

The Software Supply Chain Risks You Need to Know

Code that an organization’s developers create is only the beginning of modern software development. In fact, first-party code is likely to be only a small portion of an application – sometimes as little as 10% of the application’s artifact ecosystem.
An enterprise’s software supply chain is made of many parts, accumulated from many sources: open source packages, commercial software, infrastructure-as-code (IaC) files, containers, OS images and more. This diversity means that the supply chain you need to secure has many, many points of risk, and a wide surface area for security threats due to mistakes, oversights, poor quality, or malicious attack.
The 4 key software supply chain risk trends
Understanding where these vulnerable points of risk are is important to securing your software supply chain. But, addressing them one-by-one with single point solutions is like playing whack-a-mole – a smashed threat can just appear somewhere else where you’re not looking for it.
Fully securing your supply chain from threats requires vigilance from end to end. This starts even before the developer calls an external package, going through the proprietary code development, code compiling and interim builds and throughout the pipeline to release and distribution, all the way to production and even after deployment. Beyond merely revealing vulnerabilities and other security issues, you’ll also need to know their context to be able to judge the true risk.
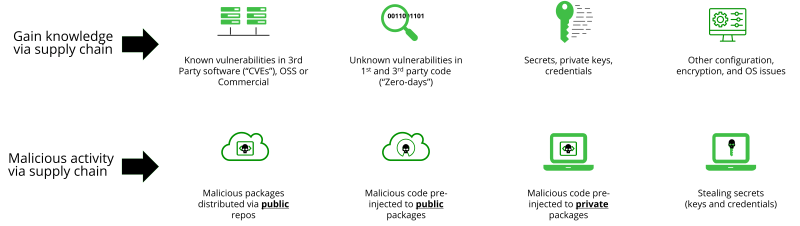
Software Supply Chain threats can be divided (roughly) into two main paths.
The first utilizes the supply chain “open nature” to gain information about software that the attacker intends to target. A common example would be an attempt of an adversary to map a web service remotely or drop a software for IoT devices to get familiar with the open source packages it uses. They can then easily find information about CVEs related to such packages, learn about the packages’ security configurations, or even work to find unknown vulnerabilities (AKA zero-days). When gaining sufficient knowledge about exploitation paths, the attacker can then move to the second phase.
The second utilizes the supply chain to inject malicious packages and malicious code to public or private repositories, or to alter existing code and bake malicious pieces into it.
Software supply chain attacks: Two main paths
Let’s examine four prominent risks that threaten the software supply chain and can make it vulnerable to attacks:
1. Known vulnerabilities
Components from third parties – such as open source and commercial software – can come with unintended vulnerabilities, many of which are known and publicly tracked in the Common Vulnerabilities and Exposure (CVE) list.
You can reveal such risks with a Software Component Analysis (SCA) solution that identifies the SBOM of a given code or artifact and associates it with known CVEs, mostly by cross referencing the metadata of the identified software to public CVE databases.
But, you’ll also need to have sufficient information to be able to make and automate risk-based decisions. An extended database is a must – one that not only tracks more risks, but includes in-depth security research that can help you understand all options for mitigating those risks, enabling you to choose the most practical and cost-effective method.
Equally important is contextual analysis that identifies how likely a vulnerability is to be exploited. For example, the vulnerable function in a component may not be used by the application, or a vulnerable process is never run in a production version, or a specific configuration renders a given CVE useless.
You can also recognize likely operational risks from components that appear to be safe. For example, an open source package that hasn’t been maintained for a while may not have been sufficiently monitored for security issues. In these cases, vulnerabilities aren’t certain, but a potential threat can be anticipated.
These known and anticipated risks can and should be discovered at the points of:
- Source code – Shifting left security vigilance to the time when code is created can save costs of later remediation. Security teams can curate an internal repository of approved 3rd party components, and/or developers can get alerts to vulnerable dependencies through extensions to their IDE. While inherently incomplete, this approach can help avoid known risks. It can never be exhaustive though, because shift-left security tools usually overload developers with hundreds or thousands of tasks that are not necessarily impactful from a security point of view because they miss the full context of the vulnerability or security issue.
- Binaries – Automated SCA scanning of all packages, builds, and images in key binary repositories (both first- and third-party components) ensures that your entire software supply chain is protected against known vulnerabilities and operational risks. As the most accurate representation of the production state of your application, binaries enable the highest quality real-world analysis of risks and more accurate context. It also allows analyzing issues that are “blind spots” to shift-left tools and to security-in-production solutions.
2. Unknown vulnerabilities (“zero-days”)
Mistakes are an everyday part of coding. Logic flaws, poor encryption, and potential memory corruptions unintentionally make applications vulnerable to malicious attacks such as remote code execution (RCE) and denial-of-service (DoS). These errors can lurk undetected in both first- and third-party code, sometimes for years before being recognized.
These are known as “zero day” issues, in part for the length of time they have been known – but also because their urgency means teams have zero days to fix them in already-deployed software.
To catch and prevent potential zero day issues, you must test each component and/or application, taking into account the flow between different binaries, processes and services. Static code analysis (to review code source) and dynamic code review (to test running code) tools can each typically identify about 85% of flaws, but they typically generate thousands of entries per release and expertise is required to interpret results and prioritize them. Just as with known issues, a vulnerability may exist, but it doesn’t mean it’s necessarily exploitable.
More advanced technologies that combine symbolic execution, data flow analysis and automated fuzzing can reduce the false positive ratio dramatically and identify vulnerabilities that cannot be found by typical SAST/DAST. Combining analysis of both source and binaries can also produce better results and help developers, security teams, and production managers focus on fixing what matters.
Despite best efforts, new vulnerabilities could always potentially be discovered and impact deployed software. Continuous SCA scanning can help ensure swift notification of any late-breaking CVEs that affect production software. A rich Software Bill of Materials metadata enables you to quickly know the full impact of a vulnerability to your organization, and to mitigate or remediate across your entire application inventory. A proper integration with code and artifact repositories enables to quickly take action across the organization and mitigate the identified threat.
3. Non-code issues
Not all vulnerabilities lie in your code – they can be found within binaries such as EPMs, jar files containers, firmwares, and in supporting artifacts such as configuration files or IaC files. Misconfigurations, poor encryption, exposure of secrets and private keys, or operating system issues can open up an attack surface.
These byproducts of human error are typically due to a lack of attention rather than malice, and are usually introduced outside of the hot spotlight of major development. Configurations thrown together for testing can be thoughtlessly promoted to production. These risks are often easy to fix – but hard to catch and harder to recover from.
Even a benign intent can lead to malicious consequences. Most notoriously, the SolarWinds breach began with a password exposed on a public GitHub server, enabling a malicious code injection that ultimately exposed sensitive government data. Dependency confusion between similarly named packages can also happen without malice, especially when package repository resolution is poorly configured.
It’s vital to catch these issues early, before they advance to production. You’ll need to take these potential risks at least as seriously as vulnerabilities in your code, and integrate this vigilance into the end-to-end security posture of your pipelines.
4. Malicious Code
Intentional threats, whether from external injection attacks or malicious insiders, can be the most difficult to find, since they are often masked to appear as an already validated component. Trojan horses, bots, ransomware, cryptominers and spywares are often delivered as payloads via the more benignly introduced vulnerability types we’ve already discussed. Seeding popular repositories with harmful packages, hacking into maintainer’s accounts to alter existing packages, or injecting code into compromised source repositories are frequently used methods of enabling backdoor access for an attack.
Finding these attacks after deployment is typically too late – the damage has been done, and it can be very, very costly. This is why you should protect against them throughout your pipeline:
- Access control – Internal package repositories must limit write access to key roles and team members through permissions and secure authentication (including multi-factor authentication) that’s consistent across the organization.
- Proxy repositories – Caching external repositories (such as Maven Central and npm) can provide an immutable snapshot of third-party resources, so any subsequent malicious overwrite will be immediately evident.
- Testing and analysis – Sophisticated static and dynamic analysis tools can detect and flag malicious code and malicious behaviors of questionable packages. The JFrog security research team has uncovered and disclosed over 1300 malicious packages in public package repositories through tools it has developed.
End-to-end vigilance for software supply chain risk management
While some of these risk trends can be addressed one at a time, point solutions are merely alarm systems – and only helpful where you think to place them.
For much the same reason, separate security-only solutions are of limited help as well, since their limited scope cannot help you to analyze and judge the full context of a risk within the entire software supply chain. When disconnected from the repositories and the software management solutions, even if the security point-solutions are very accurate it would be extremely hard to take an effective action to remediate and mitigate the identified issue.
A comprehensive security posture can’t just focus on isolated points in your pipeline, it must enable you to connect the dots between different issues and security findings – something that separate niche solutions can’t do.
Software security requires end-to-end vigilance, from the developer’s IDE all the way to production, enforcing consistent risk oversight and enabling mitigation in both development and production environments. Your security solutions must act holistically on your software supply chain, and enable you to take action on a large scale. To secure consistently across your organization, it must operate against a single source of truth for all of your binaries, and be deeply integrated with your DevOps tools.
Want to learn about “what’s next” from JFrog that will help meet these needs? Register for one of the swampUP City Tour events coming soon near you!
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



