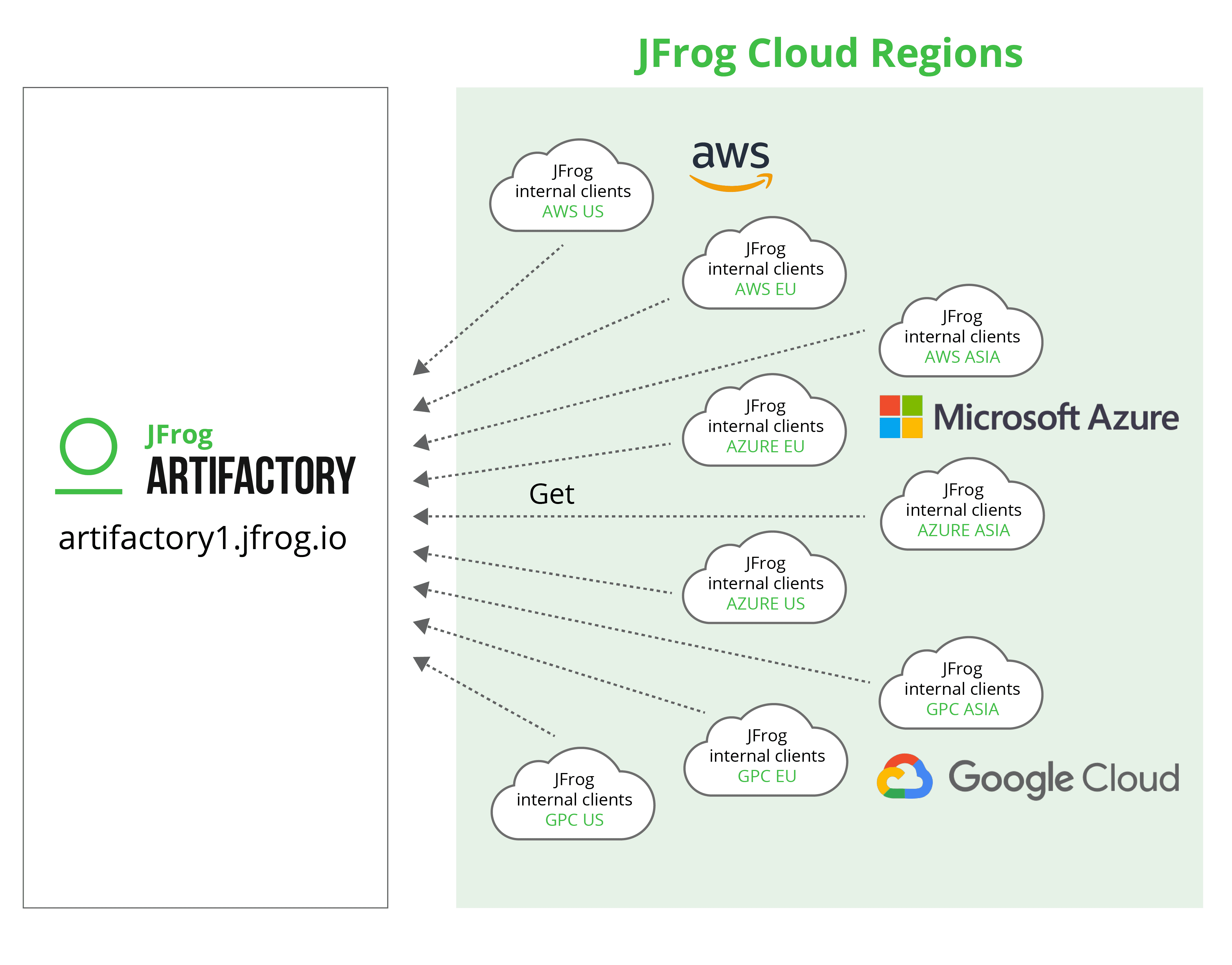 Single-point-of-failure for multiple production regions
Single-point-of-failure for multiple production regions
The biggest advantage of this single-instance approach is in its simplicity. But, it’s not scalable. The single-instance setup may be the most efficient option for low demand environments, and is relatively simple to configure, but when it serves both static and dynamic content with the same configuration, the demand grows and it becomes inefficient. Also, using one instance poses a potential risk because it could lead to a situation in which just one malfunction or fault causes the whole system to stop working.
Moreover, In the past, software used to be delivered in versions, which were released weeks/months apart. Whenever a new version was released, the operation teams had to manually update the software. All that has now changed.
The Solution
The JFrog Platform enables the seamless and secure flow of our software releases from the developer code and all the way to production.
Our configuration is multi-cloud and deployed with HA redundant network architecture. This means that there is no single-point-of-failure, and our internal system can continue to operate as long as at least one of the Artifactory Edge nodes are operational. This maximizes our uptime to up to “five nines” availability.
JFrog Cloud currently processes millions of downloads from our cloud Artifactory Edges to our production runtime clusters. Nothing is delivered from the internet or other JFrog servers.
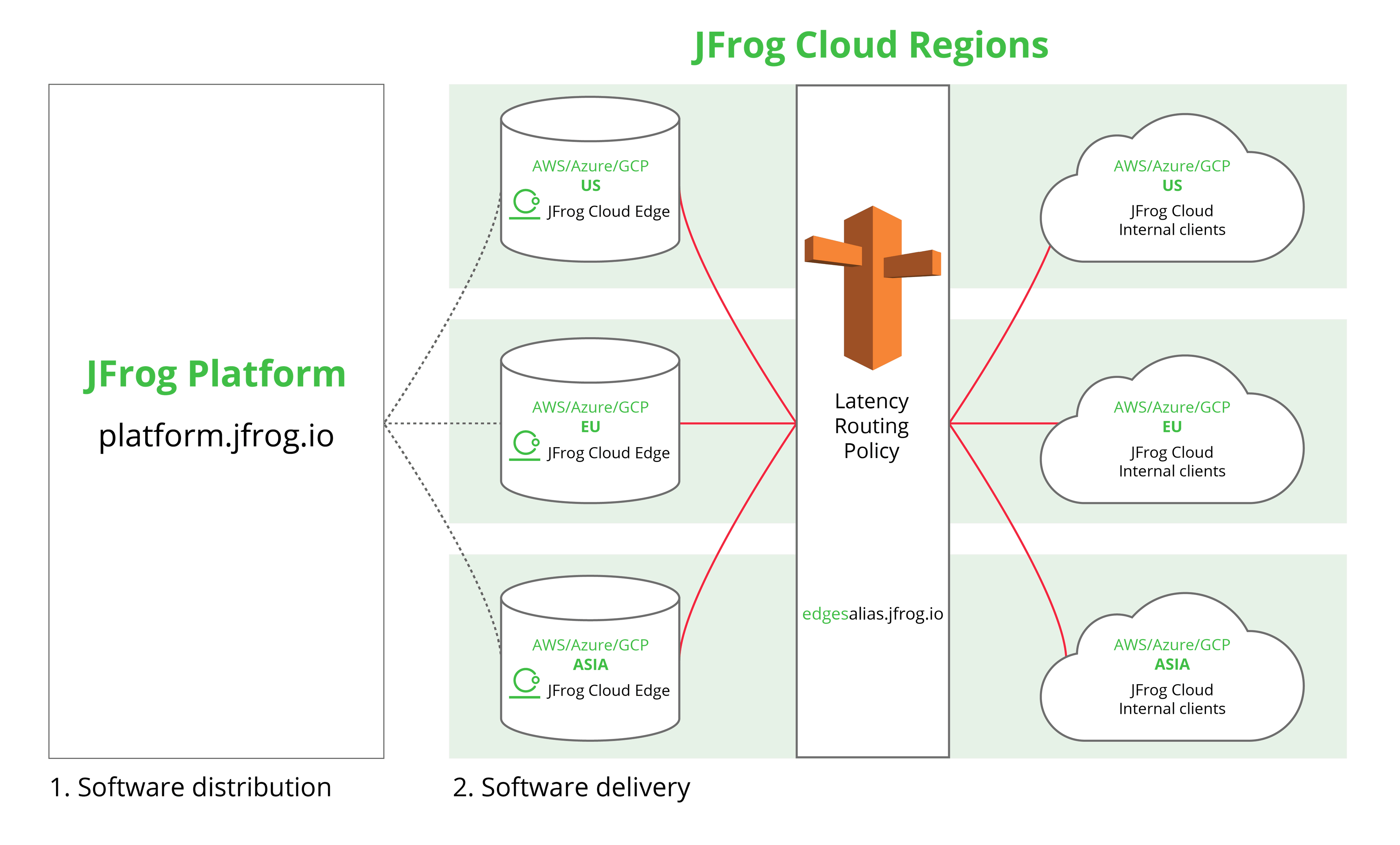 Multi-instance approach for multiple production regions
Multi-instance approach for multiple production regions
Our daily workflow: Dev2Cloud production flow
We implemented strict forward controls about how we are delivering new versions to cloud production internally. Here are two examples:
- Only the RnD delivery group deploys and promotes versions via the related product CI job to edges and cloud staging.
- Only the Production delivery group promotes or demotes versions via a CI job to cloud production. Promoting a version which is not deployed into the edges, will fail by design.
1. Software distribution – RnD delivery group
Today, all of our delivery teams know how to promote their releases into Artifactory Edges using trusted, immutable Release Bundles. This includes our own in-house official JFrog Platform releases and chart dependencies, as well as external third party dependencies.
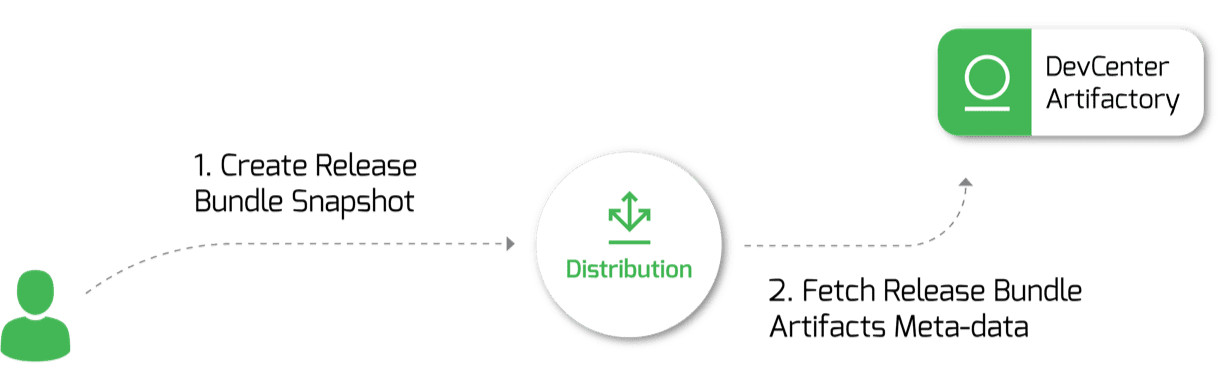
Packages hosted in a JFrog Artifactory Edge node are part of a Release Bundle which is a secure and immutable collection of software packages.
Learn More >
2. Software delivery – Production delivery group
JFrog Distribution enables us to speed up deployments and concurrent downloads at scale and support high-concurrency downloads and verified consumption.
We developed an in-house deployer service (see the JFrog internal clients in the diagram in the solution section above) which is responsible for E2E Cloud provisioning, deployments and maintenance. It fetches release bundles from the DevCenter that contain Helm charts and Docker images (which are essentially what deploys our workloads).
Infinitely Scalable – Network Acceleration and Resiliency
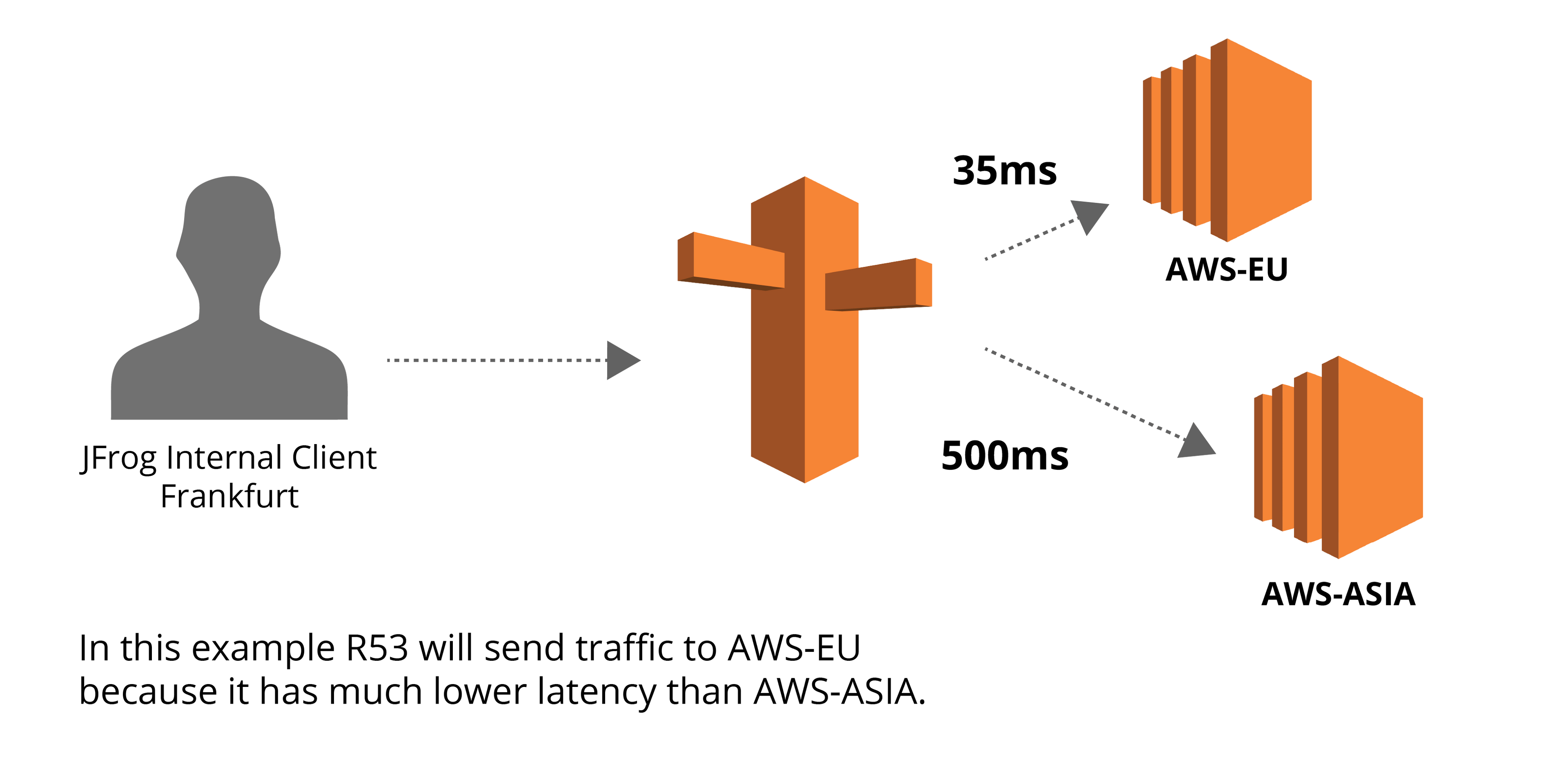
Releasing software updates rapidly across massive infrastructure footprints, users or download spikes, requires a DNS solution. Our team is heavily invested in ensuring a scalable HA solution, to improve network utilization and resiliency at scale. After exploring a few different options for our DNS solution, we decided to use an AWS R53 for our latency routing policy (our DNS solution).
For our use case, we have a collection of software release bundles (Docker images and Helm Charts) available for clients, in different regions, to download from one of the available Artifactory Cloud Edges through a single endpoint (Latency Routing Policy).
Latency based records is the best option since it allows routing traffic to the edge with the best latency and less round-trip time, by applying associated health checks. Using AWS R53 agnostically, allows us to gain the advantage of using an ALIAS record which decreases the time to final answer resolution, as the authoritative servers traverse the DNS hierarchy and retrieve the final answer much faster.
Outcome
After almost a year of running in production, we can see tremendous improvements with our cloud deployments. Utilizing the JFrog Platform, we were able to improve deployment speed, governance and network utilization when releasing updates across large-scale, agnostic infrastructure to any cloud server.
Create a free JFrog Academy account and start learning today!
Closing
Our experience with the multi-instance approach has been very positive, so-if you’re willing to do some extra initial configuration, we recommend going with multi-instance right from the start.
Special thanks to everyone that contributed to the design and implementation of the distributed cloud solution. Special thanks to Eran Nissan, Eldad Assis, Matan Katz, Asaf Federman, Ronny Niv. as well as some of the folks from AWS. Additional thanks to the rest of our CTO, Cloud Production and DevOps teams for their support and help with JFrog Distributed* Cloud features, processes, and design decisions!
Stay tuned for more interesting updates from our team as we continue to create additional advanced features for JFrog Cloud.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



