JFrog Pipelines 1.6: Overcoming CI/CD Obstacles to Scaling DevOps

By
7 min read

Long release cycles are no longer viable in the world of software development. The promise of DevOps has been to materially shrink time to value. Like most meaningful transitions, this one hasn’t always been a simple flip of a switch. For many organizations, development teams have become complex and unwieldy. So, the custodians of DevOps have found it difficult to achieve broader adoption of DevOps principles across engineering teams.
We heard about some of these challenges from you. We heard about approaches to DevOps that created a complex tangle of technology. This complexity only got in the way of broad adoption. You told us that you need a simple, central, cloud-native, Kubernetes enabled way to solve the problem. You asked for consistency, standardization, and reusability.
We created JFrog Pipelines with the goals you set forth for us. We have now added new features to JFrog Pipelines 1.6 with the same goals in mind. We’re committed to helping you achieve broader adoption of DevOps principles across engineering teams so that you can deliver a continuous stream of value for your customers.
Build Your Own Library of Custom Steps
We’re extending the concept of reusability to make it even easier for you to build your pipelines. Workflows in JFrog Pipelines are built by combining discrete steps, each of which performs a task. We have pre-built several common steps our users need – we call these Native Steps. We currently provide a robust set of over 20 Native Steps that cover your core DevOps tasks.
In addition to commonly occurring steps across all our customers, each of you will have commonly occurring steps that are unique to you. So, we’re now taking Native Steps to the next level by empowering you to build your own library of steps. Now you can encapsulate frequent common actions in your own pipelines. This is much simpler than other approaches involving plugins that conflict with each other, creating a ‘plugin hell’ for users. You can define your custom steps in YAML files in your source control system and import these steps into pipelines.

Being able to assemble pipelines, rather than scripting them, makes pipeline creation scalable – every incremental pipeline becomes easier to write. The effort of a few experts, who can create your custom steps, can go a long way towards empowering others who do not need the same level of DevOps skills.
Our vision for pre-built steps is wide-ranging, with an eye towards enabling our partners and our community to create and share pre-built steps in the future. Your ability to define your own custom step library is a huge step forward. Moreover, we have a huge runway with what we can accomplish with this. Watch this space!
Cloud-Native Efficiencies With Kubernetes Build Nodes
We were early entrants into the Kubernetes game by extending Artifactory to serve as your Docker Container Registry as well as your Helm Chart Repository, making Artifactory your full-featured K8s registry. K8s enables you to quickly and predictably deploy your applications using containerized microservices and is rapidly becoming the de facto standard platform for managing the orchestration of containers.
If you’re consolidating your workloads on K8s, it’s likely that you’ll also want to run your Pipelines build nodes on K8s. Your pipelines can then inherit all the platform automation that comes with K8s. You can now specify node pools that run on K8s pods for your pipelines as an alternative to running your pipelines on VMs. So your pipelines will be able to build anywhere K8s runs – whether on EKS, GKE, Azure’s AKS, or your on-prem clusters. This helps you avoid cloud vendor lock-in, and empowers you to leverage the strengths of each cloud provider as appropriate for your workloads.
Kubernetes node pools are dynamic. Pipelines can spin up or down build nodes on demand. Pipelines delivers the scale efficiencies associated with cloud-native computing, minimizing cloud service charges by demanding resources only as they are needed.
Matrix Builds – Define and Run Your Builds Fast
Test suites are growing in complexity, involving various permutations of environments, languages, tools, and versions of runtimes. It can be tedious to define each permutation, and the performance of your builds can really suffer from having to sequentially test every permutation. You’re likely to grow tired of waiting for your builds to complete. Enter the Matrix Build.
Matrix Builds enable you to execute the same step action in a variety of configurations and runtime environments, with each variant executing as an independent “steplet.” Currently, all steplets run on a single node, but future releases will support parallel execution of steplets across multiple nodes or node pools. Spreading your build workload can dramatically amp up performance. For instance, you can have various build steplets running in parallel, each one running against a specific version of Node.js, and a specific runtime version of Linux, with its own set of environment variables. On completion of all steplets, Pipelines aggregates the status and results, giving the appearance of a single step.
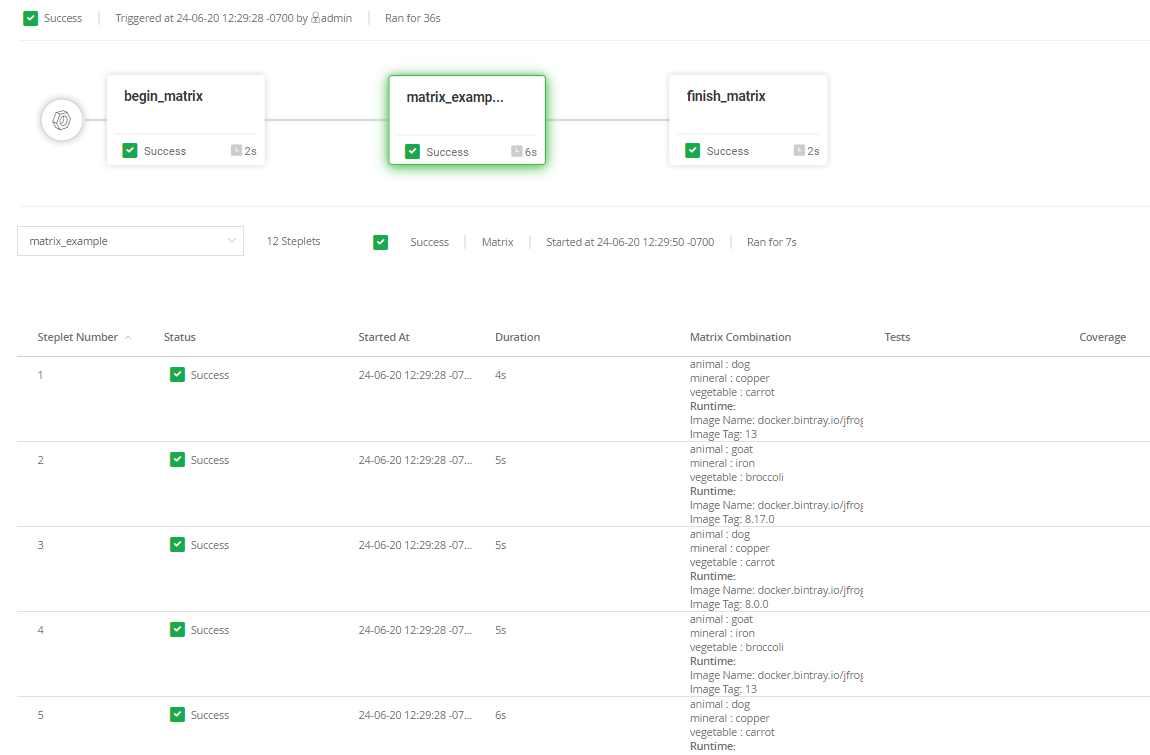
So how does this magic work? Within the YAML configuration for the step, you can specify the set of environment variables, build images, and language versions you want to test against. Pipelines will then build out the full matrix of tests to be run, and run each combination in parallel. That’s it!
More Improvements
Along with these functional, performance and infrastructure improvements, we’re also enhancing Pipelines for ease of use.
Easy Integration with Jenkins – New Native Step
We have improved our integration with Jenkins by adding a new native step. This is significant because of the sheer number of development teams that use Jenkins for building and integrating software. With our Jenkins integration, JFrog Pipelines can subsume Jenkins pipelines, empowering you to create pipelines of pipelines. Hence, the adoption of JFrog Pipelines is non-disruptive, enabling you to continue leveraging your investment in Jenkins.
The Jenkins native step empowers you to represent a Jenkins job as a step in your JFrog pipelines. A member of your team creates the integration with Jenkins only once. Developers can then add a Jenkins build step to their JFrog pipelines without being concerned with the particulars of the integration. The Jenkins native step transfers execution to a Jenkins pipeline. Once the Jenkins pipeline completes, it returns control to the JFrog pipeline.
Quickly Find Your Pipelines
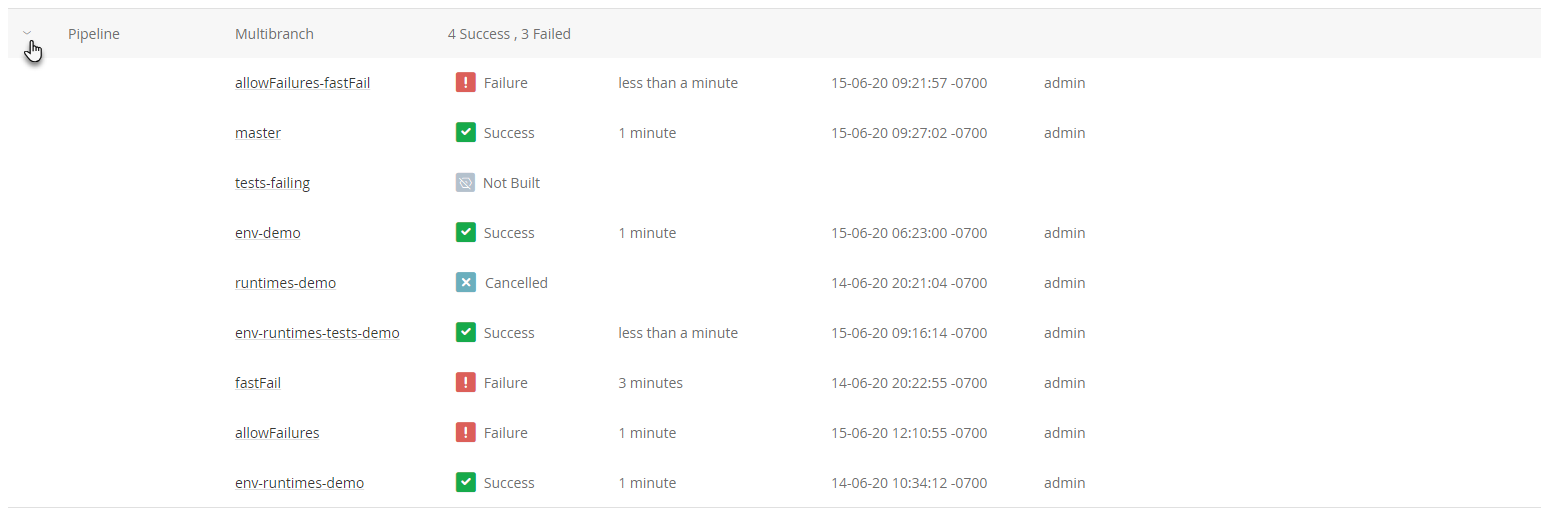
We’ve introduced several UI navigation improvements, including the ability to quickly find your pipelines by tagging your favorites.
We’ve also made it much easier to monitor your multibranch pipelines, with an expanding/collapsing UI to group them and view the status of each.
CI/CD for Fast Forward
These changes mark a huge step forward, establishing a great cadence for enhancements to Pipelines. We’ll keep pushing on these fronts to make pipelines increasingly frictionless and keep you posted on our progress as it occurs.
Now is the time to try out JFrog Pipelines. You can easily sign up for a trial and build your first pipeline by recreating the examples in our set of Pipelines Quickstarts.


