“Most large companies have multiple sites and it is critical for those companies to manage authentication and permission efficiently across locations. JFrog Enterprise+ will provide us with an ideal setup that will allow us to meet our rigorous requirements from the get go. It's advanced capabilities, like Access Federation, will reduce our overhead by keeping the users, permissions, and and groups in-sync between sites.”
Siva Mandadi
DevOps - Autonomous Driving, Mercedes
“JFrog Enterprise+ increases developer productivity and eliminates frustration. JFrog Distribution is basically a CDN On-Prem that enables us to distribute software to remote locations in a reliable way. Whereas, JFrog Access Federation gives us the ability to share credentials, access and group members across different locations with ease.”
Artem Semenov
Senior Manager for DevOps and Tooling,
Align Technology
"Instead of a 15-month cycle, today we can release virtually on request.”
Martin Eggenberger
Chief Architect,
Monster
“As a long-time DevOps engineer, I know how difficult it can be to keep track of the myriad of package types – legacy and new – that corporations have in their inventory. JFrog has always done a phenomenal job at keeping our team supported, efficient and operational – because if JFrog goes out, we might as well go home. Thankfully, with AWS infrastructure at our backs as well, we know we can develop and deliver with confidence anywhere our business demands today, and in the future.”
Joel Vasallo
Head of Cloud DevOps,
Redbox
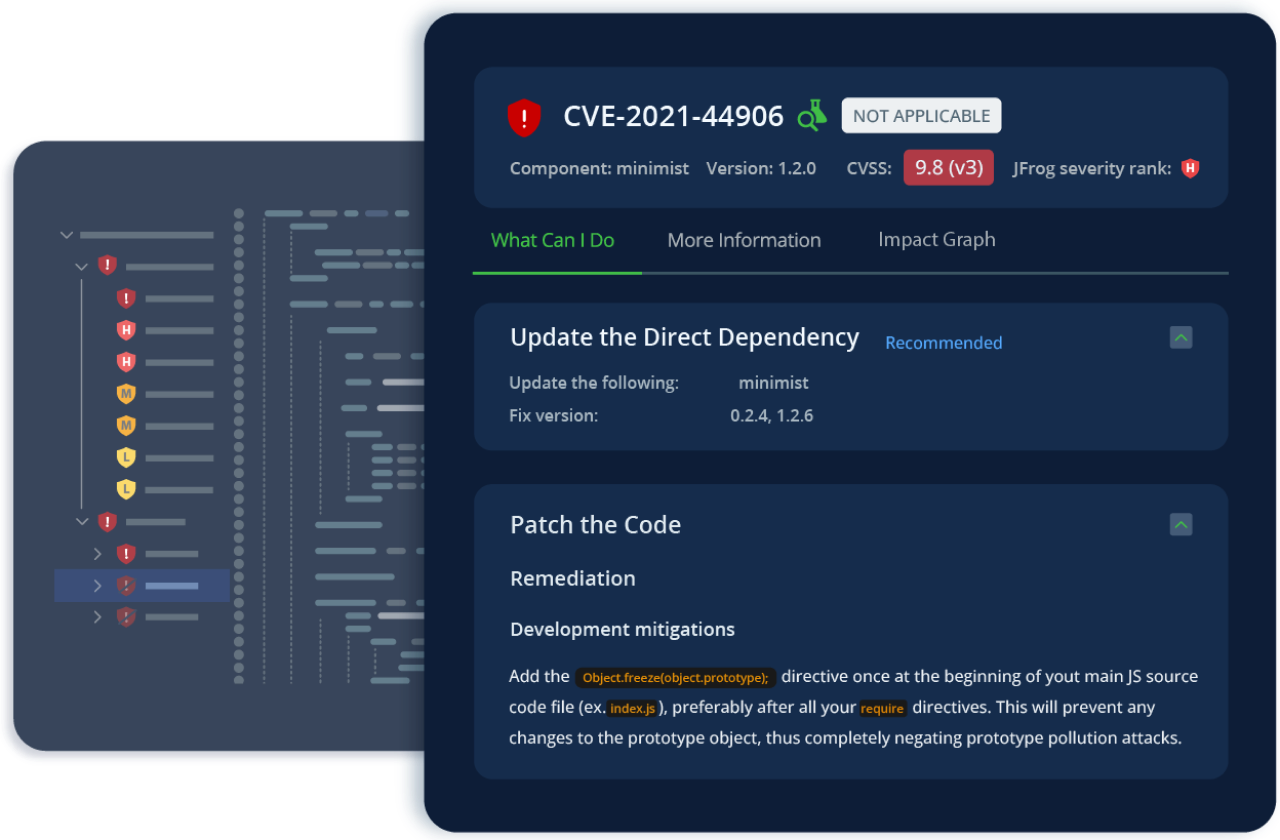
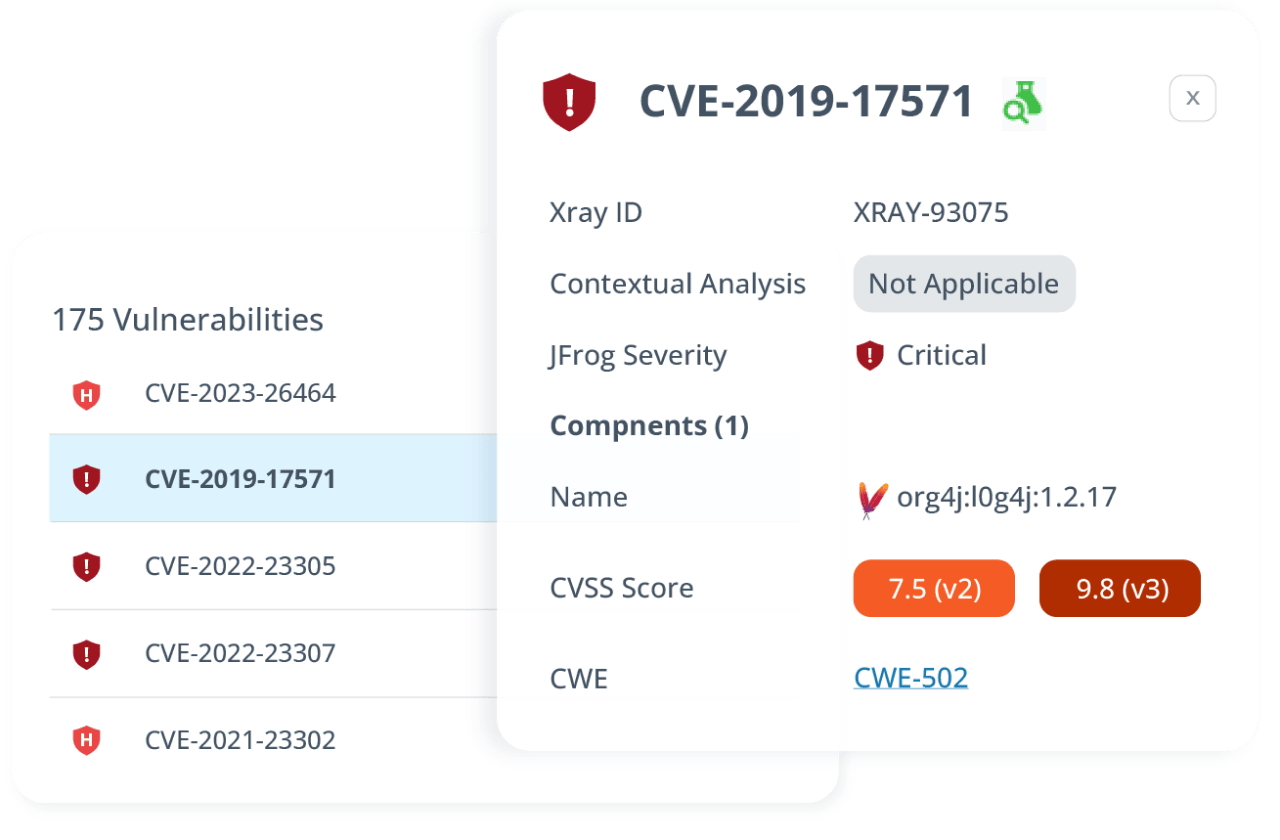
“When we had that issue with log4j, it was announced on Friday afternoon and [using JFrog] by Monday at noon we had all cities rolled out with the patch.”
Hanno Walischewski
Chief System Architect,
Yunex Traffic
“Among the lessons we learned from this compromise is, in general, you should arrange your system so you never build directly from the internet without any intervening scanning tool in place to validate the dependencies you bring into your builds. To this end, we use an instance of JFrog® Artifactory®, not the cloud service, to host our dependencies, which is the only valid source for any software artifacts bound for staging, production, or on-premises releases.”
Setting the New Standard in Secure Software Development:
The SolarWinds Next-Generation Build System
SolarWinds
"Since moving to Artifactory, our team has been able to cut down our maintenance burden significantly…we’re able to move on and be a more in depth DevOps organization."
Stefan Krause
Software Engineer,
Workiva
“Over 300,000 users around the world rely on PRTG to monitor vital parts of their different-sized networks. Therefore, it is our obligation to develop and enhance not only our software itself but also the security and release processes around it. JFrog helps us do this in the most efficient manner.”
Konstantin Wolff
Infrastructure Engineer,
Paessler AG
“JFrog Connect, for me, is really a scaling tool so I can deploy edge IoT integrations much quicker and manage them at a larger scale. There’s less manual, one-off intervention when connecting to different customer sites with different VPNs and firewall requirements.”
Ben Fussell
Systems Integration Engineer,
Ndustrial
"We wanted to figure out what can we really use instead of having five, six different applications. Maintaining them. Is there anything we can use as a single solution? And Artifactory came to the rescue. It really turned out to be a one-stop shop for us. It really provided everything that we need."
Keith Kreissl
Principal Developer,
Cars.com