

Not Built to Scale: The Hidden Fragility of Cloudsmith
In real-world DevOps, the question isn’t just how fast you can go, it’s how far you can scale without breaking.

Cloudsmith claims that they are an enterprise-ready solution, a platform designed to meet the needs of modern organizations at scale. On the surface, they “talk the talk”: reliability, performance, security, scalability — they even go as far as presenting themselves as an “infinitely-scalable alternative to JFrog”. However, when a vendor claims to be built for the enterprise, it’s worth asking: can they actually deliver at scale or under any enterprise demand?

What Cloudsmith claims on its website
We decided to take a closer look, not at the marketing fluff, but at the real-world behavior of the platform under stress. What happens when you’re not just pushing a few packages, but instead running full CI/CD pipelines, serving concurrent team requests, or distributing containers at volume?
We’ve put Cloudsmith to the test, and here’s what we found.
The Setup: Simulating Real Workflows
At JFrog, we support thousands of cloud customers who push the limits of scale every single day, running massive CI/CD pipelines, deploying containerized applications globally, and distributing software to fleets of devices at the edge. We know what enterprise-scale looks like because we live it daily.
So when it came time to evaluate Cloudsmith’s claims of being “enterprise-ready,” we didn’t rely on synthetic benchmarks or isolated lab tests. We built scenarios that mirror real engineering environments, including:
- Multiple concurrent workloads pulling and pushing artifacts across teams
- Container image traffic as part of full CI/CD workflows
- Stress scenarios involving 50–100 concurrent requests to simulate basic developer and automation load
And to be clear, we weren’t even pushing it to the limit. These were medium-scale tests, well within the range of what most teams would consider entry-level. However, even under these controlled conditions, cracks in Cloudsmith’s reliability began to appear.
We ran these tests on both JFrog and on Cloudsmith, under equivalent conditions.
Naive Testing: Painting the Target Around the Arrow
At a glance, things don’t look so bad. When we measured average upload and download speeds for individual packages, the differences between JFrog and Cloudsmith weren’t dramatic enough to make it a no-brainer. On the surface, it might seem like either platform could do the job if you’re only looking at isolated, low-load actions.
Let’s break down the numbers across a few common package types:
- Docker:
JFrog shows a clear lead in both ingress and egress, with an upload rate of 3.2MB/s versus Cloudsmith’s 1.4MB/s, and a download rate of 20.8MB/s compared to Cloudsmith’s 17.0MB/s. - Maven:
JFrog outperforms Cloudsmith in upload speed (0.8MB/s vs 0.1MB/s), while Cloudsmith has a slight edge in download (0.7MB/s vs 0.6MB/s). - NPM:
The platforms are evenly matched here, both delivering 1MB/s upload and 3MB/s download.
So, if you were to stop testing here, just benchmarking a single package at a time with no real-world load, you might walk away thinking it’s a fair fight. But that’s like shooting an arrow and then drawing a target around it.
This kind of naive testing ignores what actually happens in modern DevOps. Your pipelines don’t run in isolation, and neither should your performance benchmarks.
Modern pipelines don’t rely on single downloads. They depend on consistency, throughput, and stability under pressure.
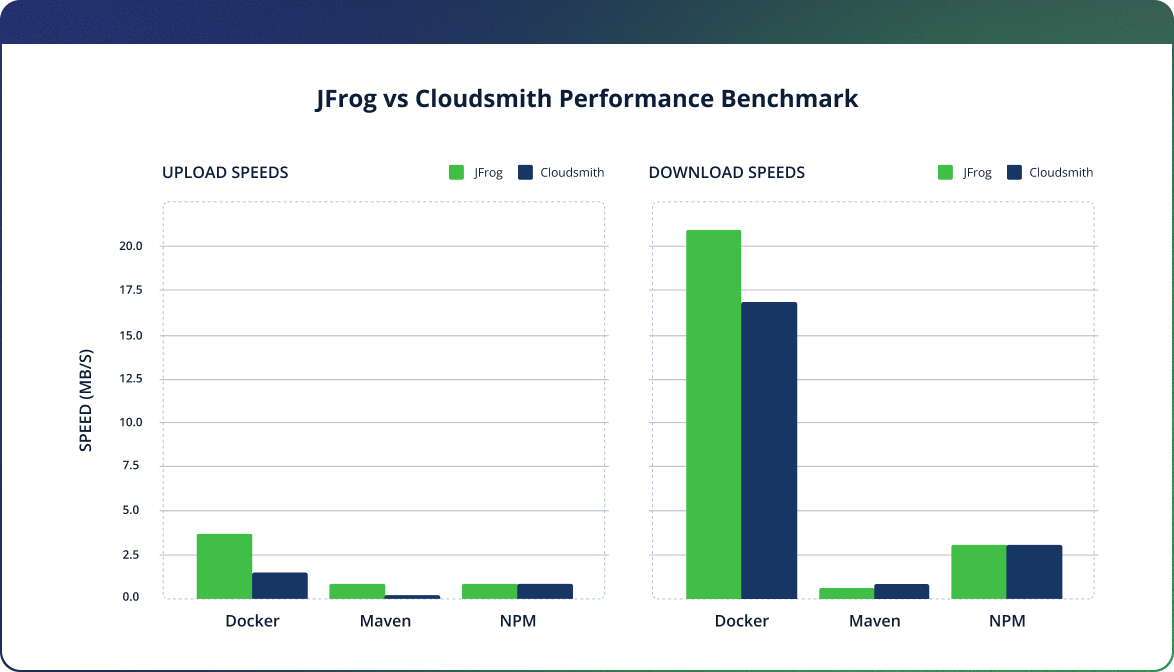 Comparison of upload and download speeds between JFrog and Cloudsmith.
Comparison of upload and download speeds between JFrog and Cloudsmith.
Under Load, Things Start to Break Down
We started simple, just a baseline test to simulate a typical day in the life of a development team. A handful of package pulls, some concurrent user activity, nothing out of the ordinary. Unsurprisingly, everything seemed fine. No red flags. No errors.
But enterprise environments don’t stop at “basic.”
So we pushed a little harder. We increased the pressure, 50 to 100 package pulls, running in parallel, simulating multiple developers or automated jobs, slightly hammering the system with realistic, entry-level workflows.
And that’s when things started to break consistently. That’s when Cloudsmith begins to falter.
- Timeouts occurred with as few as 1–2(!) concurrent threads
- Rate limiting kicked in at 180 requests per minute
- Uploads were blocked, pipelines slowed down, and the platform began returning 503 errors
Example failure message:
{"detail": "Request was throttled. Please wait 1 minute(s) before trying again."}
And just to be clear, we weren’t testing the free tier. This was a paid Cloudsmith Premium (Pro) plan tested against the equivalent Artifactory Cloud (Pro) plan, and we still hit a wall.
Need a higher limit? Better come prepared, with a detailed justification, and a crystal ball prediction of your future needs, so Cloudsmith can ‘take care of it.’
Cloudsmith may argue that their rate limits are documented and necessary, but there’s a difference between responsible usage controls and rate-limiting basic automation. At JFrog, we actively monitor for abuse and protect against unfair usage too, but we don’t block legitimate automation for paying customers running at just 3 requests per second. That’s not protection, it’s a signal that Cloudsmith doesn’t fully understand how automation operates in a modern organization delivering software, or that their cloud infrastructure is heavily under provisioned.
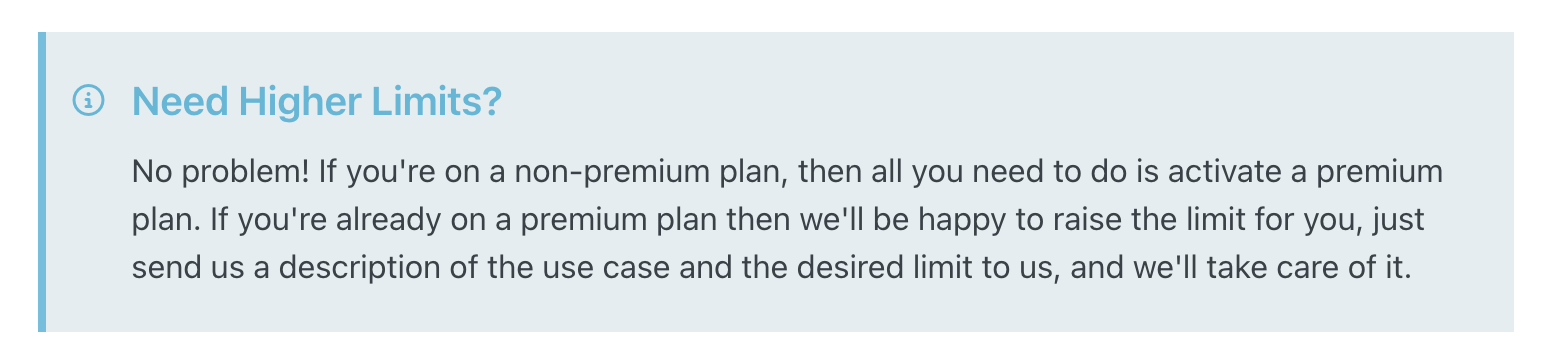
This message makes asking for more bandwidth seem like applying for a mortgage (Resource: Cloudsmith’s official documentation)
By contrast, JFrog Cloud remained stable and performant throughout the test, handling every request without a single failure, with what is considered low concurrency in our terms. Performance and stability remained consistent even under significantly increased concurrency and request volumes. And that’s not a one-time fluke: our SaaS platform handles tens of thousands of requests per second, globally, every single day.
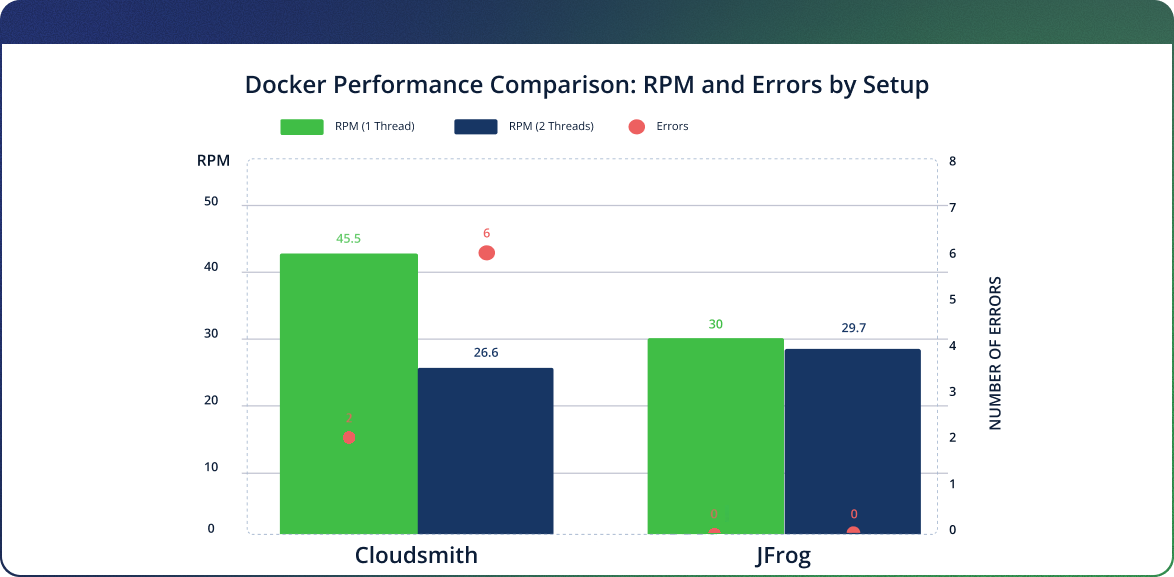 Docker Performance based on Request per Minute and number of threads
Docker Performance based on Request per Minute and number of threads
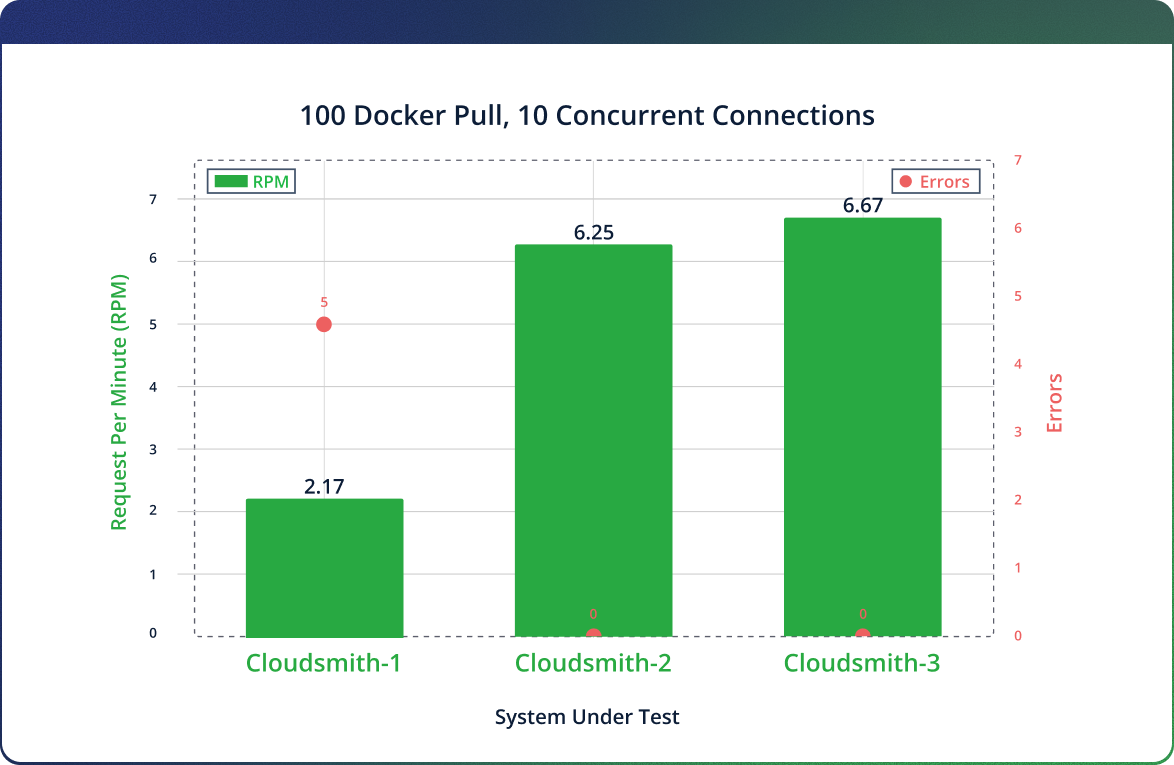 Cloudsmith’s first run fails with multiple errors, subsequent runs improve but reliability shouldn’t depend on warm-ups.
Cloudsmith’s first run fails with multiple errors, subsequent runs improve but reliability shouldn’t depend on warm-ups.
The Need for Speed – Cruising in a Single Lane
In enterprise environments, software delivery doesn’t happen at a trickle – it runs at full throttle. CI/CD pipelines are constantly in motion, with dozens or hundreds of processes pulling and pushing artifacts in parallel. Teams across the organization trigger builds, publish releases, and deploy updates, all at once, all the time.
This level of concurrency isn’t the exception – it’s the norm. And customers expect a SaaS artifact management system to keep up without hesitation. That means zero bottlenecks, no default throttling, and a platform that treats performance as non-negotiable.
When you entrust a vendor with the most critical assets in your software delivery process – your binaries, you expect it to work at any scale, under any load, without excuses.
And when your system throttles, times out, or blocks you mid-deployment, that’s not just a metric, it’s a blocker. It costs time, credibility, and customer trust.
- Cloudsmith throttles down requests at above 180 requests per minute
- JFrog Cloud scales with zero errors, no limits hit
You Had One Job – When Your Artifact Registry Breaks, So Does Your Entire Organization
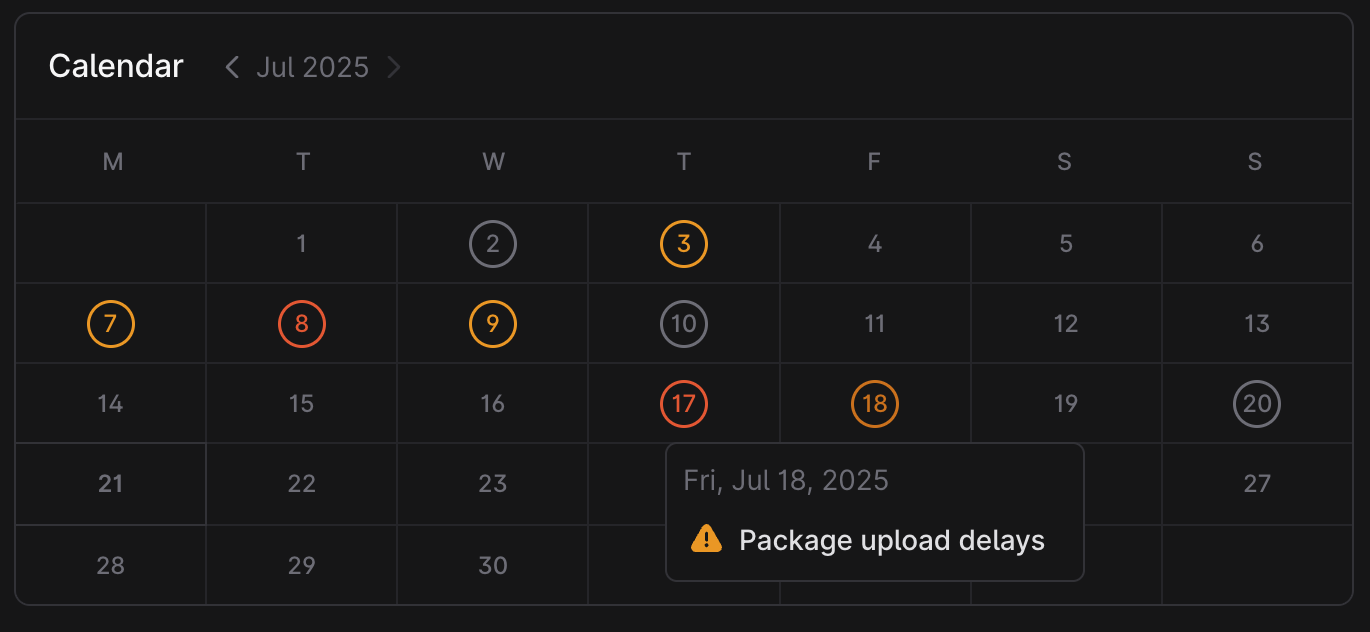 Cloudsmith’s Turbulent July – Incident Overview
Cloudsmith’s Turbulent July – Incident Overview
An artifact repository is more than just storage, it’s the backbone of modern software delivery. It sits at the heart of every build, test, deployment, and release pipeline. Organizations depend on it to move fast, stay secure, and deliver software with confidence. When this core infrastructure falters, everything around it slows down or stops entirely.
That’s why offering a cloud repository service at scale carries immense responsibility. It’s not enough to handle traffic most of the time. Every single automation request must be served, without fail. The moment automation becomes unreliable, it’s no longer automation and TRUST breaks.
These aren’t just minor technical glitches. When artifact pulls time out or uploads are delayed, CI/CD pipelines stall, deployments get delayed, and teams are left waiting, cost is real. Over time, these interruptions lead to slower release cycles, missed deadlines, and frustrated engineers. Worst of all, they tend to strike during critical moments, major releases, urgent patches, when resilience is non-negotiable.
Despite implementing aggressive request rate limiting, Cloudsmith still struggles to provide a reliable artifact management service.
A repository platform that can’t scale with your workload isn’t just an inconvenience. It’s a liability.
Cloud Native – Being Online is NOT Optional
When it comes to platform reliability, there’s no room for compromise. Your pipelines, developers, and deployments all depend on the service uptime. And the numbers speak for themselves.
We took a random look at Cloudsmith’s own status page, examining their self-testimonials for uptime. As a company boasting a “Cloud-Native” approach for service management, uptime reports paint a rather worrying picture.
Backend processing services as well as databases exhibit 99.41% availability during May, a severe outage for any organization relying on continuous delivery and reliable performance.
To put that into perspective: That’s 4+ hours(!) during the month where build pipelines could fail, artifact downloads and uploads could fail to function, and developers and agents wouldn’t make progress. Effectively, this may disrupt releases, delay deployments, block the delivery of new features and bug fixes to customers and overall waste a huge amount of hours for any organization waiting for the cloud service to recover. In fast-moving development environments, even a monthly-downtime of minutes matters, and is unacceptable, not to mention a downtime of several hours.
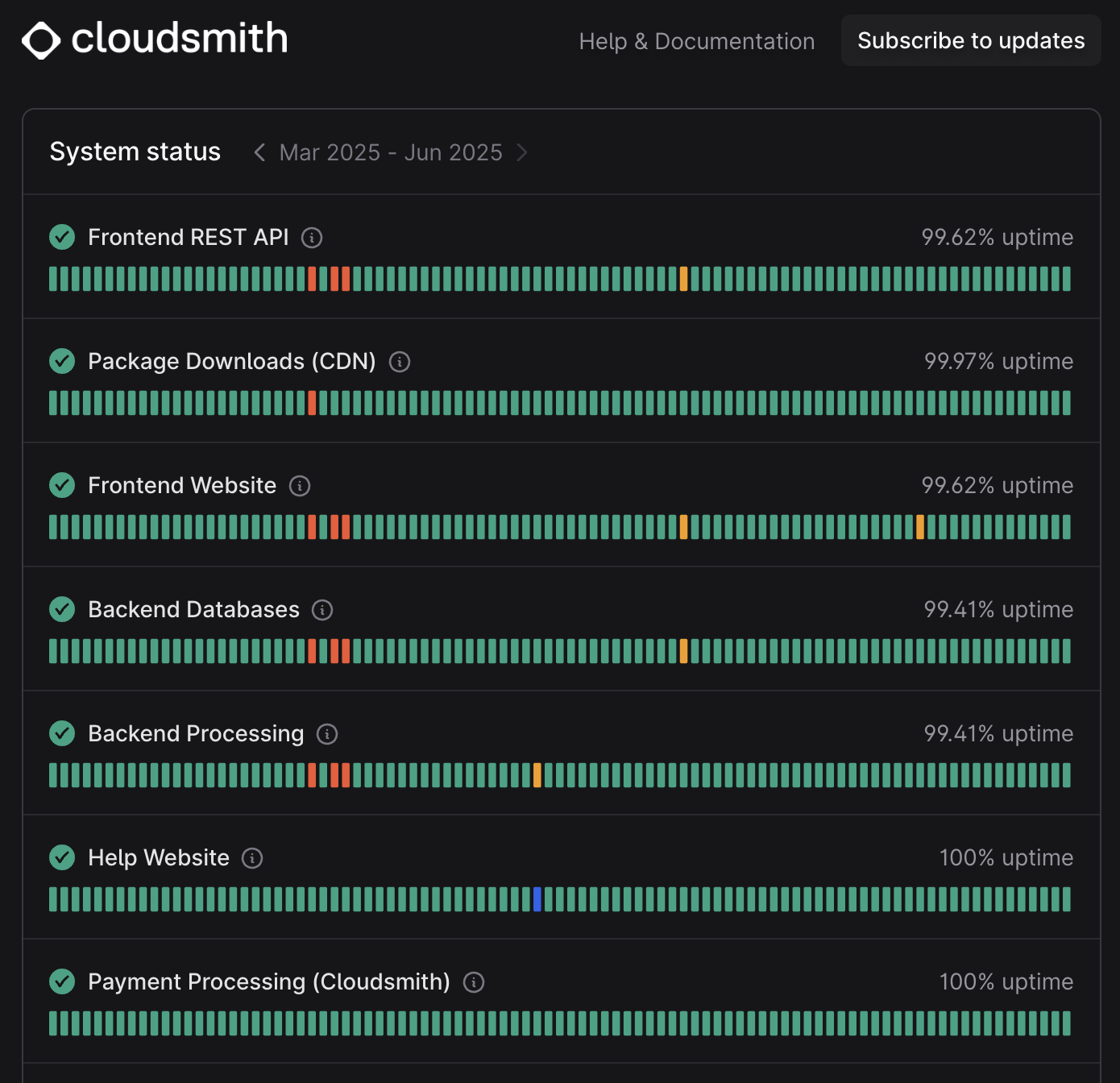
In contrast, across the same period, JFrog Cloud maintained a flawless 100% uptime, with a guaranteed SLA of 99.9% availability. That’s not just a statistic, it’s a meticulously monitored target of being always on, as a Cloud Service that enables your organization’s software factory.
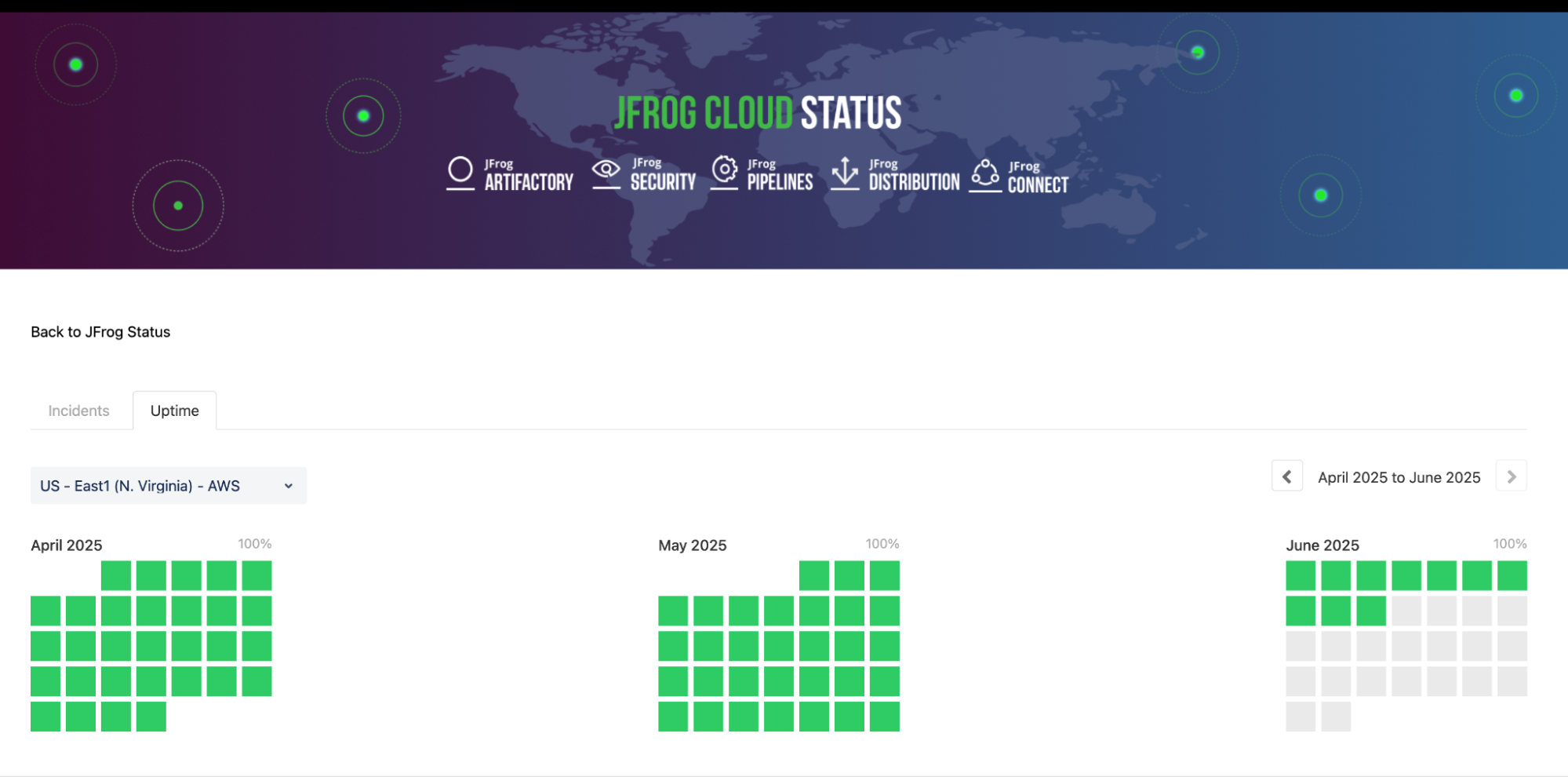
So when you’re choosing the foundation for your software supply chain, don’t settle for “good enough”. Choose the cloud platform that is built with the right operational maturity and commitment for continuous uptime and global resilience under real-world workloads.
Bottom Line
True scalability encompasses not just raw speed but consistent performance under sustained loads, inherent resilience against failures, and delivering maximum uptime. An enterprise-grade cloud-native solution for artifact management and security must meet the continuous demands of hundreds, if not thousands, of developers, ensuring rapid delivery and uninterrupted availability to shared development resources.
Unfortunately, it’s not enough for vendors to call their offerings “cloud-native”, as enterprises need assurance that the underlying architecture and domain expertise can actually deliver on these promises. In Cloudsmith’s case, the default behavior of request rate limiting at what many consider to be even lower than an entry-level scale, coupled with common service disruptions and an uptime commitment that falls short of industry standards, is certainly cause for concern. Taken together, these factors collectively suggest that Cloudsmith may struggle to provide the foundational reliability and performance necessary for large-scale organizations to confidently deploy their solutions for managing development operations.
This adds to software supply chain features offered by Cloudsmith on top of their artifact repository, that are a cobbled together solution based on outdated OSS tools, promoting a false sense of security.
Entrust your organization’s software development operations and security to proven technology that benefits thousands of enterprise cloud customers, built for handling their workflows under peak loads, not for flinching under pressure.
Check out the JFrog Platform by taking an online tour, scheduling a 1:1 demo, or starting a free trial at your convenience.


