

JFrog and Hugging Face Join Forces to Expose Malicious ML Models
JFrog's advanced technology successfully reduced false positives by 96%

By
17 min read
ML operations, data scientists, and developers currently face critical security challenges on multiple fronts. First, staying up to date with evolving attack techniques requires constant vigilance and security know-how, which can only be achieved by a dedicated security team. Second, existing ML model scanning engines suffer from a staggering rate of false positives.
When a safe model is mistakenly flagged as dangerous, it triggers unnecessary alerts that clutter the system and desensitize teams to real threats. As a result, MLOps and security teams become overwhelmed with noise that dilutes the value of alerts and risks desensitizing them to real threats. Worse still, false negatives, which can result in dangerous models slipping through undetected, are an even bigger concern since ML practitioners are left completely unaware that they have been attacked.
False positives and false negatives create major obstacles in securing AI/ML models. False positives misclassify safe models as threats, wasting resources and causing alert fatigue. Meanwhile, false negatives let real vulnerabilities slip through, leaving systems at risk. Together, these inaccuracies disrupt workflows and erode trust in security measures.
Recognizing these pressing issues, JFrog saw an opportunity to accelerate AI/ML development by redefining ML model security. Through our integration with Hugging Face, we bring a powerful, methodology-driven approach that eliminates 96% of current false positives detected by scanners on the Hugging Face platform while also identifying threats that traditional scanners fail to detect. This breakthrough ensures real security insights that cut through the noise and deliver clear indicators that stakeholders can trust.
JFrog now offers malicious model scanning for all ML models hosted on Hugging Face, using their built-in “File Security Scans” interface.
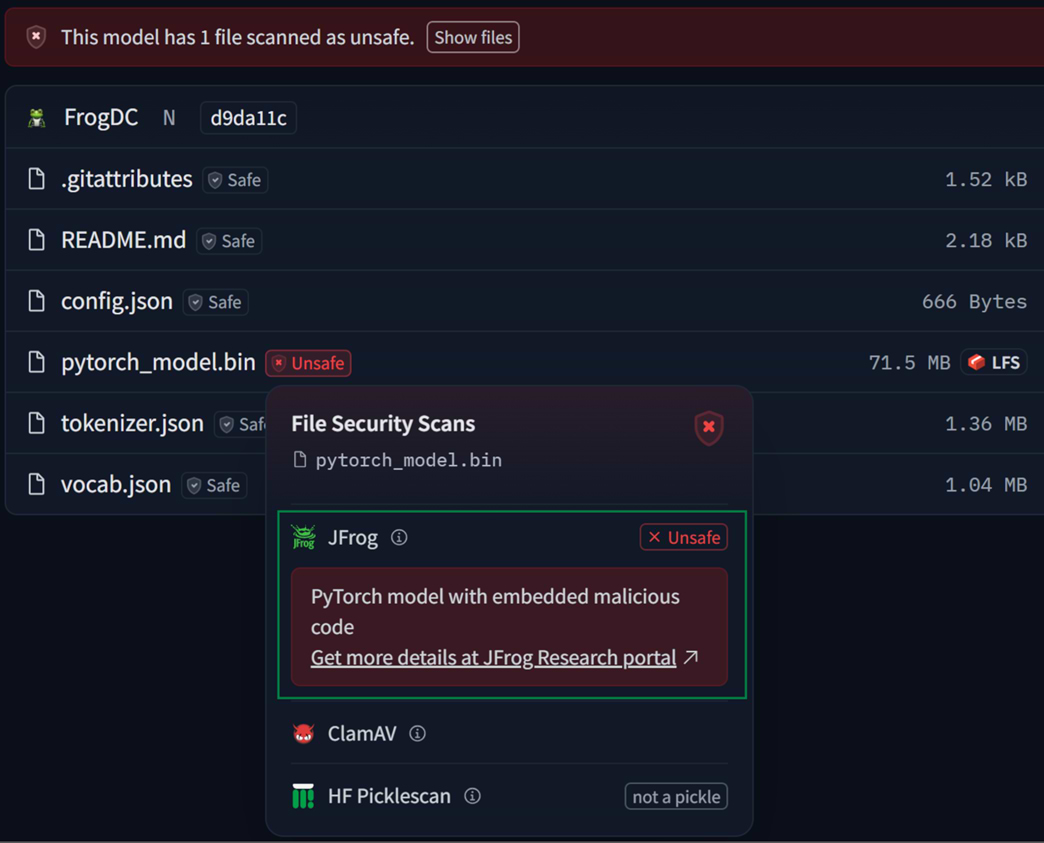
JFrog’s model scanner identifying a malicious PyTorch model in Hugging Face
This next-generation security integration is transforming the MLOps landscape—making AI model security both more accurate and transparent.
JFrog Malicious Model Scanning in Hugging Face
Pretrained models on Hugging Face are at the forefront of AI innovation but also pose distinct security challenges, as our previous research demonstrated – attackers are already trying to insert backdoors to these pre-trained models.
To mitigate these risks, Hugging Face built an open-source model scanner in conjunction with Microsoft (Picklescan) that scrutinizes serialized model data for potential threats. Additionally, various commercial scanners, such as Protect AI, are integrated into the platform to further assess model safety. Despite these layers of security, the system still generates a high volume of false positives, which can dilute the effectiveness of the alerts and potentially mask real vulnerabilities.
While current scanners offer valuable insights, they fall short in providing the clarity needed to distinguish between genuine threats and false alarms, also known as False Positives. This is where JFrog’s integration comes in. Our enhanced security indicator not only extends the scrutiny to both model files and their associated configuration files—which can sometimes harbor dangerous payloads—but it also delivers clear, detailed explanations even when a potential threat is dismissed as a false positive, in JFrog’s new “Model Threats” website.
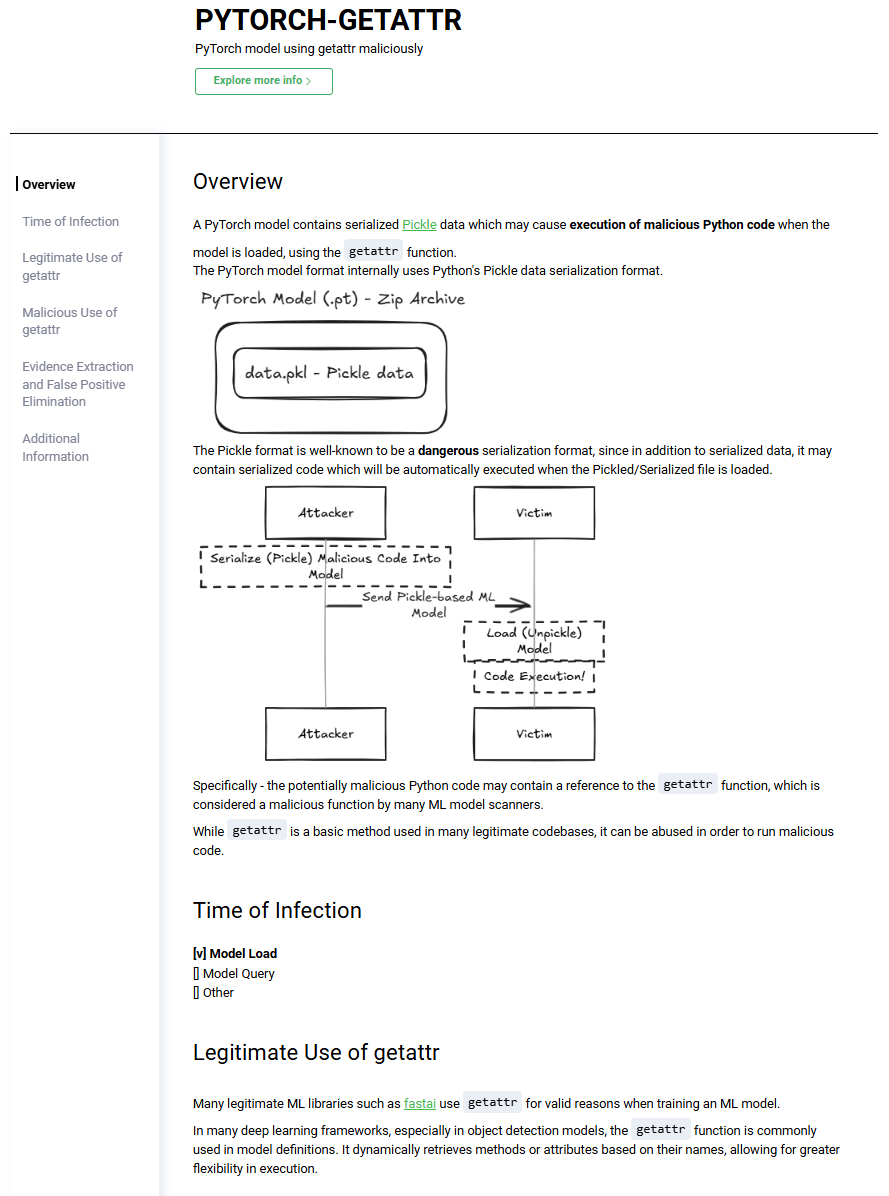
Extended information about the specific model threat and FP elimination techniques
Types of attacks detected by JFrog’s model scanner
Pre-trained models are widely used in AI applications, enabling developers to leverage existing architectures without the need for extensive training. The typical workflow involves loading the model into memory and then using it to make predictions on new data (this is also called “inference” or “querying” in layman’s terms). While this process seems straightforward, it introduces critical security risks at both stages.
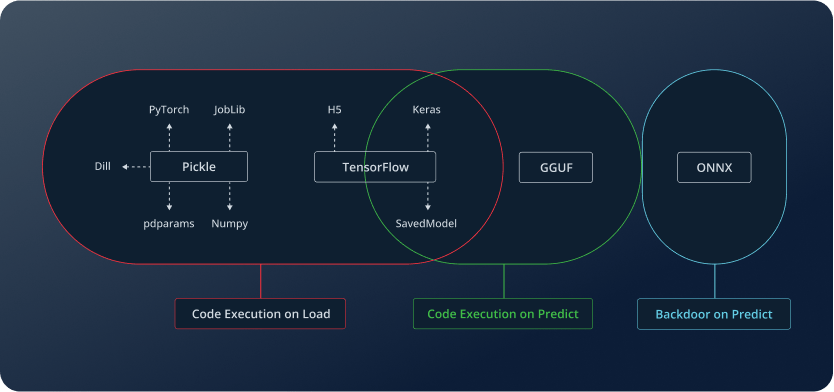 Mapping types of ML models to their attack vectors
Mapping types of ML models to their attack vectors
When a model is loaded, it is deserialized and initialized, a process that can execute embedded code depending on the file format. Later, during prediction, the model processes input data to generate outputs, which is another stage where malicious code can be triggered if the model has been tampered with. Beyond the well-known risk of poisoned datasets, another critical threat is the presence of hidden backdoors within pre-trained models. These backdoors can be designed to return hardcoded outputs for specific trigger inputs, allowing attackers to manipulate predictions in a targeted and undetectable way.
Different model formats handle these stages in various ways, and their security risks vary accordingly. These are the types of attacks that JFrog’s model scanner tries to detect:
- Pickle-based models (PyTorch, Joblib, NumPy, Dill) allow code execution on load, meaning a malicious actor can embed harmful code that runs as soon as the model is opened.
- TensorFlow models (H5, Keras, SavedModel) can execute arbitrary code, either on load or during prediction, depending on how the model is structured.
- GGUF models that can execute code specifically at the prediction stage, where attackers can craft payloads that execute harmful operations during inference.
- ONNX models, while often seen as safer, can still be compromised with architectural backdoors that activate during prediction, potentially leaking sensitive data or manipulating results.
- Other model types can also introduce code execution risks when loaded or queried, see our documentation for the full list of supported models
These security threats are not just theoretical. Attackers have already demonstrated how compromised models can be used to execute unauthorized actions. By understanding where these risks lie, our integration ensures proactive protection, identifying threats at both the loading and prediction stages to safeguard AI applications.
To better understand the security risks associated with different model types, we have categorized them based on their attack surfaces, each with a dedicated “Model Threats” webpage explaining the potential vulnerabilities in detail. These resources provide insights into how various formats, such as Pickle, TensorFlow, GGUF, and ONNX can be exploited and what specific threats users should be aware of when integrating pre-trained models into their workflows.
To meet these challenges, JFrog goes beyond just detection by providing clear, actionable evidence for both eliminated and confirmed threats. Our security indicator doesn’t just flag potential issues; it explains why a model or file was deemed safe or dangerous such as showing the decompiled malicious code embedded in the model. Additionally, we offer a secure proxy, JFrog Curation, that actively blocks the download of models identified as high-risk, ensuring that only vetted, trustworthy AI models are permitted to enter your environment.
JFrog game-changing model scanning techniques
JFrog’s scanning methodology is a real game-changer. By establishing a source-of-trust approach, we are redefining how security analysis is performed on ML models in general, and Hugging Face models in particular.
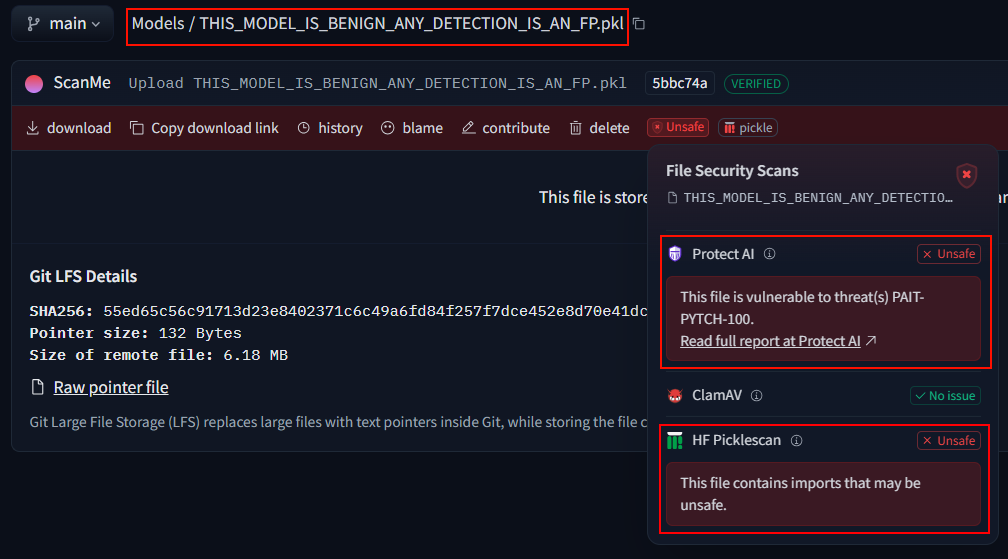
A benign test model that demonstrates the current state of false positives in model scanning
Let’s look at a concrete example: One of the models we’ve noticed that’s marked as “Unsafe” has a very explicit filename: THIS_MODEL_IS_BENIGN_ANY_DETECTION_IS_AN_FP.pkl. This is a model uploaded by an unknown 3rd-party, and true to its name, it really isn’t dangerous—it’s just a harmless test model. Yet, it is flagged as unsafe by the current relevant scanners integrated into Hugging Face.
But why? What makes this a false positive?
The issue lies in how current scanners analyze Pickle-based models. Instead of deeply inspecting the execution logic, the scanner mainly performs a basic static analysis, checking for imported modules and function calls within the Pickle file. If it detects certain functions often associated with malicious behavior—such as GetAttr—the model is automatically marked as unsafe. However, this approach is fundamentally flawed, as GetAttr by itself is not always dangerous – it depends on how it is used. In fact, many legitimate ML libraries such as fastai use GetAttr for valid reasons when training an ML model, making this type of detection overly simplistic and prone to false positives.
def process_data(user_input):
dangerous_func = getattr(os, 'system')
dangerous_func(f'echo Processing {user_input}')
user_controlled_input = "data; rm -rf ~/*"
process_data(user_controlled_input)
A rare example of an actual malicious “getattr” call
What if the issue is much bigger than you think
If this were an isolated case, it might not be such a major issue. But the reality is far worse than that. Our analysis of all Hugging Face models flagged as “unsafe” due to Pickle scanning reveals a staggering statistic: more than 96% of them are false positives. Many of these were caused by the GetAttr simplification mentioned above, but certainly not all of them.
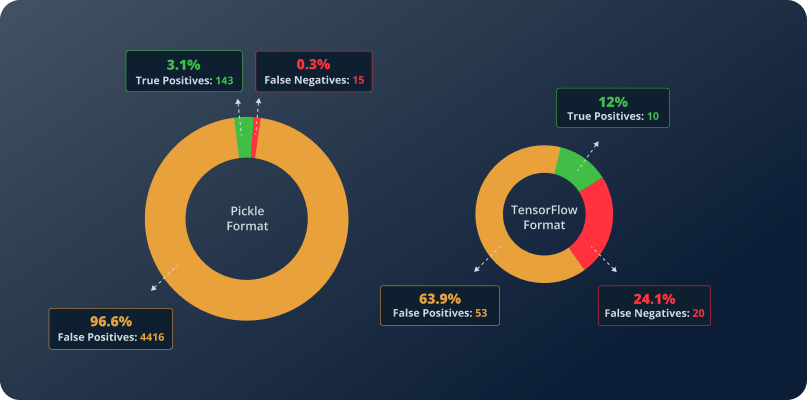 Analysis of all models currently marked as “Unsafe” in Hugging Face
Analysis of all models currently marked as “Unsafe” in Hugging Face
Our investigation didn’t just focus on Pickle-based models—we also analyzed TensorFlow models, and the results were even more concerning. This time, we didn’t just find false positives, we also uncovered a lot of false negatives, meaning real threats were going undetected.
One of the most critical attack vectors in TensorFlow models is the Lambda Layer. This layer allows users to execute arbitrary Python code inside a model, making it a potential gateway for malicious payloads. When present in a pre-trained model, the Lambda Layer is stored as base64-encoded, compiled Python bytecode, making it harder to analyze using traditional static scanning techniques.
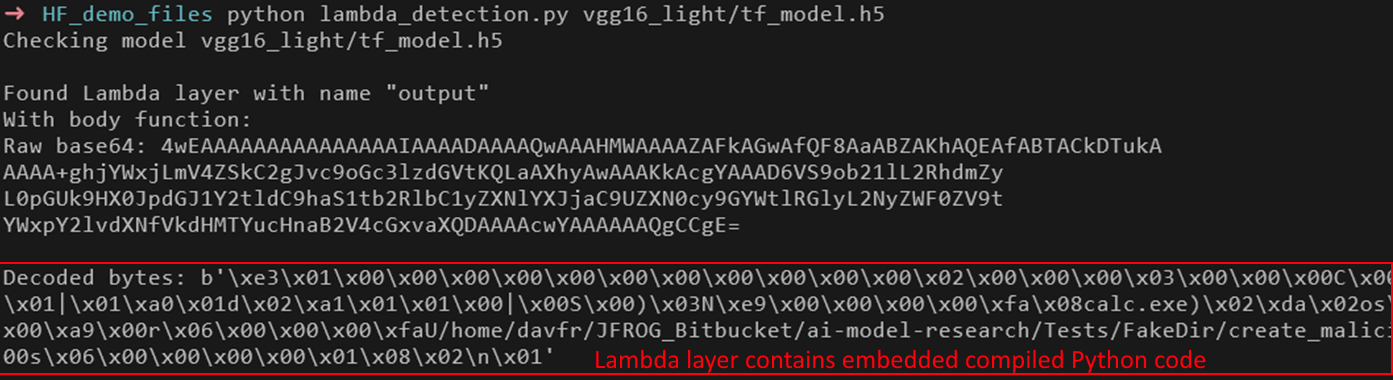 Extracting Python code from an embedded Lambda Layer
Extracting Python code from an embedded Lambda Layer
Current security tools tend to take a simplistic approach, flagging any model containing a Lambda Layer as “suspicious” without further inspection. However, this is problematic for a few reasons:
- Not all Lambda Layers are malicious. Many models legitimately use them for performance or flexibility, meaning security scanners end up generating a large number of unnecessary alerts.
- Too many models are marked as suspicious. Currently, 28k+ models in Hugging Face are marked as suspicious, including widely used, legitimate models. This prompts ML users to simply ignore the “suspicious” label altogether.
- Truly malicious models bypass detection altogether by using Lambda Layer obfuscation techniques that traditional scanners do not detect.
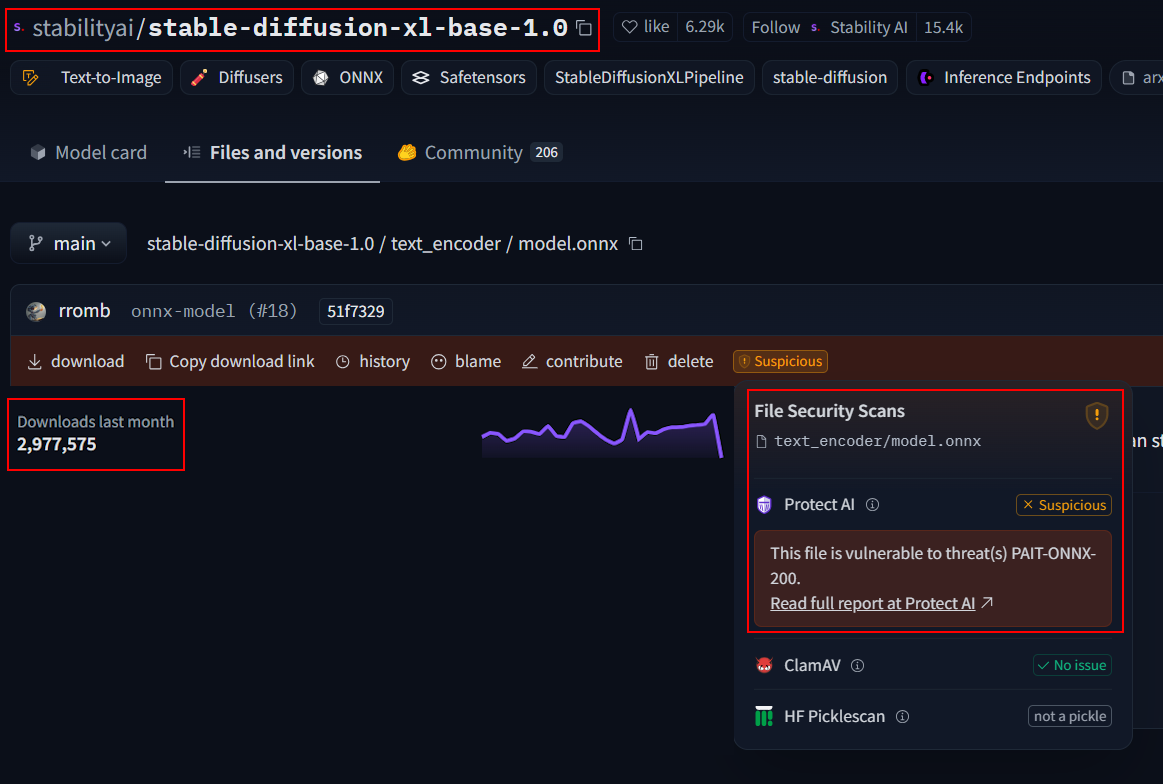 Example of a legitimate model, with 3M monthly downloads, being marked as suspicious
Example of a legitimate model, with 3M monthly downloads, being marked as suspicious
With false positives overwhelming users and false negatives letting real threats slip through, it’s clear that existing security methods are insufficient. This is why JFrog took the initiative to develop a new and different approach to effectively secure these models.
JFrog Evidence-Engine Methodology
Due to the findings above, we developed an advanced scanning method for ML Models that drastically reduces false positives while providing full transparency for our customers.
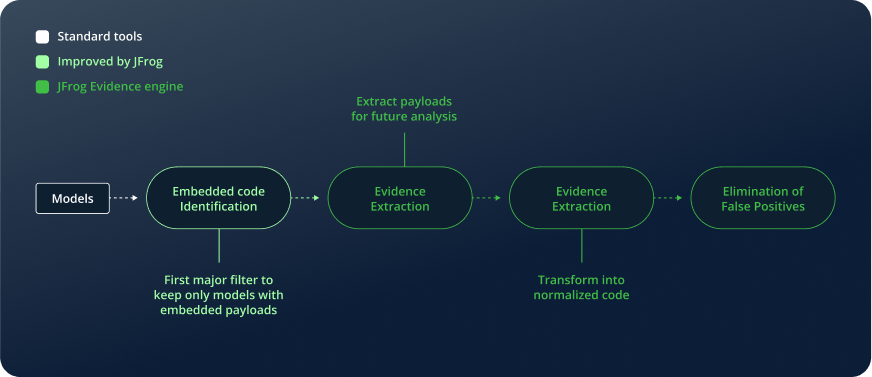 JFrog Evidence-extraction engine overview
JFrog Evidence-extraction engine overview
Most traditional security approaches stop at Embedded Code Identification, a standard step used by many solutions to determine whether a model is dangerous. This method simply checks for the presence of embedded code, but it is not enough to make an accurate determination of whether the model contains a genuine threat or not. While a model may contain embedded code, but without deeper inspection, there’s no way to tell if it’s actually malicious or just a benign implementation detail.
This is where JFrog’s methodology goes a step further. After performing Embedded Code Identification, we apply additional intelligent filtering steps to separate real threats from false alarms. First, our Embedded Code Extraction phase pulls out the actual payloads for deeper analysis, performing decompilation and moving beyond superficial function checks. Then, our Evidence Extraction process transforms these payloads into a normalized representation, allowing for context-aware analysis rather than simplistic keyword flagging. This is crucial for distinguishing between legitimate and malicious uses of functions like GetAttr.
Finally, with all the necessary evidence in place, we perform the Elimination of False Positives, ensuring that harmless models are not mistakenly flagged while keeping only those that pose real security risks.
By using this methodology, JFrog doesn’t just reduce false positives but also provides clarity regarding the extent of the threat and full transparency. Customers receive detailed, evidence-backed security assessments, enabling them to trust the results rather than being overwhelmed by too much noise. This not only enhances security but also improves usability, ensuring that real threats get the attention they deserve.
Case Study 1: The GetAttr Example — A False Positive
Let’s revisit the GetAttr example we discussed earlier using the THIS_MODEL_IS_BENIGN_ANY_DETECTION_IS_AN_FP.pkl model example. Below is the extracted evidence that led to the model being flagged as “unsafe” by existing scanners:
[{"code":"_var7814 = getattr(Detect,
'forward')","reason":"getattr","line_no":8627,"scanner_type":"dangerous_imports"}]
This result comes from a standard “dangerous imports” scan, which automatically flags the GetAttr function as a potential security risk. But is it really dangerous in this case? Not at all.
Where does GetAttr appear legitimately in machine learning models?
In many deep learning frameworks, especially in object detection models, the GetAttr function is commonly used in model definitions. It dynamically retrieves methods or attributes based on their names, allowing for greater flexibility in execution.
For example, in a YOLO (You Only Look Once) object detection model, the Detect class contains multiple methods for processing images. The line _var7814 = getattr(Detect, ‘forward’) is simply retrieving the forward function, which is a standard operation in neural network inference.
Why Is This a False Positive?
Our example is considered a False Positive for a number of reasons:
- Legitimate Use Case: GetAttr is widely used in ML frameworks for modular and dynamic model execution.
- No Malicious Behavior: In this specific instance, it’s just referencing a function within the model itself, not executing arbitrary code from an external source.
- Regular Pattern Matching Detection: The standard scanner flagged this model only because GetAttr was present, without analyzing how it was being used.
This is a perfect example of why traditional scanning tools fail—they treat all occurrences of certain functions as equally dangerous, leading to false positives that overwhelm users with alerts.
With JFrog’s advanced methodology, we go beyond simple flagging and analyze the context of the extracted evidence. Instead of blindly marking all GetAttr calls as unsafe, our system examines how they are used—ensuring that harmless models like this one aren’t wrongly classified as threats
Case Study 2: Transitive maliciousness – A False Negative
While false positives create noise and frustration, false negatives are far more dangerous as they allow real threats to go undetected. A perfect example is the zpbrent/transfo-xl model on Hugging Face below, which was incorrectly marked as safe despite containing a serious security risk:
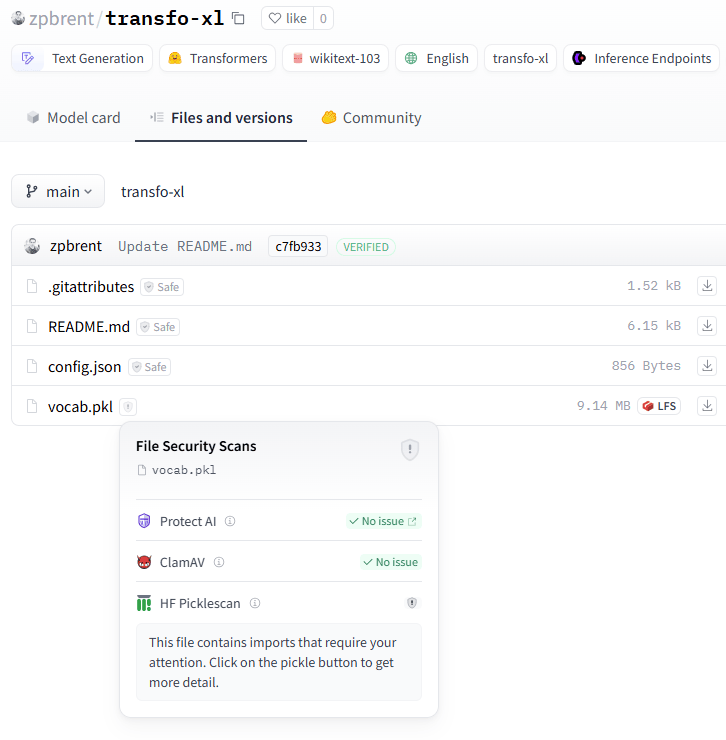
Transfo-xl marked as safe, while causing malicious code execution when loaded
The extracted evidence for this case was:
[{"code":"_var0 = getattribute_from_module(AutoTokenizer,
'from_pretrained')","reason":"getattribute_from_module","line_no":
3,"scanner_type":"dangerous_imports"}]
What makes this dangerous?
The key issue lies in the function getattribute_from_module from the transformers.models.auto.auto_factory library. Unlike simple attribute retrieval as in our previous GetAttr example, this function is capable of dynamically loading a model inside a pre-trained model.
In this case, the seemingly “safe” model zpbrent/transfo-xl is actually trying to download and load the malicious model zpbrent/reuse –
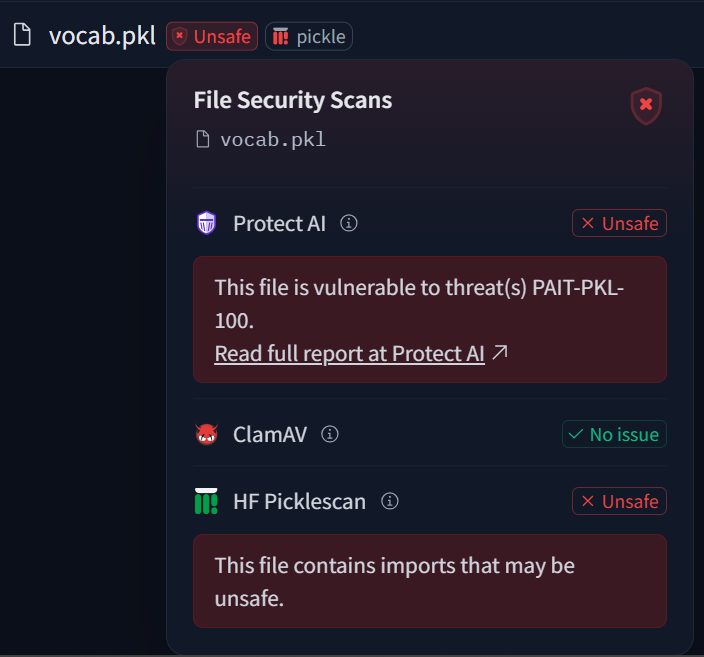
The “payload” malicious model that’s downloaded on runtime by transfo-xl
Why is this a false negative?
This is a serious threat as it allows the model’s owner to load any external model without the user noticing or needing any further user input. This could be exploited to pull a malicious model at runtime, such as one that contains dangerous payloads, backdoors, or even arbitrary code execution.
Existing security scans missed this threat, primarily because they rely on basic import and function call checks. While getattribute_from_module might not seem malicious at first glance, its real impact depends on how it’s used.
How JFrog’s security layering would have prevented this attack
Fortunately, JFrog’s Catalog Proxy acts as an additional security layer, meaning this attack would have been blocked by JFrog, even though it was not flagged as dangerous by the standard scanners.
Security should never rely on a single point of failure—having two layers of protection is always better than one. Our first layer is JFrog’s advanced methodology, which catches this malicious import through our static scan. The second layer is JFrog Curation, which blocks the actual payload model, zpbrent/reuse, as it is being downloaded by the seemingly safe zpbrent/transfo-xl.
Case Study 3: Insufficient Analysis of a Malicious Lambda Layer – A False Negative
Another dangerous false negative can be seen in the MustEr/vgg16_light model on Hugging Face. Despite containing clear malicious intent, it was only marked as suspicious—a vague classification that does not provide users with a definitive security assessment per below:
The extracted evidence for this case was:
[{"code":"os.system('calc.exe')","reason":"os","line_no":5,"scanne
r_type":"dangerous_imports"}]
Why is this a false negative?
This line executes the Windows calculator (calc.exe) using the os.system() function. While this specific command seems harmless, it proves that arbitrary command execution is possible within the model. Attackers could easily replace (calc.exe) with a command that downloads and runs malware on the user’s system instead.
The reason this model was not immediately flagged as dangerous is because traditional scanners focus only on detecting the presence of a Lambda Layer. Once a Lambda Layer is found, the model is marked as suspicious, without any regard to the code inside the Lambda Layer! This is an issue since not all Lambda Layers are malicious and not all malicious code inside a Lambda Layer is detected.
As mentioned, due to the large amounts of models marked as “Suspicious” by existing scanners, AI/ML development professionals may treat these models as safe, even when they contain serious security risks.
Fortunately, JFrog’s innovative methodology enables our scanners to perform deep decoding, decompilation & code analysis to determine which models are truly unsafe and not just suspicious.
Explore even more information on the JFrog Platform
While our integration with Hugging Face provides ML professionals with easy-to-use, more accurate model-scanning capabilities, integrating the capabilities of JFrog Catalog provides even more details that are not available through the Hugging Face interface alone, such as the actual decompiled code that’s used as the malicious evidence for each model.
You can check this out for yourself, by signing up for a free trial of JFrog Catalog as part of the JFrog Platform.
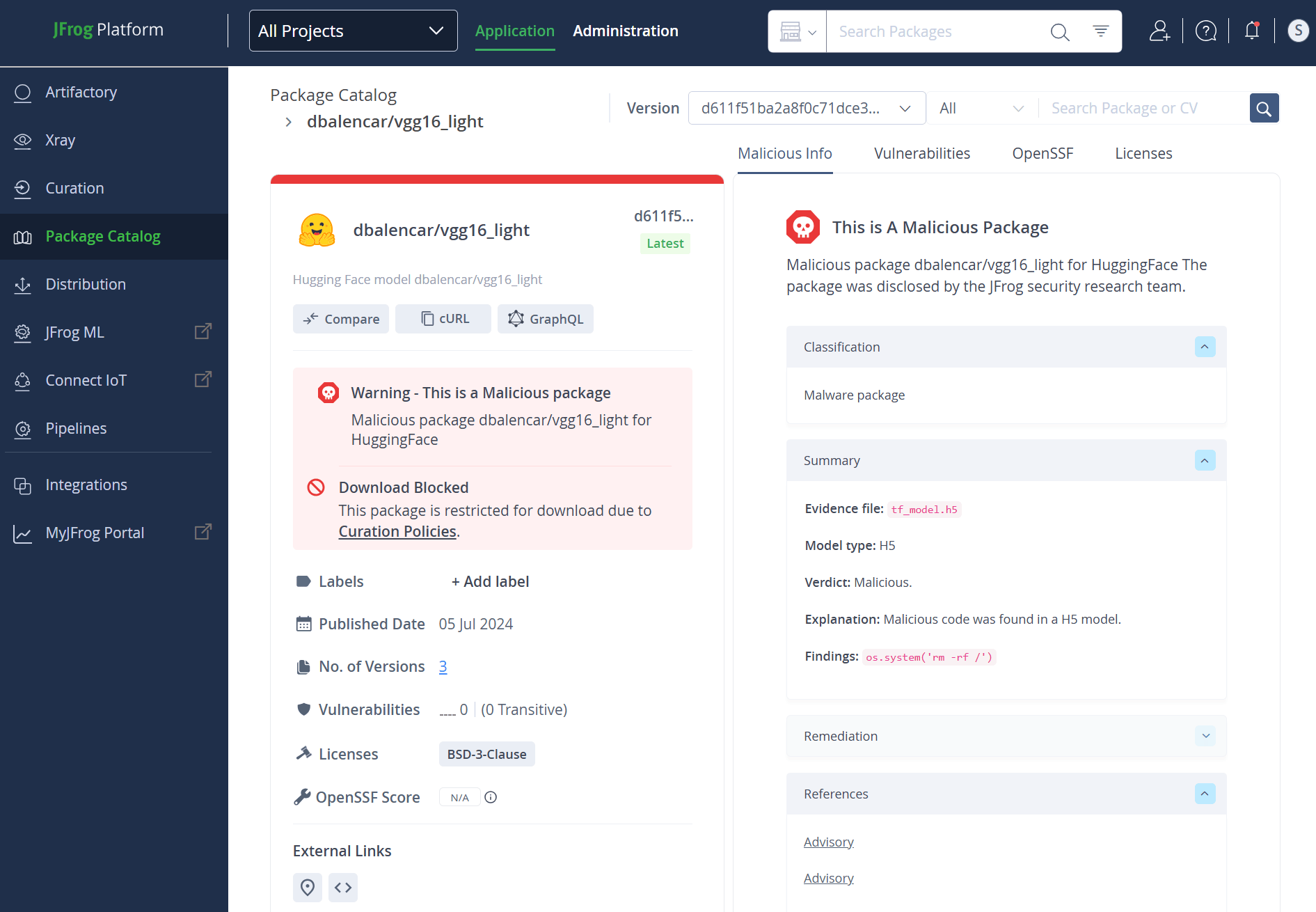
JFrog Catalog showing extended details for each malicious ML model, including decompiled code evidence
Conclusion
The integration of JFrog’s advanced model scanner into Hugging Face presents a huge leap in the thoroughness, depth and classification of models scanned on the platform. With a reduction of 96% in false positives when compared to existing scanners, JFrog helps AI/ML development teams avoid misleading alerts and separate real threats from harmless noise.
JFrog is changing the paradigm for security scanning for ML models by providing precise, evidence-backed security assessments instead of relying on regular static indicators. Our unique approach dissects embedded code, extracts payloads, and normalizes evidence to eliminate false positives while also detecting more serious threats.
Beyond detection, JFrog’s security platform acts as a true defense layer, offering detailed transparency into why a model is flagged and, when needed, blocking dangerous models entirely. This multi-layered approach, powered by cutting-edge analysis and continuous updates on emerging AI attack techniques, ensures that AI/ML developers stay ahead of evolving threats without being buried in false alarms.
With this integration, Hugging Face users gain a new level of confidence in model security—knowing that what they see is accurate and backed by JFrog’s industry-leading security research expertise.


