

Part II: A Journey Into the World of An Automated Security Operation Center (SOC)

By
8 min read

Security operation teams continuously aim to focus on two main things: 1. Real cyber security threats (also known as “True Positive Alerts”), and 2. Reducing response time, especially when you have so many different sources to monitor. However, in reality, we deal with hundreds of security alerts on a daily basis, many of which are false positives that waste our valuable time. This is where incident response/security automation becomes a requirement rather than nice to have.
So, who is this blog post for?
- If you spend a lot of time on monotonous investigation steps and processes and find yourself jumping between multiple platforms to get an initial verdict – this is for you. AKA Scaling your triage.
- If you get a lot of alerts which are not informative enough to help you make quick decisions and measure the potential risk – this is for you. AKA Enrichment.
- If your point/person to remediate the risk and suggest actions is in a different timezone and this just increases the resolution and response time – this is for you. AKA Escalation and Respond.
This blog will explain how our Cyber Security Incident Response Team (CSIRT) team designed and chose the incident response automation solution we have today. Hopefully sharing our use case can provide additional guidance for you and your organization. This is the second part of three blog posts, including: Security monitoring (aka SIEM), Automation (aka SOAR) and Bots (aka Chat bots).
First, let’s recap a little bit about our team.
Security Engineering at JFrog
JFrog Security – CSO Office is focused on protecting our customer data, ensuring the security of our cloud infrastructure, providing the highest product & application security standards and responding to emerging security threats. Learn more about Security at JFrog >
The challenge: As a start, let’s face the truth
In most common organizations, the security operation team is probably outnumbered in comparison to the number of alerts that are being received daily.
Let’s take a hypothetical example, where we have 5 people on the team and each one is able to handle a maximum of 7-10 tickets on a daily basis. If each ticket requires 15-20 mins to get an initial verdict, this will add up to approximately a half a day of your team’s work and you still need to handle the remediation steps. But, the reality is that your organization most likely needs to handle many more alerts than this, and one of two scenarios is happening:
- Good case scenario – Your team will run a thorough triage and investigation, but soon will start “caching” alerts and never manage to keep handling everything.
- Bad case scenario – Quality goes down and replaced by the “top priority is closing tickets”.
In both cases your team will probably enter the “alert fatigue” zone, wasting time and motivation.
So how to solve this?
We can narrow it down to 3 options:
- Hire more people – highly impacting budget and operations (recruiting, mentoring, management).
- Handle less alerts – impacting your ability to secure your organization.
- Enable security automation – covering all security alerts without human intervention aka using Bots 🙂
Let’s deep dive into how we created our automated security alert solution using a Slack chatbot.
Preparation, Staying Focused
Without planning, you will be lost.

We started by manually investigating each of our security incident types and built a dedicated playbook for each (investigation process and response plan). This helped us achieve data accuracy in our security automation integration types (e.g. AWS / Gsuite / Slack / etc.) and playbook actions.
Next, we checked our alerts metrics and statistics in our Security Operation Center (SOC) and identified the most noisy alerts (not necessarily critical) which had to be the first candidates to automate.
Finally, we chose the most efficient and accessible communication channel for our organization (Slack) enabling the most reach, reducing the response time and engaging the relevant stakeholder.
* Important note: Start with the security alerts that are the most time consuming to allow your team to spend more time on critical alerts.
The Technology Matters, Choose Wisely
Here are 4 guidelines we used for choosing the technology for our security/incident response automation:
- Identifying the right platforms
We focused on designing our Incident Response (IR) automation playbooks rather than developing new platform integrations. We made sure that any additional customizations were straightforward and simple to implement. - Error handling
Thinking a step ahead, playbooks are like micro services which together function as a complete system. We relied on automated investigation and response processes that functioned as needed, enabling us to monitor errors in real time. - Team collaboration
We realized that sharing knowledge between team members is priceless. Security threats happen repeatedly. We identified their patterns and the Indicator of Compromise (IOC), enabling us to take advanced response actions.
Very much like the RnD team, developing together is key to success – you don’t want to be a focal point or a bottleneck to the playbooks you developed. You will need version control and separated environments for development and production. - Incident management platform
We wanted a single incident management platform that includes features such as: incident type, incident layout, incident owner, incident duration, incident dashboard were very important to us.
Developing our automation playbook
Step 1: Investigation – Scaling up our triage
Dealing with uninformative alerts means having a lot of open questions, and all these repetitive tasks to answer them are a waste of time causing two (bad) effects: erosion of the analyst and buying more time for the attackers.
We developed an automated process that investigates and enriches the raw-data log in less than 5 mins and delivers it directly to the Slack alert channel. This minimized our triage time to get an initial verdict in an accessible communication channel. We can see the difference between the raw-data log and the enriched bot alert.
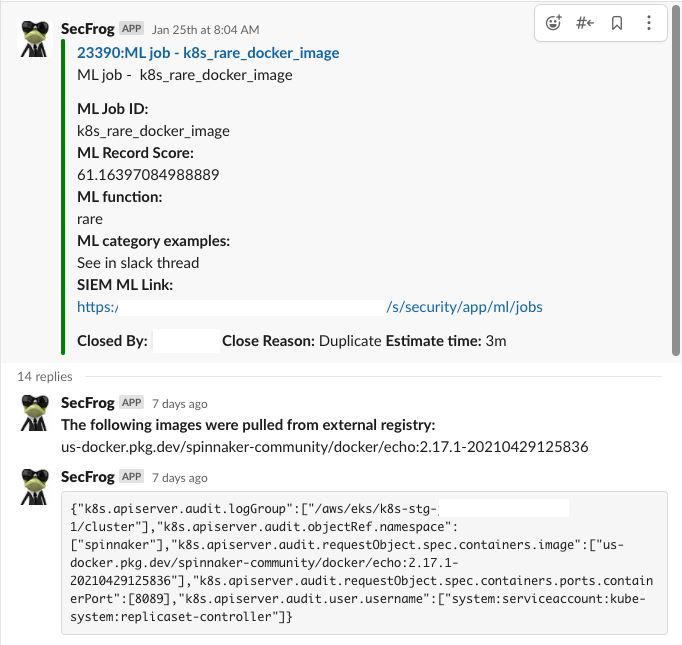
Step 2: Incident status – Reducing false positives and starting to make decisions
Understanding that our time is very valuable, we decided to spend it only on “true positive” cyber security threats. We did not want to deal with threats which do not exist anymore or even did not exist from the start.
We automated this process completely by answering questions and building branches for each decision we needed to make in order to conclude if it’s a false positive or not.
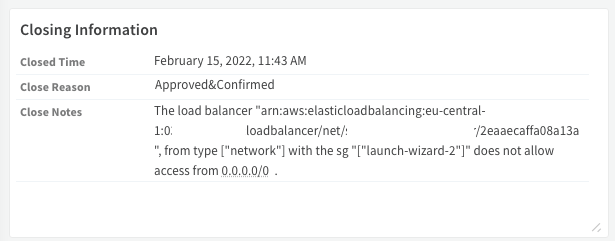
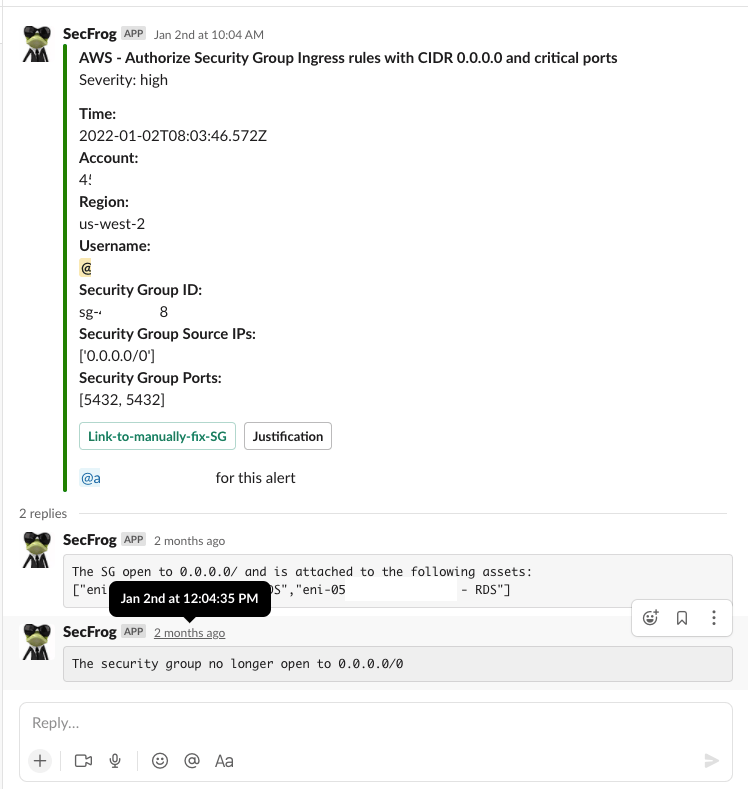
Step 3: Escalation – It’s all about the timing!
By sending informative and interactive alerts directly to a shared Slack channel, we were able to make our users (in our case other teams in the organization) the incident owners. The alerts include all relevant details and conclusions that arise from the automated investigation step above, helping the incident owners respond independently and quickly.
By sending our incident details directly to the owner we decreased the risk lifetime (reaching a 2 hour remediation SLA).
By doing this, we also accomplished employee awareness! We increased employee awareness of cyber security threats. Real time alerts helped connect the dots between what they recently did and the security issue that was raised.
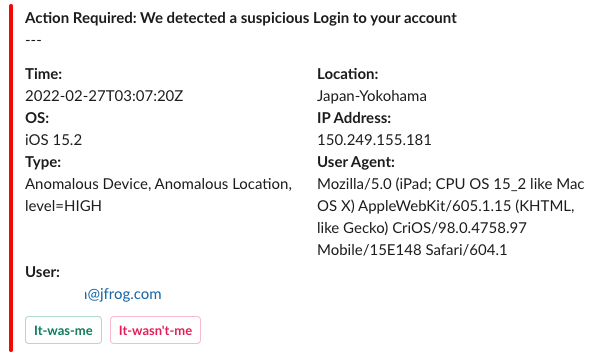
Step 4: Automated remediation – Without hesitation
Finally, we built automatic remediation steps for our users, based on their response input. In other words, users will get the automatic alert, respond to it, and trigger an automated remediation action from the system.
In essence, attackers lose their advantage.
Final Architecture
To sum up, here’s our final automation architecture, combined with our previous security monitoring solution architecture and our IR automation architecture, creating an end-to-end automated SOC.
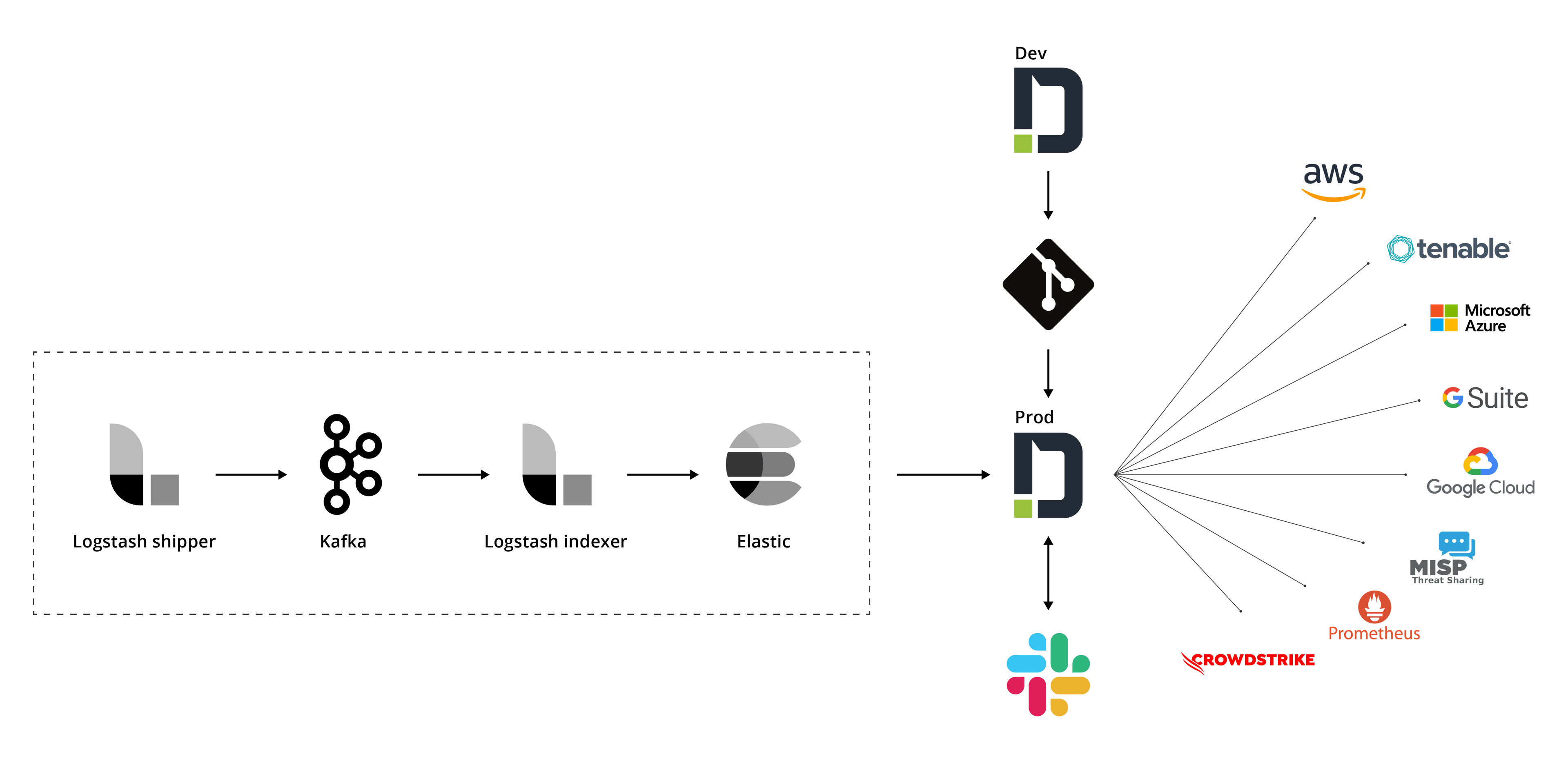
Hopefully our journey will help other teams rethink their automated SOC infrastructure.
Reach out, ask questions, share your thoughts, concerns and ideas over LinkedIn.
We’re hiring, check out the open positions >
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



