

JFrog’s cloud migration story

By
7 min read

Since inception in 2008, JFrog has hosted its own development environments on-prem. While this approach worked well for a time, the increasing need to deploy faster, while sustaining high quality and reducing hosting costs made us realize that we needed to leverage the JFrog SaaS Production environment. So in 2022, we started an effort to migrate our RnD environments from an on-prem solution to JFrog SaaS Production.
We gained valuable experience throughout the migration process, which, when combined with our learnings from helping hundreds of clients migrate to JFrog SaaS over the years, we hope will be helpful information as you consider a migration to the cloud.
JFrog’s cloud migration background
JFrog develops its own products using the same products we sell to our customers. We use Artifactory to store the binaries, Xray to scan for vulnerabilities, Pipelines to run builds, Distribution to deploy releases, and so on. We use a JPD (JFrog Platform Development) with all of JFrog’s products. The system diagram below details our architecture:
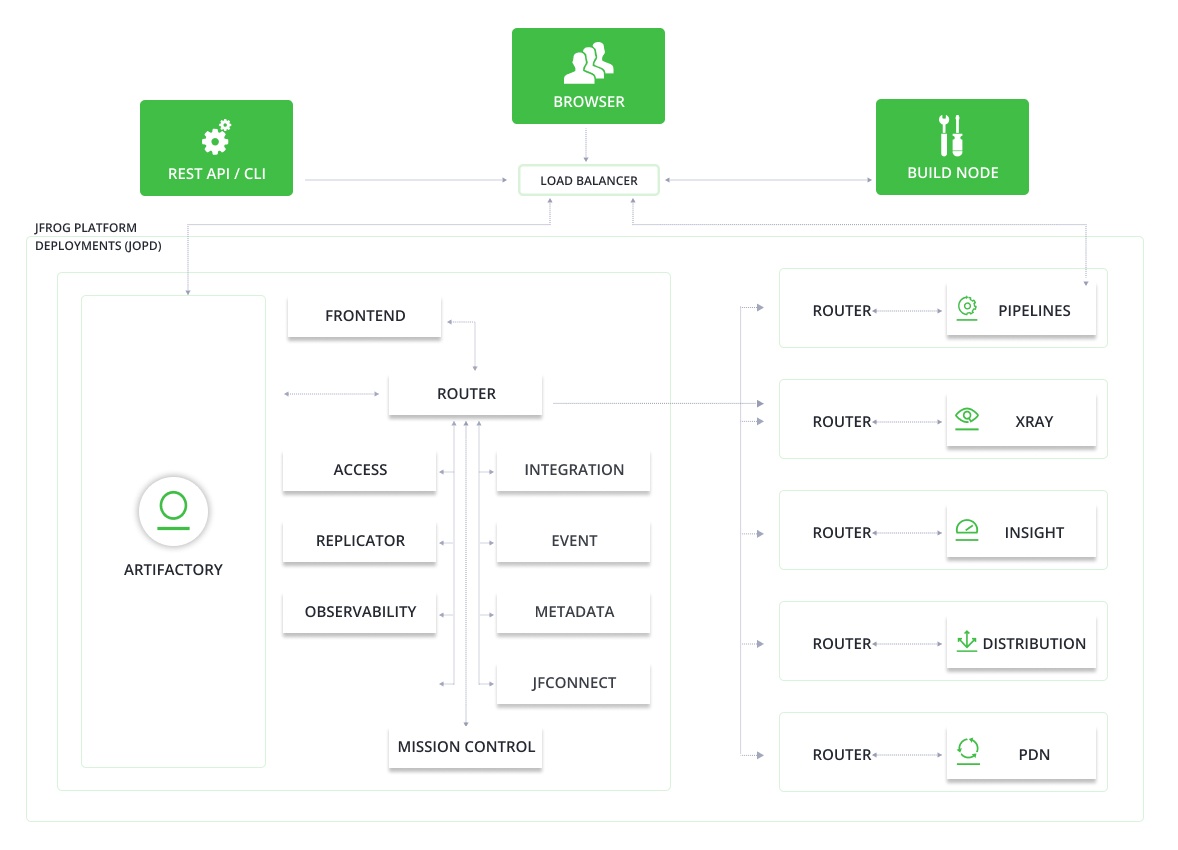
Schematic diagram of JFrog RnD environments
Despite its inevitable hiccups, the migration resulted in notable improvements in uptime, development productivity, and both time and cost efficiency. Here’s the impact of our cloud migration at a glance:
- Improvement in uptime: Uptime increased from 92-96% to 99.9%. This is a direct productivity gain, since it allows the same number of engineers to deliver more.
- Increased automation: One of the unique challenges JFrog faces is the need to support both on-prem customers with specific versions and customers using JFrog in the cloud/SaaS. This means that every change needs to be validated multiple times (i.e. the same test case needs to be validated with multiple versions).After migrating to the cloud and rebuilding our development environments, we were able to significantly increase automation. One of the measurements of this is data transfer as a result of automation, which grew from 50 terabytes to 850 terabytes in seven months.
- Time and cost savings: After migrating from self-hosted to JFrog SaaS, our hosting costs dropped 50%. Additionally, the new automation capabilities freed up time for the engineers. The same engineers who were once busy with ongoing maintenance are now able to focus on innovating within revamped dev environments.
Three main takeaways from JFrog’s cloud migration
No two cloud migration experiences will be the same. Every organization is different, and every instance of cloud migration will vary due to factors such as:
- The amount of data being transferred
- The infrastructure involved
- The teams that are impacted
- The amount of CI/CD flows to be migrated and their complexity
The list could go on. That said, there are three main takeaways from JFrog’s cloud migration experience that we’ve found to be particularly relevant for clients undergoing their own migrations.
Takeaway 1: The motivation behind cloud migration is often to free up time and resources for innovation and quality improvements.
One of the key reasons JFrog decided to migrate from self-hosted to JFrog cloud was to allow our DevOps team to focus more on innovation, velocity, and quality instead of maintenance tasks.
We also recognized the importance of having our engineers experience the same environment as our customers so they would see the benefits as well as the pains. This knowledge would help us drive better products to the market, because they’re based deeply in the customer experience. A high quality deployment benefits us and our customer, just as a bad deployment impacts us and our customer negatively. Aligned experiences = aligned incentives.
Takeaway 2: Before cloud migration, it’s crucial to consider the volume of data that needs to be moved and assess whether all of it is necessary for the new environment.
Before our migration, JFrog had 700 terabytes of data, which presented a significant challenge in terms of cost, time, and post-migration maintenance. We understood the importance of conducting a housekeeping operation to determine which data is essential for migration, asking ourselves, “Do we really need to migrate all 700 terabytes?”
It’s a challenge of cost and time, of course, but it’s also a challenge after the actual migration since it’s a lot to have to maintain. One way to approach this “clean up” process is to consider not migrating snapshots or repositories that haven’t gotten traffic for a very long time.
Here’s a quick glance at the data and machines we were working with that needed to be considered for the migration:
- Products: JFrog Artifactory, Xray, Pipelines, Distribution, Insight
- R&D team size: ~400 engineers
- Data, as shown below:
| Parameter | Nov 22 | Aug 23 | Improvement |
| S3 | 700 TB | 350 TB | -50% (less hosting) |
| Pipelines Build minutes | 3.2 million | 6 million | 87.5% |
| Uptime | 92%-96% | 99.9% | 8.5%-4% |
It can’t be emphasized enough how important it is to be mindful about what you choose to migrate and what you don’t. For instance, we discovered after the migration that some old snapshots were still being used in our operations, necessitating individual copies of these snapshots. That was a missed opportunity discovered too late.
Takeaway 3: Detailed planning, monitoring, and communication are essential for a smooth cloud migration process.
Detailed planning is critical, and should involve preparing for a security review and calculating the expected downtime. It’s also a good idea to assign a technical leader to the migration project and create a detailed transcript for the actual migration day.
During JFrog’s cloud migration, we also identified monitoring as a critical part of the migration process, particularly monitoring of the source to balance the load and avoid damaging the self-hosted source during migration. Think about how you monitor your on-prem; the CPU, the memory, the amount of threads, and all of the parameters you may already be monitoring.
Furthermore, communication with stakeholders is a crucial aspect of the process. In our case, this involved working closely with R&D leaders to ensure that any downtime didn’t impact critical deliverables.
Here’s a quick migration checklist you can use for reference:
Pre-Planning
- Engage R&D, network internally to get everyone on the same page
- Nominate a technical leader to the migration project
Planning
- Security, legal, and compliance review
- Housekeeping: I.e. Do we need to transfer all repositories?
- Calculate sizing: I.e. S3 bucket, daily creation date
- Monitoring: Plan monitors on source (DB’s, nodes)
- Calculate expected downtime and communicate
- Approve user acceptance test and be sure to cover all pipelines and repositories
- Take time for critical pipelines (know build times, per hour, peak)
Execution
- Run according to acceptance test
- Monitor source to avoid overload
- Plan a downtime
- Perform the cutlines and build a detailed transcript (you may have dependencies)
Post migration
- Make sure all pipelines work
For more detailed step-by-step information, be sure to check out our cloud migration checklist.
Recap
If all of this is a lot to digest at once, don’t worry. Here are a few key insights to take with you:
- Cloud migration can be labor-intensive and may require significant time and resources upfront.
- The main driver for JFrog’s migration was to free up our DevOps team to focus on innovation, velocity, and quality – also very common drivers among our customers.
- We had to engage our R&D teams to ensure a smooth migration and to avoid disrupting their work.
- Monitoring the source was crucial during the migration to ensure the system wasn’t overloaded.
- A detailed plan and transcript for the migration day were essential for a successful migration.
I hope you’ve gained some helpful insights from what I’ve shared here. To learn more about JFrog on AWS, GCP, or Azure, visit https://jfrog.com/find-a-partner/. If you’re ready to take the next step with a free cloud trial, head to https://jfrog.com/start-free/.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



