

The Dependency Dilemma: Balancing Innovation Speed with Supply Chain Resilience
Most of What Ships Today, Your Team Didn't Write

By
7 min read
Sponsored by JFrog ~

Development teams are shipping faster than ever. Generative AI coding assistants, early agentic workflows, and increasingly modular architectures have compressed the distance between concept and deployment. AI-enabled innovation has become an executive mandate, and teams are expected to deliver at speed without sacrificing security or compliance.
At the same time, modern applications depend heavily on third-party components: open source packages, container images, external services, and increasingly, AI models. Agentic systems add to that dependency chain while also consuming from it, pulling in open source packages and libraries as part of their own workflows. Organizations recognize this dependency. Nearly 70% of organizations describe open source software as very important or critical to business operations, according to IDC’s Open Source Software Use Survey (July 2025).
When speed and external dependencies compound, teams end up consuming components faster than they can evaluate them. And attackers know it.
Supply Chain Attacks Are Getting Smarter
Two incidents from 2025 illustrate what happens when that gap gets exploited.
- The Shai-Hulud attack didn’t happen all at once. It unfolded in multiple waves across the npm ecosystem, with hundreds of compromised packages designed to harvest developer credentials from source control and cloud environments. The scale was significant, but the campaign’s persistence was what made it dangerous. Each wave used more sophisticated obfuscation than the last, engineered to evade the detection tools that caught earlier variants. Many teams didn’t realize they were exposed until well after the compromised packages had been consumed.
- The React2Shell vulnerabilities (CVE-2025-55182 and CVE-2025-66478) demonstrated a different failure mode. A critical remote code execution condition in React and Next.js allowed malicious HTTP requests to execute arbitrary code under certain configurations. Many applications had been scaffolded using default templates, which meant teams were exposed without ever making a deliberate decision to accept the risk. Organizations without centralized control over dependency versions found themselves relying on distributed, manual remediation across hundreds of projects.
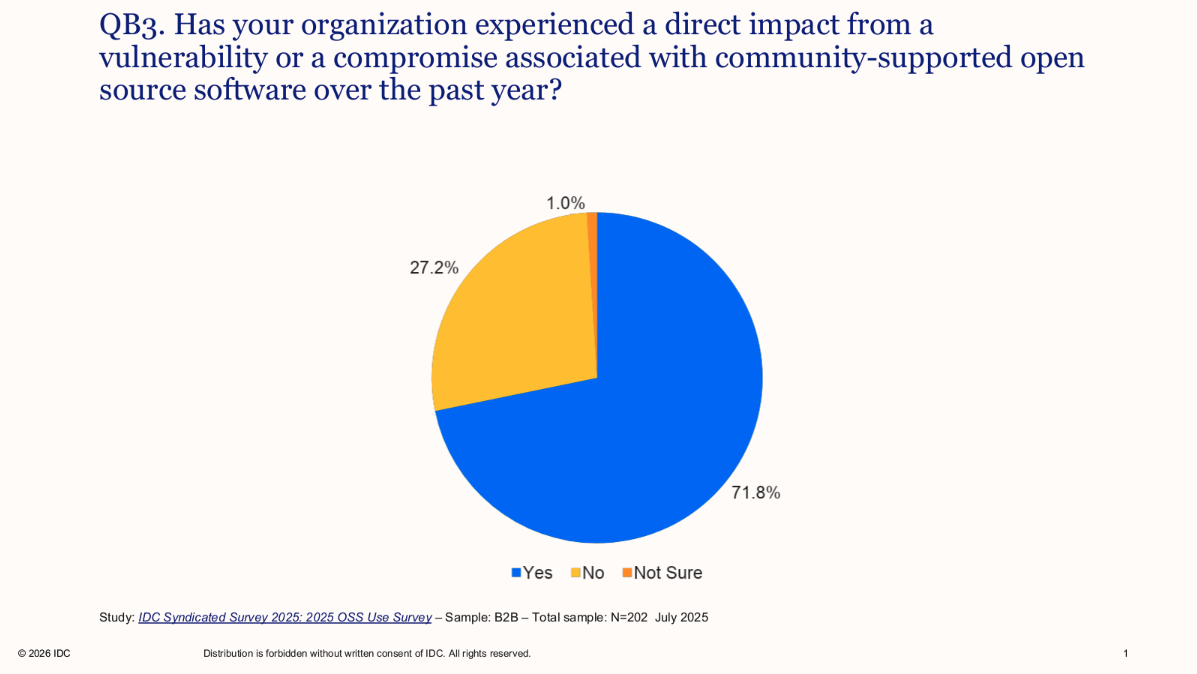
The gap between artifact publication and detection creates an opportunity for adversaries, and widely adopted components introduce systemic exposure when updates are consumed without vetting. IDC data confirms the breadth of the problem: 71.8% of organizations report a direct impact from a vulnerability or compromise in community-supported open source software in the past year (IDC’s Open Source Software Use Survey, July 2025).
Where Should Trust Start in the Software Pipeline?
Organizations are rethinking where trust gets established in the software pipeline. Rather than treating security as something applied after integration (scan, find, fix, repeat), they’re building layered controls that start at the point where third-party code and software packages first enter the environment. That means assessing known vulnerabilities, licensing alignment, project health, and maturity thresholds at the point of entry, and restricting what doesn’t meet defined standards to curate software properly.
Traditional governance approaches, centered on policy documentation and compliance guidance, weren’t designed for real-time enforcement. In an AI-accelerated environment, policy documents alone can’t intercept a newly published package before it enters a build pipeline.
Automated, policy-driven dependency controls can. These controls operate at the point of request, evaluating components before they’re ever cached in a repository or available for use. They sit in the IDE and across package consumption paths, vetting dependencies and extensions before developers can install them. Policies can block newly published packages until they meet aging criteria, restrict versions with known critical vulnerabilities, enforce approved licensing models, and surface vetted alternatives when a requested component doesn’t qualify. Governance runs in line with how developers already work, not alongside it.
The Same Risk, New Surface
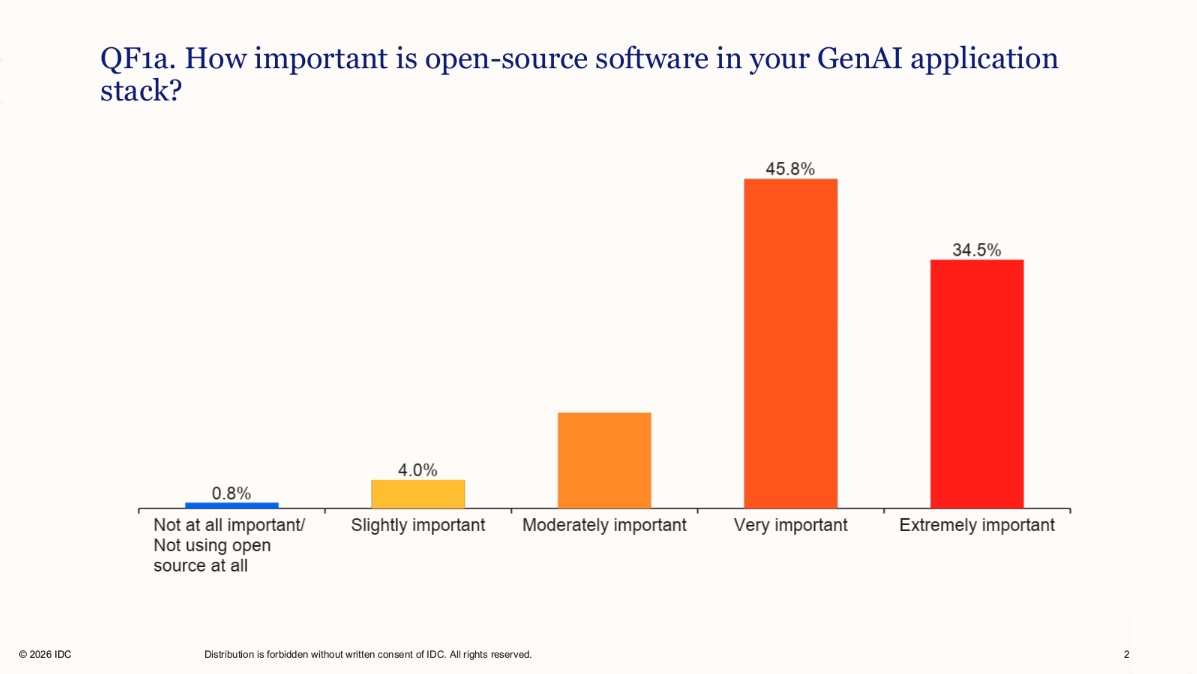
The urgency doesn’t stop at traditional application libraries. Open source is also foundational to enterprise AI initiatives, and 80% of organizations consider open-source components very or extremely important within their GenAI application stack, according to IDC’s Global AI Technology Trends Survey (June 2025). As AI models, frameworks, and supporting tooling get incorporated into production applications, the dependency risk profile expands with them.
AI coding assistants intensify this further. These tools suggest libraries and generate integration logic at speeds that outpace conventional review practices. The productivity gains are real, but so is the risk of introducing immature, poorly maintained, or unvetted components. Open source AI models carry the same structural risks as open source libraries, but the tooling and governance practices for managing them are far less mature. The emerging ecosystem of agent skills, packaged instructions, and scripts that agents load on demand introduces yet another category of dependency that requires the same scrutiny. Organizations extending these controls to cover AI components aren’t overreacting. They’re applying a lesson the application security community has already learned the hard way.
How Do Organizations Achieve Both Velocity and Governance?
Despite strong executive enthusiasm for AI deployment, security concerns continue to shape rollout timelines. IDC’s AI Tech Buyer Survey (April 2025) indicates that security vulnerabilities from autonomous actions (26.2%) and data privacy breaches (24.1%) rank as the top business risks associated with agentic AI adoption. How an organization handles dependency intake has become a practical differentiator.
The instinct is to treat this as a black-and-white decision: Either lock everything down or accept the risk. Organizations that get this right reject that framing. They treat intake governance as a calibration problem, setting trust thresholds that are strict enough to block known-bad or unvetted components but specific enough that developers aren’t stuck waiting for approvals. When a policy does block a dependency, the developer gets redirected to the latest version that meets compliance and security requirements rather than hitting a dead end. The goal is to make the secure path the path of least resistance.
Preventive dependency controls don’t replace vulnerability management, runtime monitoring, or incident response. They represent the foundational layer of a broader trust stack designed for the speed at which software now gets built. As development becomes more autonomous, each layer (intake, build, deployment, and runtime) needs to reinforce the others.
The Clock Is Already Running
The dependencies your teams consume today define the risk surface your organization manages tomorrow. Engineering trust at the point of intake through automated, policy-driven controls embedded in developer workflows is the operational prerequisite for scaling AI-driven development without scaling risk alongside it.
Moving fast only counts if you can trust what you’re building and deploying with.
Message from the Sponsor
Effective software supply chain security requires managing the risks associated with third-party components before they enter the development environment. JFrog Curation provides automated, policy-driven dependency controls that vet open-source packages, MCP servers, and AI models before they ever enter your organization. By evaluating components against security, licensing, and maturity standards, it enables organizations to block malicious or non-compliant packages without interrupting AI-powered developer workflows.


