

Expanding Artifactory’s Hugging Face Support with Datasets

By
3 min read
When working with ML models, it’s fair to say that a model is only as good as the data it was trained on. Training and testing models on quality datasets of an appropriate size is essential for model performance.
Because of the intricate link between a model and the data it was trained on, it’s also important to be able to store datasets and versioned models together. This is why we’ve expanded Artifactory’s Hugging Face repositories to natively support both Hugging Face datasets and models.
Before we dive into Artifactory’s dataset support, let’s do a quick recap on Hugging Face.
What are Hugging Face Datasets?
Creating an appropriate dataset for model training can be difficult and costly, leading many AI developers to look for existing datasets they can use as-is or modify with little effort. Thankfully, the community has responded by creating and publishing thousands of datasets for use.
Hugging Face has emerged as a popular hub for AI developers and NLP practitioners to use for this very type of collaboration. It serves as a public registry offering pre-trained models, datasets, and tools.
Artifactory: your private data registry
As of version 7.90.1, Artifactory supports proxying Hugging Face Datasets for remote and local repositories, using the native Hugging Face Python library. Using Artifactory to cache datasets from Hugging Face ensures that your datasets, along with your models, are always consistent and reliable, and that they can be retrieved with the best performance.
Using Artifactory Hugging Face local repositories allows you to define fine-grain control of the access to your models and datasets and provide a single place to resolve and manage both assets.

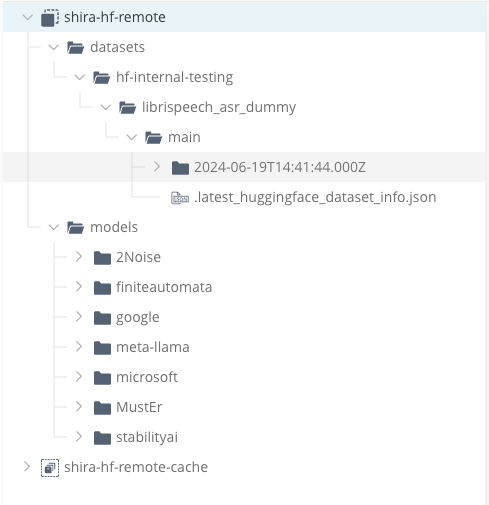
Dataset files stored in the same remote repository as models
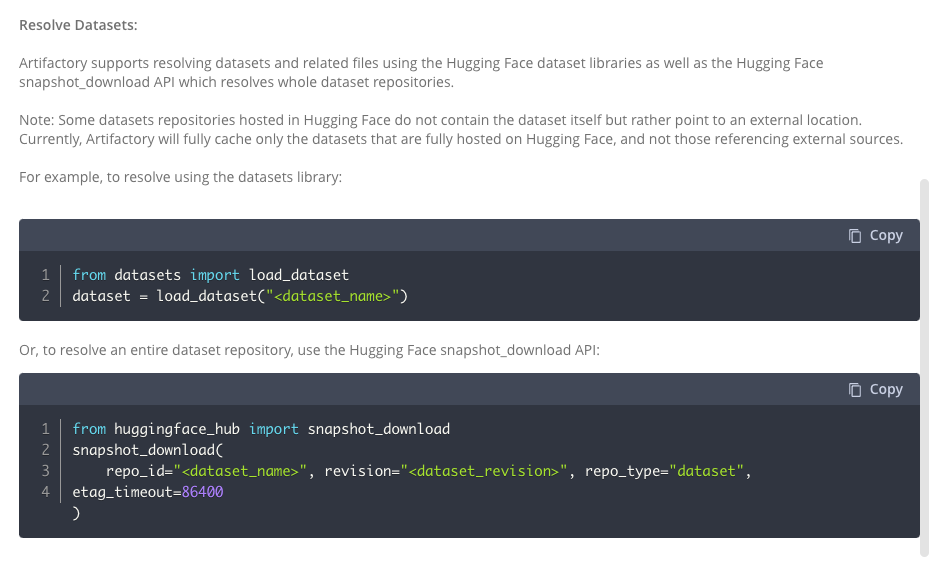 Set Me Up for resolving datasets with Artifactory Hugging Face repos
Set Me Up for resolving datasets with Artifactory Hugging Face repos
There are two ways Hugging Face stores datasets within their platform. The first is that the actual data files sit inside the Hugging Face registry. The second option occurs when the format of the data file cannot sit directly within Hugging Face and instead a Python script is provided to point and download the data from an external location. In these instances, JFrog will not cache the file and instead offer a pass-through.
What next?
We’ve got even more in the works! Up next for our Hugging Face support: better linking between the model and the dataset used to train it.
In the meantime, you can log into your JFrog account to start managing your datasets with JFrog. Not an Artifactory user, but want to see how it can help manage your machine learning models and datasets? Start a free 14-day trial.


