

Evolving ML Model Versioning
ML Model Management with JFrog is now Generally Available


By
9 min read
TL;DR: JFrog’s ML Model Management capabilities, which help bridge the gap between AI/ML model development and DevSecOps, are now Generally Available and come with a new approach to versioning models that benefit Data Scientists and DevOps Engineers alike.
Model versioning can be a frustrating process with many considerations when taking models from Data Science to Production. Now with ML Model Management from JFrog, you can make sure the right version is being used at the right place and the right time, while also ensuring that it’s secure.
Taking AI/ML models to production — similarities and differences with “traditional” software
In some ways there are clear parallels between traditional software development and creating ML models. For instance:
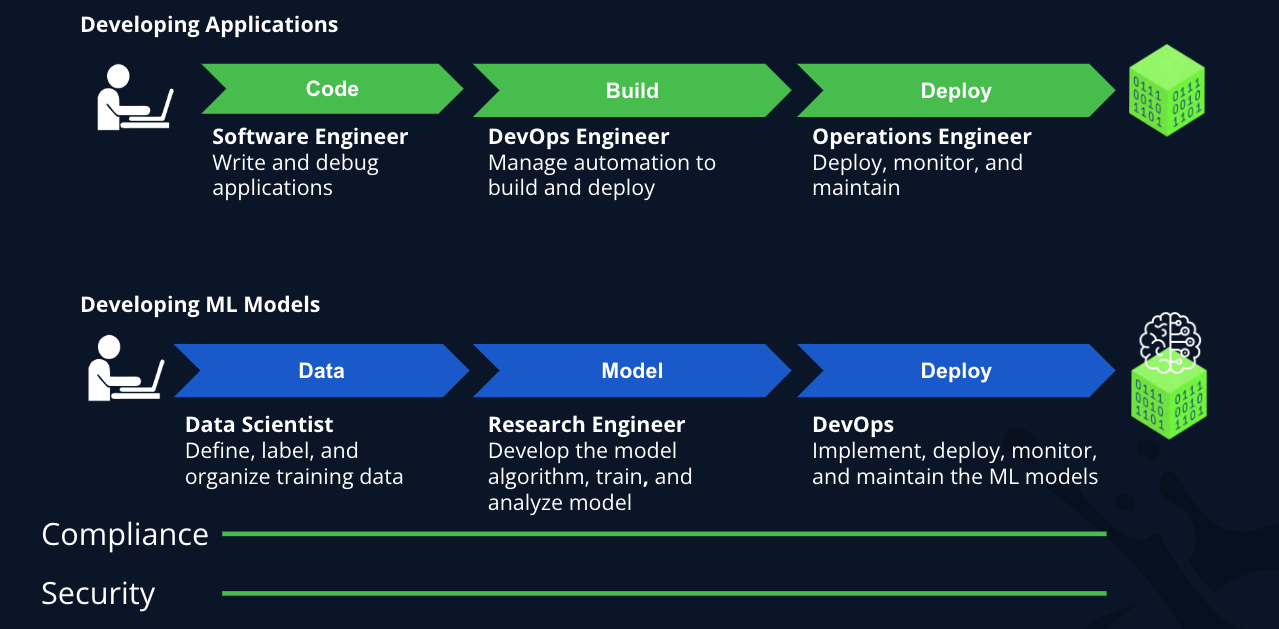
- When creating applications, a software engineer writes and debugs code. That code then goes through a build and test process, typically managed by a DevOps Team, and if all goes well, it’s then deployed. The flow can be simplified as Code > Build > Deploy.
- In ML model development, a Data Scientist (potentially aided by a Research Engineer) defines, labels, and organizes training data, builds model algorithms, and writes supporting scripts. The “raw” model is trained, refined, and analyzed until a sufficiently performing model is generated. Lastly, the model is deployed for use in the “real world” where its performance is monitored. This flow can roughly be grouped into Data > Model > Deploy.
For both processes, compliance and security are constant threads which must be considered and incorporated along the way.
But when you start to dig down into the actual processes, you’ll quickly uncover the additional layers of complexity in ML development that aren’t present in traditional development. For example:
- In traditional development, the build phase produces one coherent, reproducible piece of software that’s reproducible if built in the same way.
- In ML development, teams will run concurrent training streams with different parameters, tweaked data sets, and other modified criteria to yield a trained model. Then, there’s a validation process to determine which models perform as intended after training. It’s not uncommon that after the “Model” phase, an organization will end up with multiple models that are either candidates for release or need to go back for further training.
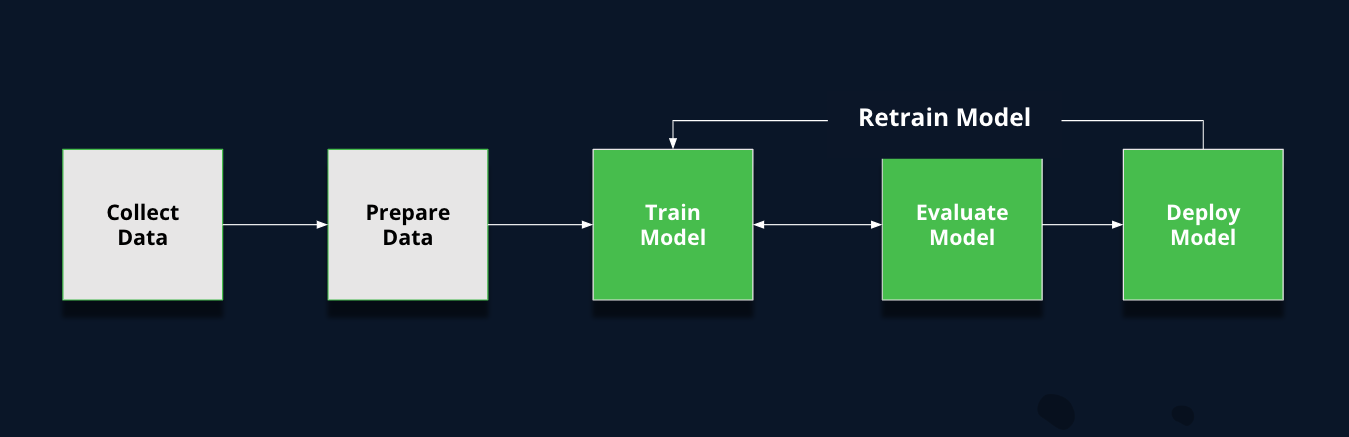
As you can see, there are many different permutations that can occur when creating a new model. These added layers of complexity are typically why organizations face challenges applying traditional software development tools and processes to ML development.
Challenges with ML model versioning approaches today
Versioning ML models is a challenge for a number of reasons:
- There are multiple points in the model development process where you might want to create a new “version” of the model or go back and rework a specific model version.
- The process of creating a model typically results in multiple outputs at the same time (as we mentioned above).
- The “build process” is a bunch of training processes with different parameters (i.e. data, algorithm, hyperparameters, features, etc.).
- Different experiment management systems (homegrown and commercial) have different approaches to “versioning”, with some using sequential numbers and others using suffixes.
Furthermore, different stakeholders struggle to understand what constitutes a new version, the status of a model, and (for DevOps teams in particular) which model is ready for consumption. This can lead to inefficiencies that slow down critical ML processes.
The problem with Git-based approaches
In addition to the challenges listed above, it’s important to call out a less obvious issue: Git-based approaches to ML model versioning. Today, many ML teams rely on Git-based approaches. Unfortunately, Git-based solutions fall flat for a few reasons rooted in Git semantics, trouble handling large binary files, and a lack of metadata — all of which compound as more individuals collaborate on the model development process.
Often, with Git approaches, Data Scientists and Engineers just stack commits on the Main branch with the HEAD tag always on the latest commit in the branch. Stakeholders can see previous commits, but there’s no easy way to know what they’re getting with each commit since the name is just a set of random characters. Other ML versioning tools similarly use random identifiers. And using S3 buckets or other generic storage options leaves Data Scientists to name each upload themselves, which often leads to naming inconsistencies, the File_Name_Final_Final_Final conundrum, and even missing files.
At JFrog, we felt it was best to go with name and timestamp-based versioning and are excited to provide all the benefits of a very advanced file system without the hassle of having to do it yourself. Continue reading to see how ML model versioning is simplified with JFrog.
Simplifying model versioning and managing them with JFrog
As we mentioned in our Beta launch blog, our current ML model repositories were built to work with Hugging Face as our “package type”. That means we natively support their APIs and similarly support unstructured models (basically, you can just put everything related to your model in a folder and upload it to Artifactory).
ML model versioning with JFrog classifies model versions under two categories: “experimental” and “release”. You can push any model into a Hugging Face Local Repository and it’ll create a folder based on the identifier you provided via the Hugging Face API (i.e. revision = “main”). This is considered your working or “experimental” version of your model. As long as the “revision” field stays the same (i.e. main), each subsequent upload will create a new version of that model with an updated timestamp under the appropriate folder. This allows Data Science teams to push intermediate work into Artifactory and know which version of the model was created at any given time.
When a version of the model is potentially ready for release, or you just want to easily go back to a specific version, a “release version” can be created by updating the “revision” field from “main” to something else (i.e. “This_is_a_good_version”), which will create a new folder. For release versions we only keep one time stamped version at a time. It’s a similar concept to a Java snapshot.
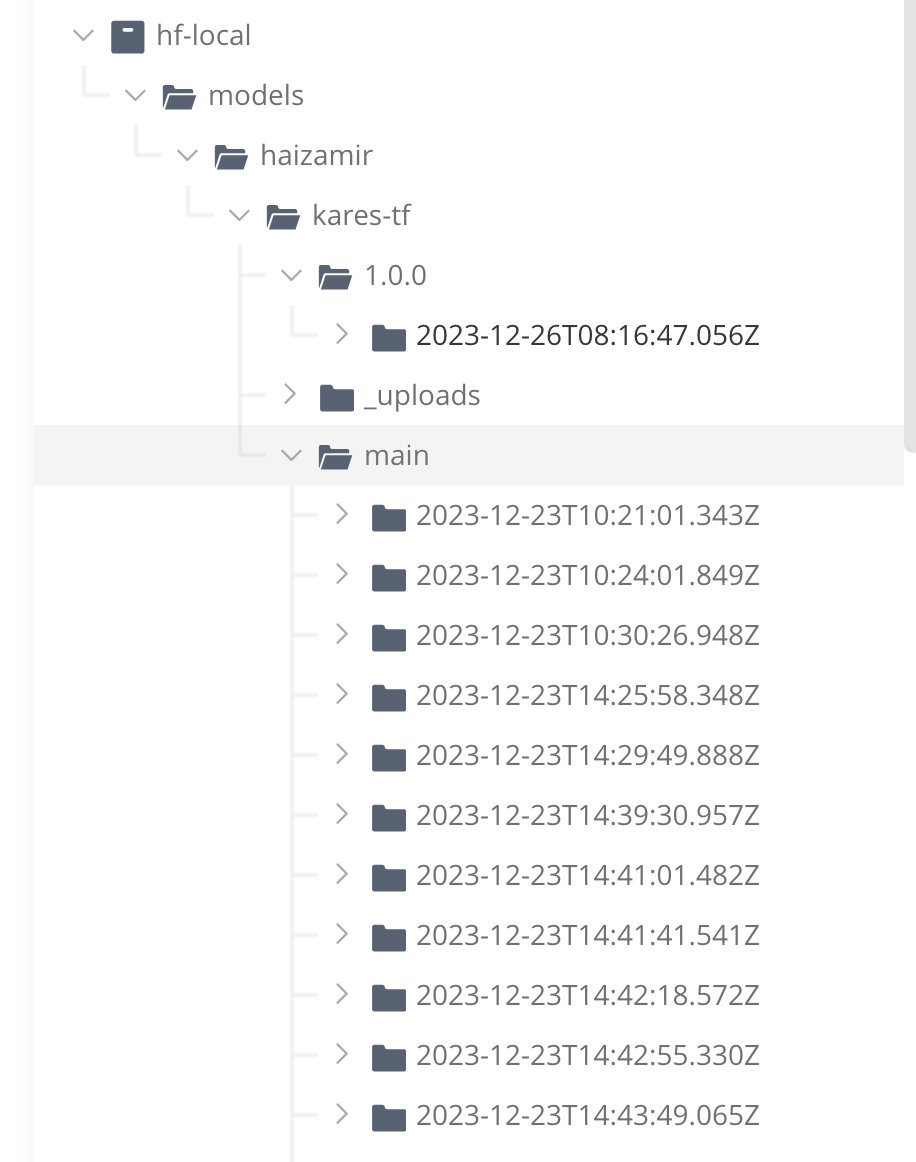
Basically, we’re adopting a convention-over-configuration approach. Our convention is that if you don’t state a revision name, it’s because it is a volatile or in-progress version that belongs under the “main” folder, your primary work area. If you have a meaningful version, you’ll give it a meaningful name. Tags are available for use for further organization.
Once model versions are in Artifactory, they can then be consumed both for validation and maturation as well as for deployment, but with the added benefit of the traceability, control, and security the JFrog Platform provides.
At this point, you might be thinking, “Okay, but what about all the storage this is going to use?” Not to worry! The same deduplication mechanisms apply to your models as they do to a Docker image, for example. Using its checksum approach, Artifactory indexes every component of the model and only stores the difference when a new version is uploaded. Further, you can leverage cleanup policies to help delete versions that didn’t make the cut. We’ll be adding ML-specific cleanup mechanisms down the road.
This approach greatly simplifies ML model versioning so that anyone who interacts with the ML development process can easily understand what’s going on.
What’s Next for Managing Models with JFrog?
AI and Machine Learning development is not a passing fad, nor is our desire to support DevOps, Data Scientists, and ML Engineers in bringing high quality, secure models to market through a trusted software supply chain. In addition to the versioning capabilities highlighted above, the GA of our ML Model Management capabilities also introduces Federation support for Hugging Face repos in Artifactory as well as resolving private Hugging Face models.
Already in the pipeline of continued enhancements to our ML model management and MLOPs functionality is the ability to create multiple “release versions” of a model by giving them a name (as we described above) and logically organizing them together.
Don’t use Hugging Face? We’re also exploring support for other machine learning development solutions, such as Qwak and MLflow, as part of how to best support organizations to manage proprietary models not originating from any public hub.
And of course, we’re exploring a number of integrations with the tools teams rely on to train and build their models.
Get started with ML Model Management Today
JFrog’s ML Model Management capabilities are available in all SaaS instances and Self-Hosted instances as of version 7.77.X, with security scanning requiring a Pro X or Enterprise subscription. If you’re not a JFrog customer yet, you can give this functionality a try in our free trial available both SaaS and Self-Hosted. You can also learn more about our ML capabilities by registering for our upcoming webinar.


