

Native Xet Protocol Support in JFrog Artifactory: How Enterprise Model Management Actually Works


By
10 min read

Machine learning models are not like other software artifacts. A single fine-tuned LLM can weigh 70 GB. A model family may share 95% of its weights across dozens of variants. When hundreds of developers, training jobs, and GPU clusters all need the same model at the same time, the infrastructure underneath needs to be built for it.
JFrog Artifactory’s support of the Xet protocol is just one of the ways we continue to be the trusted partner to handle the largest workloads in both AI and traditional software delivery. This post explains how our native Xet protocol support works and how enterprise teams get the most out of it.
Why Xet?

Xet is a proprietary storage technology Hugging Face developed after acquiring the startup XetHub. It was built specifically to replace the inefficiencies of Git LFS on the Hugging Face Hub. Before adopting Xet, Hugging Face relied on Git LFS, a protocol that served the industry well for versioning large files. However, at the scale and velocity of modern ML, new infrastructure was needed.
Xet is a content-addressable storage (CAS) protocol built for large binary files, like AI models, designed to reduce both storage costs and transfer times. Instead of treating a model as a monolithic blob, Xet splits files into small, content-defined unique chunks. These chunks are then grouped into Xet orbs (abbreviated to “xorb”) bundles of up to 64 MB that serve as the natural unit of storage and transfer.
This is what makes deduplication possible at scale. If that exact chunk appears in another model like a shared tokenizer, a common embedding layer, unchanged weights, it is stored exactly once. Storage grows only with genuinely new content, regardless of how many models reference the same chunks.
The result is a compounding efficiency: fine-tune a 50 GB model and change 2% of its weights, and a Git LFS system stores and transfers another full 50 GB. With Xet, only the changed chunks move. The rest are already there, already cached, already fast.
How Does JFrog Support Xet and Hugging Face?
JFrog was the first to proxy and offer dedicated Hugging Face repositories in 2023, when Hugging Face was still leveraging GitLFS for storage. But we don’t just proxy Hugging Face, we also provide them with model security advisory on their model hub with the highest quality of “no false positives.”
Since 2023 our support has evolved, alongside Hugging Face, to now include native Xet support. For organizations managing models with JFrog, that means tangible improvements:
- Up to 3.7x speed improvement in subsequent pulls
- Chunk level deduplication
- Multithreading downloads
- Universality of model types and formats you can manage
- Federation of your model artifacts across sites
Which Artifactory Repositories Support the Xet Protocol?
JFrog offers two repository options for models and their artifacts: Hugging Face and JFrog’s client-agnostic Machine Learning Repository. Both repositories share a common layout, but are scoped for different clients.
This allows Enterprise AI workflows to be managed, governed and secured from a single registry even if their production pipeline pulls a Hugging Face base model, a fine-tune saved as a PyTorch checkpoint, an ONNX export for inference, and a set of supporting configuration files.
Today Xet is supported on Hugging Face remote repositories, with local repository support coming within the upcoming weeks.
How Can I Turn on Xet Support For My Hugging Face Repositories?
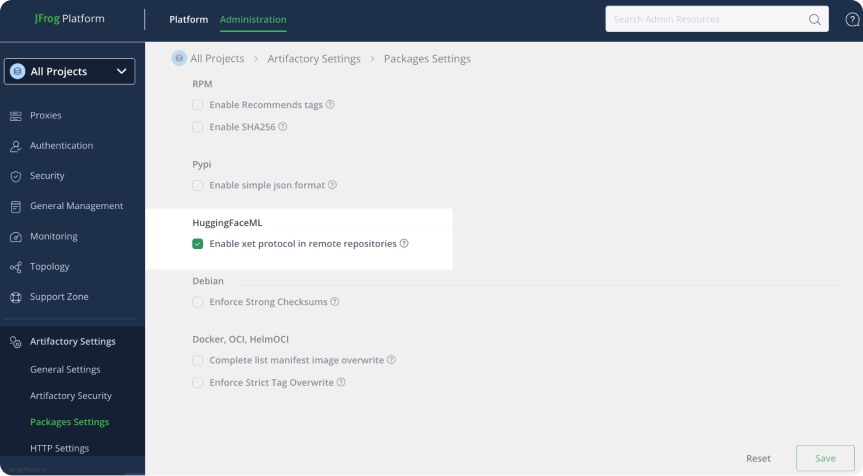 Turning on Xet for your remote Hugging Face is a single checkbox in your package settings.
Turning on Xet for your remote Hugging Face is a single checkbox in your package settings.
If your Hugging Face repository was created before Artifactory V 7.111.1 you will need to update your Hugging Face repository to our latest “Machine Learning Layout”. In addition to the benefits of Xet, this layout unlocks a host of other functionality required by enterprises.
How does Xet Support Work for JFrog Artifactory Under the Hood?
JFrog has operated checksum-based storage and deduplication at enterprise scale for years, across Docker layers, Maven artifacts, npm packages, and more. This deduplication approach yields significant performance improvement and cost saving benefits for development organizations. Activating our native Xet support extends that same proven approach to Hugging Face repositories (huggingfaceml package type) in Artifactory.
In practice, when multiple model revisions share common content, which is the norm for fine-tuned model families, that content is stored once and referenced by as many models as need it. Storage grows only with genuinely new data. Common weights, shared tokenizers, and unchanged layers across your model fleet are stored once and served everywhere.
Artifactory is also optimized for how Xet content is actually requested. Rather than storing complete xorbs, Artifactory stores the specific xorb ranges clients request. This means the cache is shaped by real usage. The content your teams actually need is what gets stored and served at speed. Clients requesting the same content get it directly from cache, with no round trip to the upstream registry.
Deduplication in Artifactory
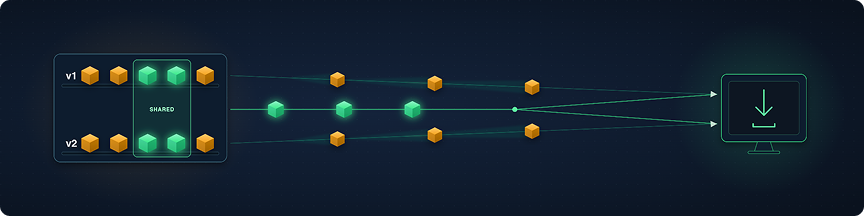
Artifactory’s storage engine operates on file-level deduplication. This allows multiple links in the database to point to the same item in storage. To someone unaware of how this works, it may appear as though the same file is stored more than once. In reality it is just links in the database (DB) to the single file.
In practice, when multiple model revisions share common content — which is the norm for fine-tuned model families — that content is stored once and referenced by as many models as need it. Storage grows only with genuinely new data.
Maintaining Xet compatibility
Caching an upstream package manager client is considered good practice by both the engineering and security communities. When using a cached package manager client, there’s always the inherent chance of client compatibility issues when a new breaking change version is introduced. This is true for any technology, not just Xet.
Ensuring client compatibility is something JFrog has mastered across dozens of technologies and thousands of large scale enterprises. We proactively monitor protocol changes to identify them, test their stability and security, and ensure support readiness even before they land. We also continuously verify compatibility with automated tests running common scenarios every day on multiple client versions including latest, popular, and beta/RC. Delivering uninterrupted customer workflows is a responsibility we take very seriously.
Scaling model usage and avoiding 429 rate limit errors
Artifactory answers BILLIONS of artifact requests to developers, CI systems, and agents daily. There are two essential mechanisms at play that ensure upstream registries are not flooded and causing errors.
The first is caching: JFrog Artifactory is your private, local cache of the model artifacts your teams rely on daily. Whenever possible, all requests are served directly from JFrog rather than going out to the public registry to fetch required assets. This serves the dual benefit of reducing download traffic over the public internet and speeding up artifact delivery as the cache can be located as close to your workflows as possible.
The second is intelligent rate handling: We automatically apply guardrails to ensure that public registries from – Hugging Face to Docker Hub – don’t reject traffic from Artifactory sites. If a sudden spike of latest requests comes in we smooth them out slightly to ensure upstream registries are not flooded.
To summarize: Once a chunk is cached, no subsequent request for it touches the upstream at all. That, plus our built-in rate handling, ensures from the Hugging Face Hub’s perspective, a warm Artifactory deployment looks like a single, well-behaved client, not a fleet of 500 engineers.
In the rare event teams do encounter upstream rate limits, the root cause is almost always a Personal Access Token (PAT) configured as the upstream identity on the Artifactory remote repository. PATs are tied to an individual’s account, carry that account’s rate limit tier, and create operational fragility. They disappear when someone leaves the company, have no fine-grained scope, and produce no organizational audit trail. The right configuration is an organizational token from a properly-tiered Hugging Face account. Combine that with Artifactory’s caching and upstream rate limits become a non-issue in practice.
Why is JFrog the Best Option for Enterprise Model Management?
1. Storage That Scales With New Data, Not Total Data
Global chunk deduplication means your storage footprint grows only when models introduce genuinely new content. Common weights, shared tokenizers, and unchanged layers across your model fleet are stored once and referenced everywhere.
2. Production Continuity Independent of Upstream Availability
Models cached in Artifactory are your organization’s independent copy. Upstream outages, model deletions, and API instability do not reach your production environments. Your training runs and inference workloads operate on your infrastructure, on your schedule.
3. Centralized Access for Gated Models
Models like Llama, Gemma, and Mistral require individual user agreements on the public Hub. With Artifactory, a platform administrator configures the organizational credentials once. Every authorized user in the organization gets access immediately, with no individual license acceptance, no credential sprawl, and a full audit trail.
4. Security Scanning and Malicious Model Protection
As models flow from public hubs into training pipelines and production inference, they become one of the most under-secured links in the supply chain, and a single poisoned model can propagate across every application that depends on it. Artifactory acts as a secure proxy to Hugging Face, automatically scanning incoming models for security risks and blocking threats before they enter your network. The same trusted supply chain governance you apply to container images now extends to your ML fleet, ensuring every model pulled by your developers and data scientists is vetted, safe, and traceable.
Get Started With Xet and JFrog Artifactory Today
Bringing native Xet protocol support into JFrog Artifactory bridges the gap between developer velocity and your DevSecOps infrastructure. This native capability integrates modern chunk-level protocols into our global deduplication engine, keeping storage costs controlled while delivering a significant performance improvement.
For existing JFrog customers, you can activate these performance and storage enhancements immediately by flipping the Xet toggle in your repository settings. If you’re new to JFrog you can try all our repository types with a free trial or contact our team today for an enterprise AI infrastructure review.


