

JFrog’s SPOF Framework for SaaS Ecosystems



By
7 min read

As Software as a Service (SaaS) solutions evolve, organizations face increasing pressure to ensure uninterrupted service delivery. One of the most significant threats to SaaS Service delivery and operational continuity is the presence of known and unknown Single Points of Failure (SPOFs). As a SaaS organization, the team at JFrog deeply understands the risks of SPOFs and works hard to avoid them.
In this blog, we’ll delve into the SPOF framework developed by the JFrog Site Reliability Engineering group to help mitigate risk in our own organization. Throughout, we’ll examine the framework’s components and discuss the strategies organizations can implement to mitigate SPOF-associated risks.
What is a SPOF?
Before diving into the framework, let’s define what an SPOF is. A Single Point of Failure or SPOF refers to any component, process, or dependency within a system that, if it fails, has the potential to bring down the entire service or system. The consequences of SPOFs range from service outages and data loss to poor customer experiences and financial repercussions. Therefore, identifying and mitigating these vulnerabilities proactively is critical.
The SPOF framework: a structured approach
Root Cause Learning & Analysis (RCA) is a key component of our incident management process, where we investigate the “5 why’s” surrounding an incident. We discovered that while the root cause/event varied from incident to incident, the impact would have been significantly mitigated if sufficient resiliency and redundancy had been in place.
This realization led us to develop a structured approach for enhancing redundancy and resiliency, and thus, the following framework was conceived.
SPOF identification
Effective management of SPOFs begins with thorough identification. This encompasses analyzing both existing and new services/features planned for launch.
Where to start: architectural visibility
- Begin with clear, consistent architecture documentation. Every system—whether in production or development—should be represented in diagrams, ideally using a standard like the C4 Model. These diagrams should capture internal and external dependencies, along with the flow of data.
- Once the architecture is in place, apply a SPOF questionnaire or checklist to each major component. The goal is to evaluate how critical each element is and understand what happens if it fails.
SPOF discovery in practice
Depending on whether you’re dealing with existing systems or launching something new, your approach will vary slightly:
- Existing Services
- Periodic architecture review: Regularly review the architecture to identify components that could lead to service interruption upon failure.
- Dependency mapping: Create a clear visual representation of dependencies using a Configuration Management Database (CMDB) to pinpoint weaknesses efficiently.
- Problem management coordination: Collaborate with Site Reliability Engineers (SRE) to review incident reports for potential weak points.
- Chaos engineering: Simulate failures to observe system behavior and uncover hidden vulnerabilities.
- New Services/Features
- For new launches, SPOF analysis should be included as part of the SaaS production readiness launch checklist. This includes:
- Launch coordination checklist: Ensure the team evaluates architectural considerations before going live.
- Advocating Chaos engineering as SDLC phase gates during the development stages of product.
- Automated testing: Implement rigorous testing protocols to assess resilience against failures.
- Documentation: Maintain up-to-date documentation of identified SPOFs and their mitigation strategies for future reference.
- For new launches, SPOF analysis should be included as part of the SaaS production readiness launch checklist. This includes:
SPOF assessment & setting a Risk Registry
A Risk Registry: prioritize, collaborate, and track
Just like in any well-run program, managing Single Points of Failure starts with a solid foundation: tracking open items and prioritizing them effectively. Without clear visibility and prioritization, it’s easy for SPOF-related risks to fall through the cracks—until they show up as incidents.
Handling SPOFs isn’t just a technical exercise—it’s a cross-functional effort. It requires working closely with stakeholders to understand the risk-to-cost ratio of addressing (or deferring) each SPOF. Once you have that context, you can assign a risk score, tag related incidents, and begin prioritizing based on actual impact and business alignment.
A comprehensive Risk Registry plays a key role here. It should pull in risks identified from various identification sources mentioned:
- Chaos engineering experiments
- Root causes from past incidents
- Risk analysis checklists during the onboarding of new services or features
The registry must contain the following key attributes to successfully classify the risk and priority
- Impact Score: Calculate the impact of potential SPOF failures on operations, data integrity, customer experience, and financial outcomes.
- Likelihood Assessment: Evaluate how likely it is that a SPOF will occur, using historical data and industry benchmarks.
- Risk Scoring: A multitude of Single Points of Failure (SPOFs) may manifest within a given component. Consequently, a prioritization process is essential to discern the most critical SPOFs requiring immediate attention. The following table provides a framework for calculating the SPOF risk score, based on the probability of occurrence and the resultant impact. Prioritization should be faster the higher the risk score.
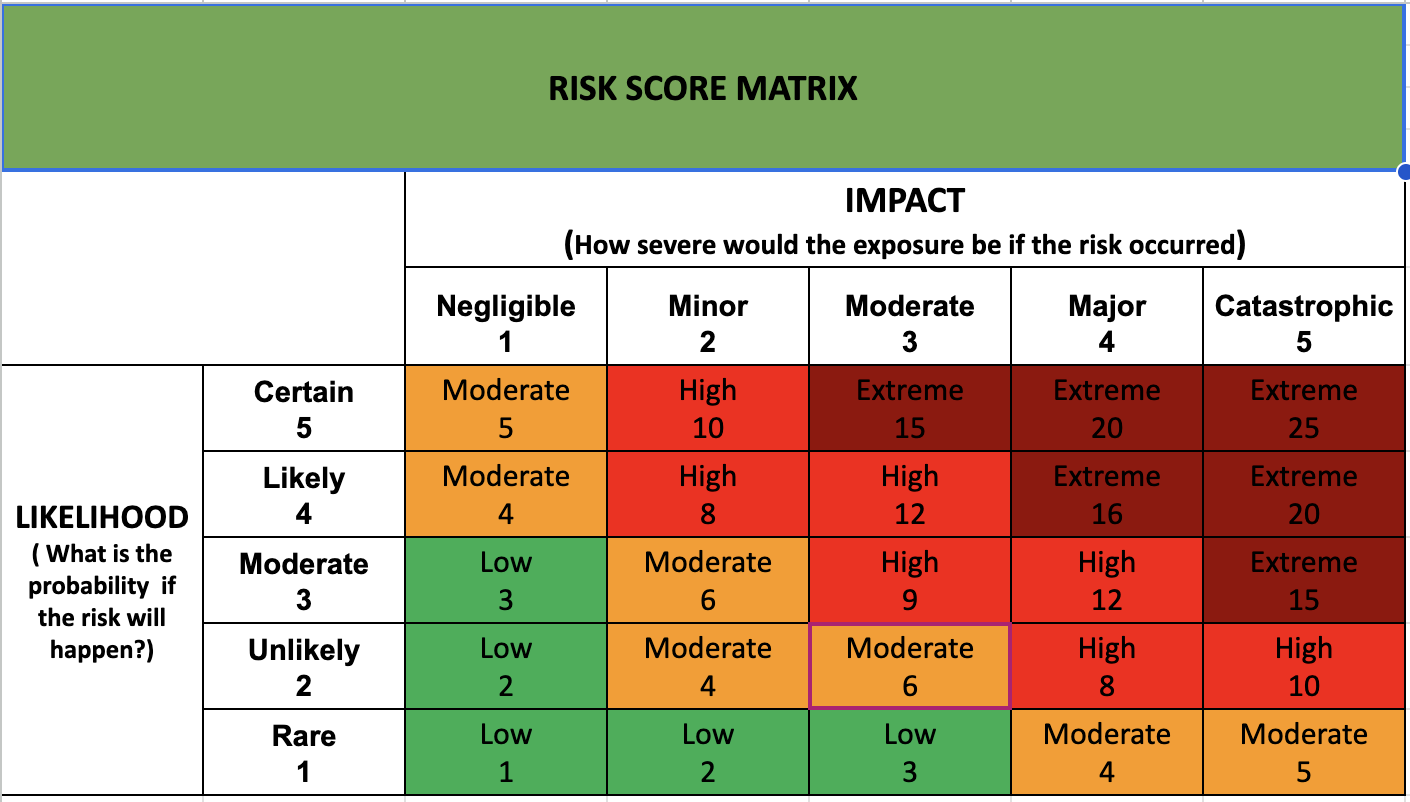
SPOF mitigation strategies
After assessment, organizations should prioritize and implement risk mitigation strategies, tailored to the specific type of SPOF. Here are some key strategies:
Infrastructure SPOFs
- Redundancy: Build redundancy into critical components to ensure that a secondary/sharded instance can take over when needed.
- Load Balancing: Distribute workloads evenly across servers to mitigate the risk of overload.
- Failover Mechanisms: Design automatic switch-over systems to ensure continuity during failures.
- Regular Maintenance: Implement routine checks to identify and resolve potential issues preemptively.
Application SPOFs
- High Availability & Load Balancing: Ensure applications are configured for high availability and are supported by load balancing.
- Partial Functionality Modes: Implement systems that allow limited service during full outages, minimizing user disruption.
- Retry and Circuit Breaker Patterns: Employ these software development patterns to enhance system resiliency in face of transient failures.
Program management & monitoring
Effective program management is vital. Here are a couple of things to consider when developing your program management and monitoring strategy:
- Utilize the SPOF Risk Registry Governance Board to manage the lifecycle of SPOF documented risk items
- Initiate a program plan: Product and engineering teams should create a detailed plan for implementing mitigation strategies or updating existing ones.
- Ongoing monitoring: Use analytics tools to monitor system health continuously for potential new SPOFs
Review & audit
Regular reviews and audits are essential to maintain the integrity of the SPOF framework. This could look like the following:
- Reliability risk reviews committee: Conduct regular meetings to reassess risks and discuss updates on mitigation efforts.
- Ad-Hoc and quarterly audits: Facilitate periodic architectural reviews to catch any newly introduced SPOFs or system changes.
- Incident Root Cause Analysis (RCA): Evaluate whether incidents qualify as SPOFs and initiate necessary risk management processes after the fact.
Conclusion
Understanding and managing Single Points of Failure is imperative for any SaaS organization striving to deliver consistent, reliable services to their customers. By adopting a thorough SPOF framework that includes identification, assessment, mitigation, and continuous monitoring, organizations can significantly bolster their resilience against potential threats, ensuring a consistent customer experience and sustained operational health.
As the SaaS landscape continues to grow and evolve, embracing a culture of continuous improvement around SPOFs will be fundamental in achieving long-term success. If you’re interested in learning more about JFrog’s highly resilient SaaS offerings, take a platform tour or start a free trial.


