

Detecting Malicious Packages and How They Obfuscate Their Malicious Code
Malicious Software Packages Series Part 4 of 4: How malicious packages can be avoided and detected, and which obfuscation techniques they use to hide malicious code

By
14 min read

Wow! We made it to the last post in our Malicious Packages series. While parting is such sweet sorrow, we hope blogs one, two, and three provide insights into the havoc malicious packages cause throughout your DevOps and DevSecOps pipelines.
In the prior posts:
- We explained what software supply chain attacks are and learned the critical role malicious software packages play in them.
- We presented infection methods attackers use to spread malicious packages, and how the JFrog Security research team unveiled them.
- We discussed the aftermath of a successful attack and how attackers execute payloads in malicious packages to serve their needs. We demonstrated this using payloads from real-life malicious packages disclosed by JFrog Security.
Now let’s get to know attackers’ other, more discreet interests when creating a malicious package: hiding malicious code, and finally showing how malicious packages can be detected and prevented.
- Obfuscation techniques attackers use to hide payloads in malicious packages
- How to identify known and unknown malicious packages
- Best practices for secure development to avoid malicious packages
Obfuscation techniques attackers use to hide payloads in malicious packages
Besides performing a successful infection and payload execution, malicious package authors would want to avoid detecting their malicious activity.
To achieve a reasonable success rate of an attack, attackers would like to avoid detection by code analysis security tools and make it hard for security researchers to reverse engineer their malicious packages. A widespread technique for achieving these goals is using code obfuscation, which is the process of modifying an executable so that it is no longer useful to a hacker. However, it remains fully functional.
We’ll discuss several code obfuscation techniques, including off-the-shelf public obfuscators, custom obfuscation techniques, and the invisible backdoors technique, which isn’t necessarily an obfuscation method by itself, but rather a technique to invisibly change the source code logic without producing visual artifacts.
Public obfuscator example: python-obfuscator library
In July 2021, JFrog security researchers detected a malicious package called noblesse that used a public popular Python obfuscator, simply called Python obfuscation tool. The obfuscation mechanism used in this tool is a simple encoding of Python code with base64, decoding it at runtime, compiling it, and executing it.
import base64, codecs
magic = 'cHJpbnQ'
love = 'bVxuyoT'
god = 'xvIHdvc'
destiny = 'zkxVFVc'
joy = '\x72\x6f\x74\x31\x33'
trust = eval('\x6d\x61\x67\x69\x63') + eval('\x63\x6f\x64\x65\x63\x73\x2e\x64\x65\x63\x6f\x64\x65\x28\x6c\x6f\x76\x65\x2c\x20\x6a\x6f\x79\x29') + eval('\x67\x6f\x64') + eval('\x63\x6f\x64\x65\x63\x73\x2e\x64\x65\x63\x6f\x64\x65\x28\x64\x65\x73\x74\x69\x6e\x79\x2c\x20\x6a\x6f\x79\x29')
eval(compile(base64.b64decode(eval('\x74\x72\x75\x73\x74')),'<string>','exec'))In the code snippet above, we can see an example of a Hello world print, that was obfuscated automatically with this tool. We can see the usage of base64 strings, the decoding of them with b64decode() function, and the compile() and eval() calls that execute the decoded code.
This obfuscation trick can fool a simple static analysis tool, but not a more thorough analysis tool. For example, our automatic malicious code detectors are aware of this simple obfuscation technique and flag the obfuscated code.
The control flow flattening obfuscation technique
Control flow flattening is a technique in which the code’s control flow structure breaks into blocks that are put next to each other instead of their original nested levels.
In December 2021, JFfrog security researchers detected a malicious package called discord-lofy that used a combination of several obfuscation techniques. One of them is control flow flattening. The payload in this package was a Discord token grabber, and typosquatting and trojan infection methods helped spread it.
We can look at this technique with an example from the published paper Obfuscating C++ Programs via Control Flow Flattening that explained this method with a simple example in the diagram below:
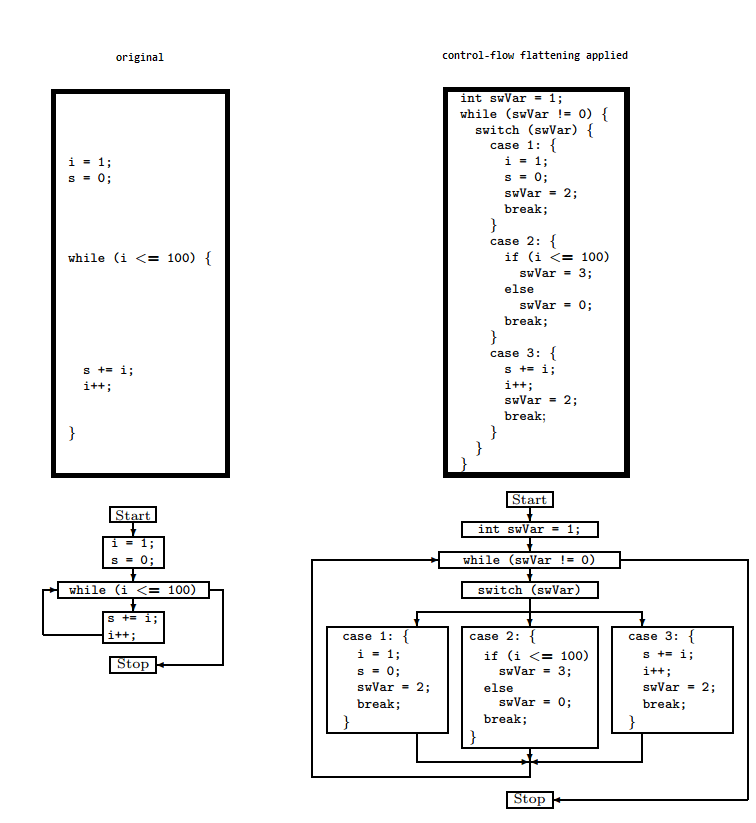
Look at the original code on the left side of the diagram; we can split it into three code blocks. First, we have variables initialization, then a while loop with a break condition, and finally, the code block inside the while loop.
You can see the code on the right side after applying the obfuscation. The three code blocks were flattened, and a switch case is used to control the flow of the code. A newly added variable swVar holds the number of the code block that’s executed. Also, at the end of each code block, its value changes to indicate the next block that should run.
Using homoglyph characters to hide malicious code
The homoglyph characters method isn’t an obfuscator by itself, but it can be used to hide malicious code modifications in legitimate software packages. This technique was published in the TrojanSource paper and demonstrates the possibility of changing source code invisibly. In other words, the logic of the code changes to contain a vulnerability or malicious code, for example, without producing any visual artifacts.
In this technique, attackers can use Unicode characters that look like standard ASCII Latin characters that an average reader would overlook. Still, the compiler or the interpreter will treat them differently, so the logic of the code changes.
Supply-chain attackers can use this technique to plant invisible backdoors into popular source code repositories. For example, an attacker might change a string literal check or a function call to make it always succeed or fail invisibly by changing one of the string’s characters to a homoglyph.
In the following code snippet example below, the two functions appear identical. However, the bottom function name uses the Cyrillic H character, which counts as a completely different function name. A code later in the program may call any of these two functions in an indistinguishable manner.
void sayHello() {
std::cout << "Hello, World!\n";
}
void sayНello() {
std::cout << "Bye, World!\n";
}
Using bidirectional control characters to hide malicious code
Another invisible method introduced in the TrojanSource paper was the Unicode bidirectional (or BiDi) control characters. These characters control text flow (either left-to-right or right-to-left). When using BiDi control characters in a source code, the Unicode encoding can produce strange artifacts, such as a source code line that visually appears in one way but is parsed by the compiler in another.
For example, look at this original code snippet below:
int main() {
bool isAdmin = false;
/* begin admins only */ if (isAdmin) {
printf("You are an admin.\n");
/* end admins only */ }
return 0;
}For the reader, the code appears not to print “You are an admin” since isAdmin = false. However, as seen in the snippet below, suppose the Unicode BiDi control character inserts in the correct position in the condition check. In that case, the compiler could interpret the condition check line as a full comment so the entire check can be bypassed.
When inserting a BiDi character in the condition check:
int main() {
bool isAdmin = false;
`/* begin admins only if (isAdmin) */ {`
printf("You are an admin.\n");
/* end admins only */ }
return 0;
}Anti-Debug techniques
In addition to code obfuscations, attackers make the analysis processes of researchers and automation tools more difficult by also detecting debugging tools as part of the malicious code.
For the first time, JFrog Security researchers found and disclosed a malicious Python package called cookiezlog that used this kind of anti-debug technique. Among known obfuscation techniques like PyArmor and code compression, it was found that the package used an open source Anti-debugger for Python called Advanced-Anti-Debug.
One of the functions of this Anti-debugger called check_processes() and its purpose is to look whether a debugger process runs on the system by comparing the active process list to the list of over 50 known tools, including the following:
- “idau64.exe” (IDA Pro Disassembler)
- “x64dbg.exe” (x64dbg Debugger)
- “Windbg.exe” (WinDbg Debugger)
- “Devenv.exe” (Visual Studio IDE)
- “Processhacker.exe” (Process Hacker)
PROCNAMES = [
"ProcessHacker.exe",
"httpdebuggerui.exe",
"wireshark.exe",
"fiddler.exe",
"regedit.exe",
...
]
for proc in psutil.process_iter():
if proc.name() in PROCNAMES:
proc.kill()If any of these processes are running, the Anti-Debug code tries to kill the process via psutil.Process.kill. Read our full analysis of this Anti-debugger in our latest blog.
Now that we know the technical information of the infection, payload, obfuscation, and anti-debug techniques used in malicious packages, let’s finally discuss methods to detect malicious packages in the software development life cycle (SDLC).
How to identify known and unknown malicious packages
Detecting known malicious packages
Let’s start with detecting known malicious packages.
To get a complete picture of the malicious packages in our projects, we essentially need to list our project’s dependencies and detect all of the installed third-party software versions in our project. The artifact of this process is called the software bill of materials (SBOM), which includes information on the installed third-party software.
We can use the SBOM to query public repositories and check if the third-party software packages we use are malicious or not. If we take PyPI or npm for example, these repositories define processes in which users can report malicious packages. To check for known malicious packages, the most efficient way is to query those repositories.
Unfortunately, there are two problems when implementing this process. The first problem is that many repositories don’t save historical data. For example, in PyPI malicious packages are removed from the repository when confirmed as malicious, leaving no way to tell if a package or specific versions of it were detected as malicious in the past. Below is a screenshot of a malicious package called ecopwer we disclosed last year. As of today, there’s no evidence for this package when searching for it in PyPI:

The tracking in npm is slightly better. Reported malicious packages are replaced with dummy code and they’re tagged as a Security holding package, as you can see in this screenshot below of a malicious package called colors-art in npm:
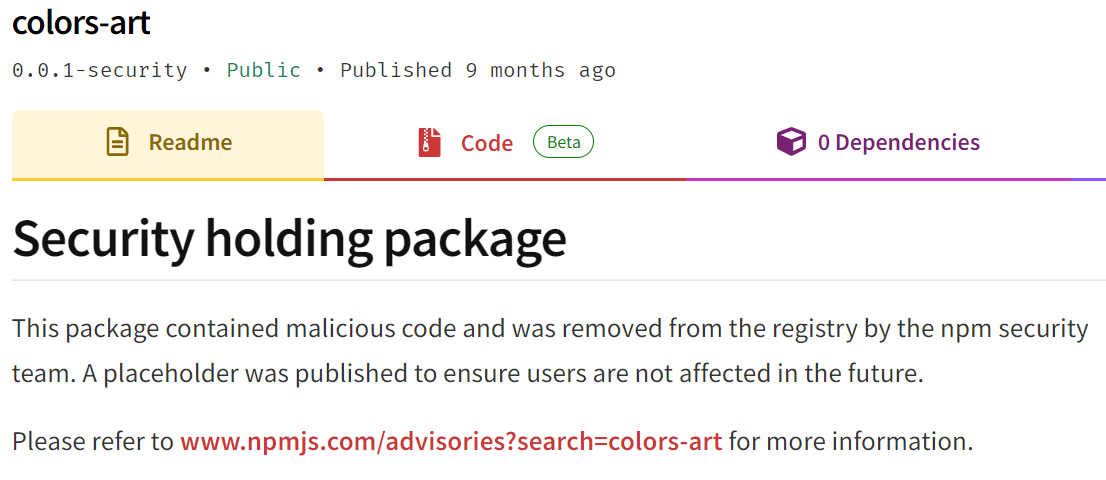
While this is good for tracking malicious packages, it’s not useful to track specific malicious versions of legitimate packages, because all versions are removed from the repository when they’re confirmed as malicious.
The second problem is that even if we would like to use the repositories’ data to scan for malicious packages, common security auditing tools report vulnerabilities but not malicious packages. For instance, take a look at the following result of executing the PyPI tool pip-audit after the malicious package ecopower was installed. The package couldn’t be scanned (as seen below) because it was removed from PyPI repository after it was reported as malicious:
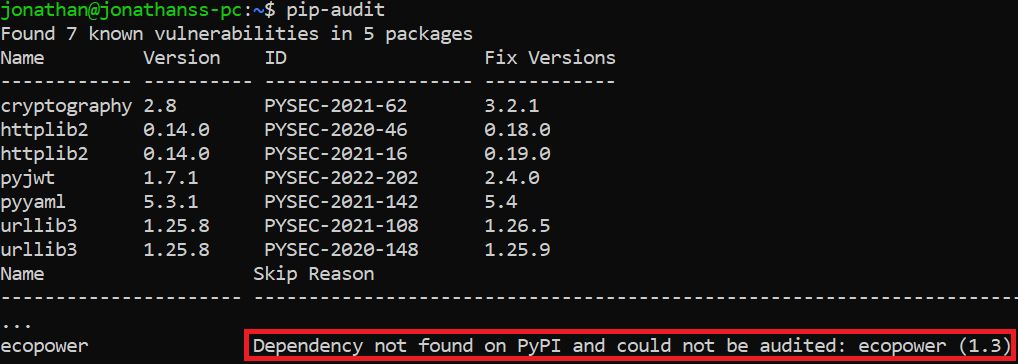
Because of these two problems and the fact that developers usually have to perform the audit process we just described in scale (i.e., as part of the SDLC), we essentially need to automate the process. This can be achieved by using a software composition analysis (SCA) tool integrated into our development and CI/CD process. It’s important to pick a security tool like JFrog Xray, that collects and stores malicious package names and versions in an internal database and doesn’t rely only on information from external repositories such as npm and PyPI, which do not save historical data as we saw.
Detecting unknown malicious packages
The detection of unknown malicious packages is considered much harder technically, because we essentially deal with unknown threats, similar to finding a zero-day in the field of vulnerabilities. To detect unknown malicious packages, we need to find a way of identifying characteristics of malicious packages before they’re known as malicious.
The approach we took when we developed JFrog Xray, isn’t just to update the Xray database with up-to-date known malicious package names and versions. But for detecting unknown malicious packages, we also develop and run heuristic scanners that scan software packages code in public repositories and detect anomalies in them. The scanners try to find evidence of malicious activity in any of the attack phases we discussed in this blog series — in the infection methods, in the payload phase, and also by detecting hiding methods or obfuscation techniques.
The ability of the scanners to provide alerts of possible unknown malicious packages makes them the foundation for all of the malicious packages we discover, research, and disclose. In this blog series, we thoroughly analyzed some of the malicious packages we discovered with this technique, as well as in other blogs we publish.
Here’s a list of scanners we developed. Keep in mind that it’s theoretically possible to develop a scanner for every phase of the attack, so try to think about this list as a list of demonstrations of heuristic techniques, this way you can think about more techniques if you’re interested in hunting unknown malicious packages.
Examples of scanners we developed:
- For detecting the dependency confusion infection method, we developed scanners that find packages with high version numbers on remote public repositories and alert on possible impersonations.
- For detecting Download & Execute payloads, we developed scanners that find code patterns of downloading a binary and executing it, using system functions we monitor in different languages.
- For detecting sensitive data stealer payloads, we developed scanners that find code patterns of access to sensitive locations in the file system, using system functions we monitor in different languages.
- For detecting obfuscation techniques, we developed scanners that alert on base64 decoding and other code characteristics of public obfuscators.
Best practices for secure development to avoid malicious packages
We’re nearing the end of the blog series, but we won’t end without giving you several best practices for secure development to deal with a malicious package security threat:
- The most important and basic method to deal with a malicious packages threat is to use a software composition analysis tool as part of your SDLC like JFrog Xray, or another software composition analysis tool.
- Define policies and automate actions as part of a DevSecOps process. If a malicious package is discovered in the process, it’s recommended to adopt a policy that breaks a build process and alerts the issue.
- For preventing the dependency confusion infection method, we would like to avoid automatic fetching of a high-version malicious package, unless we perform DevOps and DevSecOps tests on a new version of our published software. To achieve this, it’s recommended to configure your build system to exclude remote repositories for internal packages and to use strict versions for external dependencies for every build.
- Use open source tools to help detect malicious packages and prevent them from infecting your projects:
- Jfrog-npm-tools: Open source tools JFrog developed and published to the community for npm packages security.
- piproxy: A small proxy server JFrog developed for pip that modifies pip behavior to install external packages only if the package was not found on any internal repository. This fixes the Dependency Confusion issue in pip.
- npm_domain_check: A tool JFrog developed that detects npm dependencies that can be hijacked with domain takeover.
- Confused: This tool checks for dependency confusion vulnerabilities in multiple package management systems.
- PyPI-scan: This tool checks names similarity to find typosquatting packages.
- Pyrsia.io: A new open source initiative JFrog announced last year, for creating a secure, distributed peer-to-peer packages repository that provides integrity for software packages. The project uses blockchain technology to establish a chain of provenance for open source packages. Read more about this at pyrsia.io.
This post concludes our Malicious Packages blog series, but this isn’t a farewell.
Register for JFrog’s upcoming webinars to continue your education.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



