

Supporting Next-Level Enterprise Scale in Software Development

By
6 min read
What it means to be “enterprise grade” has changed.
In software development, the size of new artifacts and the pace of development has increased dramatically. Developers are now releasing new components daily, if not multiple times a day. With containerization, and now AI/ML models, new pieces of software can be multiple GBs or larger.
In addition to the size and frequency of software releases, building today’s enterprise-grade software development infrastructure requires the software development lifecycle (SDLC) to stretch across multiple sites. This is done to support blue green deployments, high availability and disaster recovery policies, or to simply facilitate multisite R&D teams where dev may be in one site and QA in another, for example.
This next level of enterprise scale creates two separate, but related challenges for organizations:
- Ensuring artifacts created in one site can be synced to another site quickly and reliably so that appropriate teams and automated workflows can access them
- Ensuring that the system development teams rely on is always accessible and up and running
JFrog has helped the largest organizations in the world tackle both of these challenges, and has taken a big leap forward in our ability to support their needs with new enhancements to our Federation offerings.
Ensuring artifacts created in one DC can be synced to another DC
JFrog has long understood the importance of multisite development and introduced replication between instances of Artifactory early on in its history. In 2021, JFrog launched multisite Federation, allowing for seamless bi-directional synchronization across Artifactory repositories located on different data centers and clouds. Since then, the scale of development has grown even further, with the number and size of repositories as well as the size and quantity of artifacts growing significantly since 2021.
To address this growth, we’ve introduced next-level improvements across Federation speed, size, and resiliency to meet the needs of the most demanding software development organizations.
| Then | Now | |
| Speed of Sync Process | 500 events per minute | Up to 300 events per second |
| Repository Size | Less than 1M artifacts | Up to 100M artifacts |
| Number of Federated Repositories | Less than 1,000 | Up to 5,000 |
To make Federation more resilient, and better able to recover from uncontrolled outside issues like network connectivity, we’ve also introduced Delta Sync and Auto Healing.
Delta Sync replays events only from the last event that was successfully synced. This efficient operation is also a prerequisite to any auto-healing operation.
Auto Healing is the ability to detect an error during sync, maintain a queue of unsynced artifacts, and automatically re-initiate synchronization when connectivity allows. This will result in the reduction of total time federated repositories are out of sync and reduce the level of maintenance required by customers and/or support to bring repositories back in sync.
Ensuring that the system is up and running and accessible
Delivering software fast is a competitive advantage. The need for continuous, uninterrupted operations without data loss is why enterprises care heavily about high availability and disaster recovery.
The good news is that by adopting Federation to make sure artifacts are seamlessly available for consumption across data centers, organizations are already well on their way to ensuring up time and accessibility.
Once two or more Artifactory repositories are syncing, ensuring uninterrupted operations comes down to monitoring and identifying if the instances are up, in sync, and routing traffic to the optimal location.
JFrog’s new self-service DNS routing solution (available for Enterprise+ JFrog Cloud customers via MyJFrog), paired with enhanced Federation monitoring dashboards, makes this easier than ever.
Federation Monitoring Dashboards
JFrog’s new Federation dashboards (arriving in Q2 ‘24) provide organizations with an at-a-glance status of their federated repositories. Users can see the general health of all federations or drill down per federation.
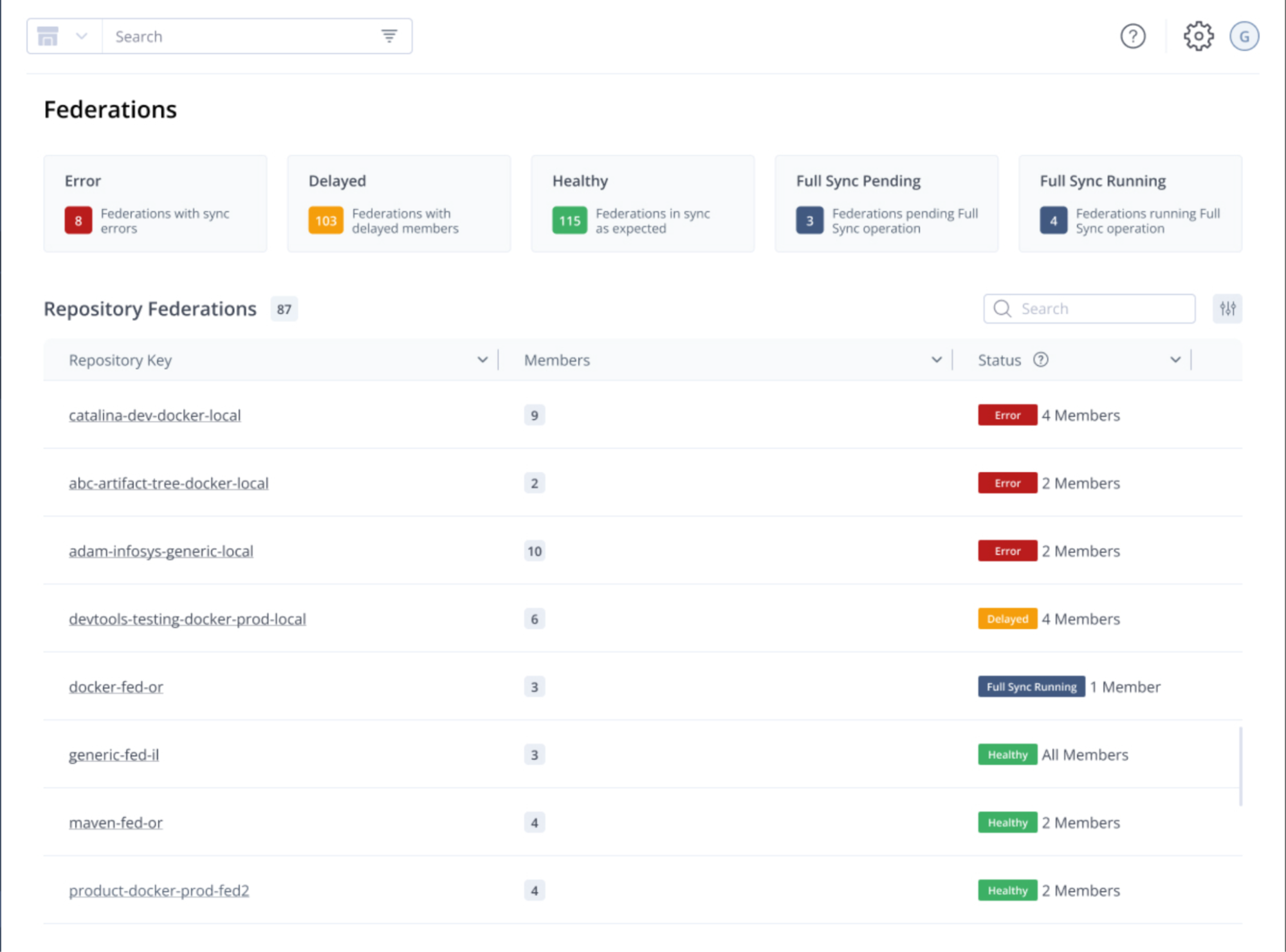 Federation monitoring dashboard in the JFrog Platform
Federation monitoring dashboard in the JFrog Platform
Geolocation DNS Routing
With developers working around the globe, you also want to make sure they’re accessing an instance that’s optimized for their location to reduce lag and latency. Here’s where JFrog’s new Geolocation-based DNS policies come into play. Organizations can customize routing based on location under one routing URL and can support up to 10 federated members per policy.
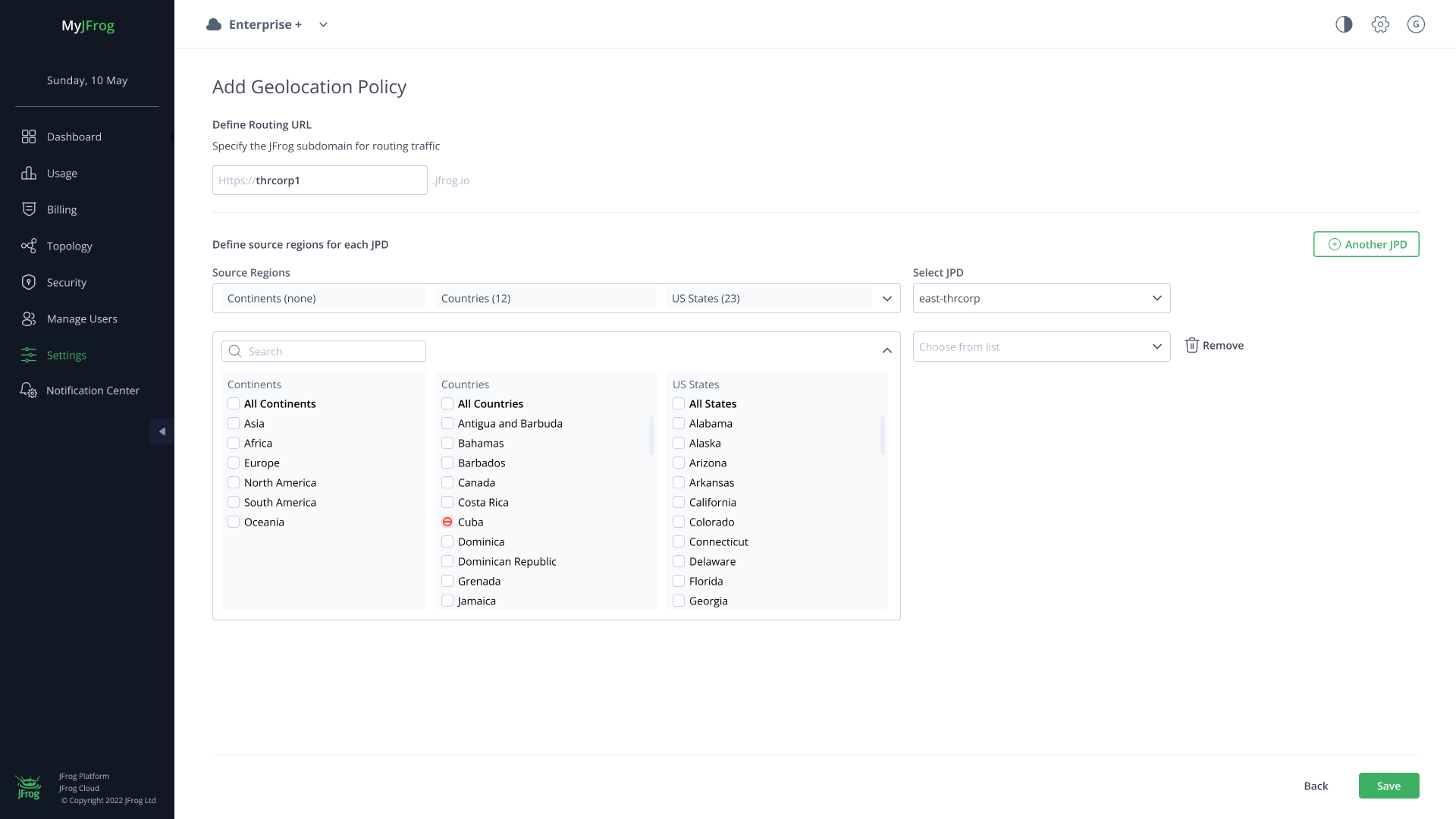
Set and manage geolocation routing policies in MyJFrog
Improving redundancy with Manual Failover
In the event an Artifactory instance is down, organizations need to be able to quickly assess and react as appropriate. JFrog’s new Manual Failover DNS routing policy allows organizations to define one routing URL and reroute traffic from a primary instance to a secondary instance with the click of a button. Automated alerts notify admins if there is an issue and the improved dashboards allow them to assess how best to react. Once the primary instance is up, Federation will bring the two instances back into sync, where traffic can again be routed back to the primary instance with the click of a button.
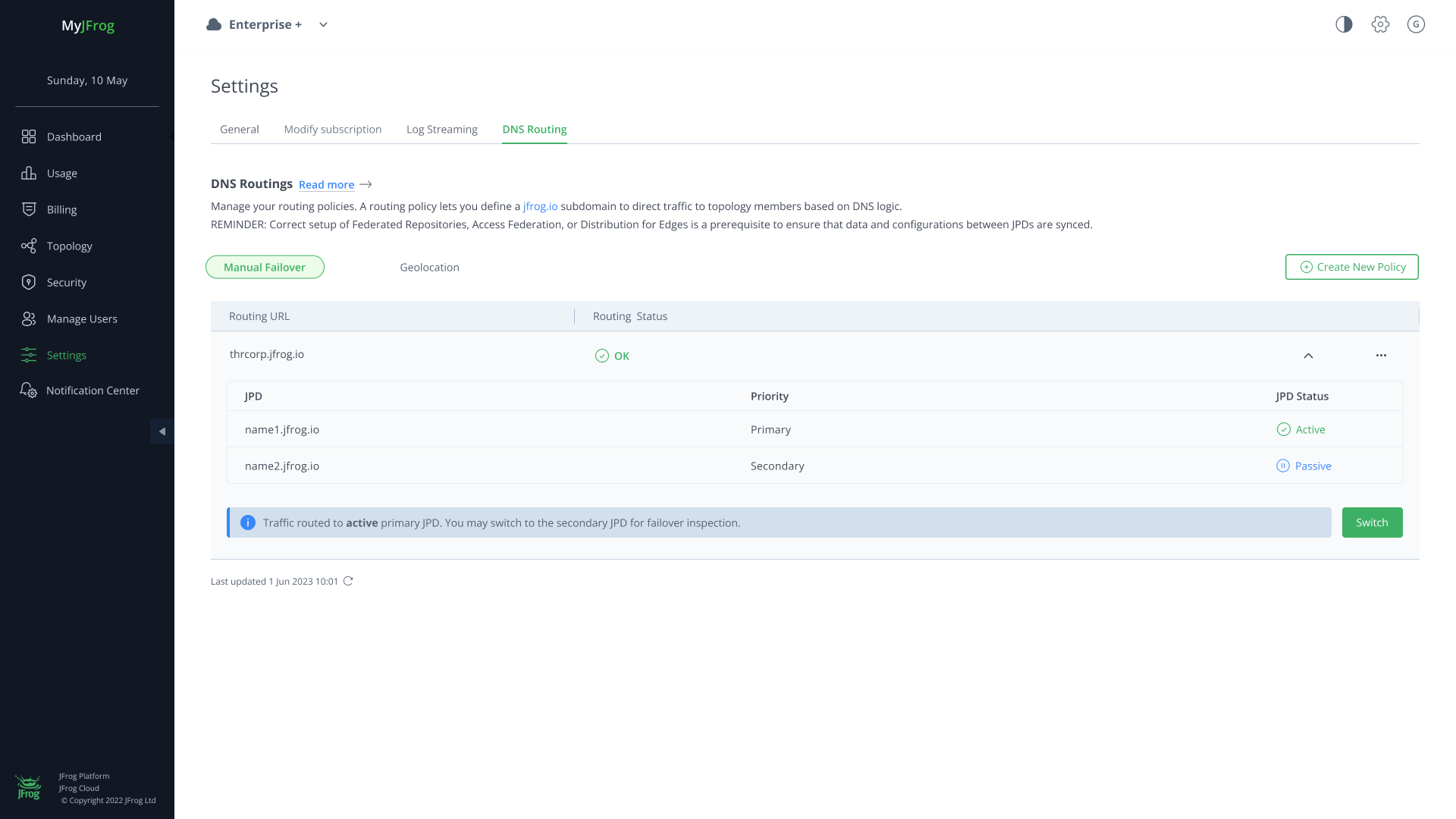 Set and manage failover routing policies in MyJFrog
Set and manage failover routing policies in MyJFrog
Scale to Infinity, and Beyond
The development world has gotten “bigger” and organizations need to make sure their infrastructure and development tooling can keep pace. JFrog is the first and only platform to provide this level of support for global development.
With Federation, organizations of all sizes can easily tackle important use cases such as:
- Serving globally distributed teams and processes
- Resiliency and high availability of development infrastructure
- Improving CI/CD such as when moving from CI server to CD server
Need help tackling your scaling challenges? Speak to a JFrog team member to learn how the world’s largest software organizations benefit from the JFrog Platform.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



