

Don’t Let the Maven Deploy Plugin Trip You Up

Apache Maven is a commonly used build tool. It has many cool features such as default processing steps that are included out of the box, and is particularly good for compiling and packaging Java code. But this blog post is not an introduction to Maven. There are plenty of great books that provide that, and you could probably also find skilled colleagues to learn from. I’m also not going to discuss the pros and cons of Maven. There are plenty of successful projects enjoying it’s pros, and other projects that prefer alternative tools because of its cons. What I do want to explore is Maven’s deploy plugin (primarily used during the Maven deploy phase), its shortcomings and how to address them. This is something I’m often asked about, so here are the answers summarized up front.
The Maven deploy plugin and its shortcomings
Working with Maven commonly includes using the deploy plugin to upload build artifacts to a remote repository for sharing with other teams. It’s really handy that you can just add a <distributionManagement/> section to your Maven POM to reference a remote repository such as JFrog Artifactory, and you are pretty much done. Sometimes this is, indeed, a sufficient solution, but nowadays, there are often requirements and basic conditions which motivate us to seek more advanced solutions, for the following reasons:
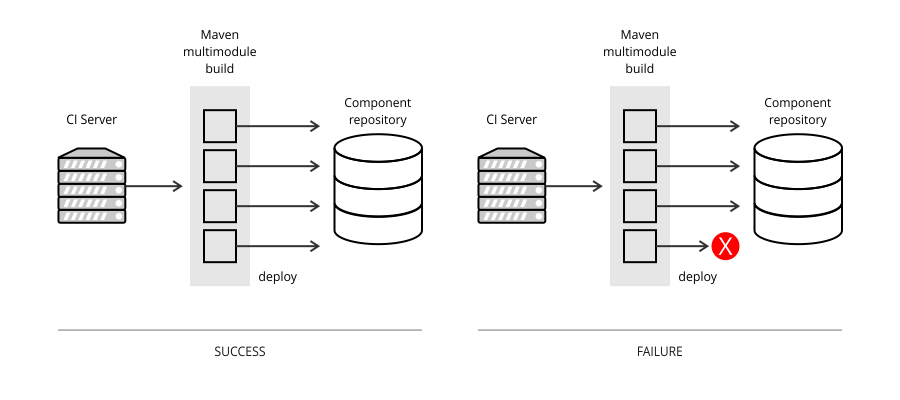
Project aggregation may lead to inconsistent deployment
Maven supports the concept of project aggregation in which a batch of modules is processed together. This is especially used when deploying the modules to a component repository. The problem is that all Maven modules are processed and deployed sequentially, one by one. If deploying any of the modules fails, the remote repository is updated with new versions of modules, but left with older versions of those whose deployment failed, rendering it in an inconsistent state. “Quality is the absence of error” (Gerald M. Weinberg, Quality Software Management Vol. 1 Systems Thinking (Dorset House, 1992), pg. 9).
Context matters
These days, when context matters more and more, it is often not enough to just distribute a binary. The real value of a binary is evoked from its context and meta information. For example, in big and complex project setups, quality gates are injected, and binaries are labeled/certified according to the current state of processing, or are just enriched with build information (including dependencies) by the build engine. Use cases include wanting to find and stage artifacts which are annotated with specific attributes, or examining the impact path of build dependencies. More advanced tools in build management offer bill-of-materials reports, and dependency and traceability checking that help with integrity and auditing (Mario E. Moreira, Adapting Configuration Management for Agile Teams (Wiley, 2010), pg. 231).
You need deployment flexibility
When running a series of builds, you often need to configure which artifacts should be deployed to the target repository. For example, you might skip some of the artifacts you are building, and add different ones from other sources. By default, Maven takes a more rigid approach and expects to deploy one module for each artifact built. While there are ways to get around this, ad-hoc solutions can quickly become unmaintainable, and a more standard and flexible solution providing fine-grained deployment flexibility would be preferred.
You should keep your POM file tidy
Adding <distributionManagement/> to the Maven POM, even if it is just a parent POM, contaminates the POM file. The POM should only contain information about how to compile and package the code and it is usually a wise idea to keep it tidy.
Don’t expose the Maven remote repository to developers
In Agile setups, a developer should not be allowed to directly deploy to the Maven remote repository. So why bother to open the door and add information about the deploy targets of the remote repository. It is the build server, such as Jenkins, that deploys the artifacts, and in the case of Jenkins, it can be configured to do so centrally.
Cycle Time is too long
The Cycle Time is a common indicator of how optimal your time-to-market is (Michael Hüttermann, DevOps for Developers (Apress, 2012), 38ff) . To keep it low and optimized, processes and tools must do their job quickly and at a high level of quality. Maven deploy tasks often take longer than necessary since they include unwanted processing steps such as compiling and packaging code for artifacts that have already been packaged, or they just deploy artifacts inefficiently.
Binaries and their build pipelines should be decoupled
As DevOps continues to evolve, delivery pipelines are becoming more and more heterogeneous. Gone are the days when a pipeline was based on a single technology such as Java. Being bound by constraints of a particular technology may be unnecessary and even counter-productive. It’s better to decouple your binary management from your local build infrastructure so that binaries can be easily deployed, and downstream functions such as operations can just pick them up and use them with complete independence from the build tools and technologies. Although Maven is a commonly spread standard, why stick to its proprietary deployment processes? “The secret of success is not to foresee the future, but to build an organization that is able to prosper in any of the unforeseeable futures” (Mary and Tom Poppendieck, Leading Lean Software Development-Results are not the Point (Addison-Wesley, 2010), 236ff).
Make packaging and deployment fun again
“Coordinating the packaging and deployment of complex systems is one of those boring tasks that are almost a lot harder than they look” (Eric Evans, Domain-Driven Design (Addison-Wesley, 2014), pg. 387). This need not be the case. Packaging and deployment is an essential part of the overall process, and is too important to just stick to some putative standards which may not fit to your individual requirements and basic conditions.
How to do better
JFrog Artifactory, the Universal Artifact Repository Manager, together with its ecosystem, supports solutions to address all the shortcomings listed above out-of-the-box. It offers you different ways to implement solutions that are aligned with your requirements. In the paragraphs below I will provide examples showing different ways to deploy your artifacts with atomic transactions, how to label/certify them with fine-grained processing that is build-tool-agnostic, all while underpinning design principles such as Separation of Concerns by keeping the POM file clean (see also Frank Buschmann, et al., Pattern-Oriented Software Architecture (Wiley, 1996), pg. 241). Let’s start with the most obvious approach, the integration with the build engine.
Using build engine integration
Integrating Jenkins with Artifactory, via the Jenkins Artifactory plugin, has many appealing benefits (see also Michael Hüttermann, Agile ALM (Manning, 2011), pg. 229), including addressing the drawbacks of the standard Maven approach mentioned above. After installing the Jenkins Artifactory plugin, just create a new build job (e.g. a Jenkins Freestyle build) and in its configuration page, enable the Maven3-Artifactory Integration. The Invoke Artifactory Maven 3 build step just needs to call Maven’s install phase, and the rest is done by the Jenkins Artifactory plugin.
You can also use Jenkins 2 native delivery pipeline features. The following stage adds a property (i.e. a key/value pair) to the artifact, and deploys the binary, along with an example property, to Artifactory.
stage ('Maven build') { rtMaven.deployer.addProperty("status", "in-qa") buildInfo = rtMaven.run pom: 'all/pom.xml', goals: 'clean install' server.publishBuildInfo buildInfo }
The next example shows how to:
- Define the set of binaries to be deployed to Artifactory, by using upload specs, in JSON format
- Upload the artifact, annotated with example meta information
- and also publish the context information, i.e. the exhaustive build info that the plugin generates
""" { "files": [ { "pattern": "all/target/all-(*).war", "target": "libs-snapshot-local/com/huettermann/web/{1}/", "props": "where=swampUP;owner=huettermann" } ] } """ buildInfo = Artifactory.newBuildInfo() buildInfo.env.capture = true buildInfo=server.upload(uploadSpec) server.publishBuildInfo(buildInfo) }
This can be integrated into holistic delivery pipelines and allows the implementation of quality gates (and can also be applied to other artifact types such as Docker images or Chef Cookbooks). 
But there’s an even more flexible way to transfer your binaries to JFrog Artifactory; by using the REST API.
Using the REST API
Artifactory exposes a rich REST API that lets you automate many different actions on artifacts including uploading binaries. Uploading a binary using cURL looks something like this:
curl -u admin:$artifactory_key -X PUT "https://localhost:8071/artifactory/simple/libs-qa/com/huettermann/all/1.0.0/all-1.0.0.war;status=in-qa" -T all-1.0.0.war
We pass along the credentials, and define the target repository and the local file to be uploaded. There are several different ways to configure the call. For example you could authenticate your user using access keys or access tokens. Now, we could search for all artifacts labeled with the property “status” and value “in-qa”. In the UI, it would look like this:

As part of our scripted solution, we could now use Artifactory Query Language (AQL) to find artifacts with given properties.
venus:scrapbook michaelh$ curl -H "X-JFrog-Art-Api:$artifactory_key" -X POST https://localhost:8071/artifactory/api/search/aql -T search.aql { "results" : [ { "repo" : "libs-release-local", "path" : "com/huettermann/all/1.0.0", "name" : "all-1.0.0.war" },{ "repo" : "libs-qa", "path" : "com/huettermann/all/1.0.0", "name" : "all-1.0.0.war" } ], "range" : { "start_pos" : 0, "end_pos" : 2, "total" : 2 } }
where the search.aql script looks like this:
items.find( { "name": { "$match":"all*.war" }, "@status":{"$eq":"in-qa"}, "created_by": "deploy" }).include("name","repo","path").sort({"$asc":["name"]})
Finally, the last option I want to cover, is JFrog CLI.
Using JFrog CLI
The JFrog Command Line Interface is a small helper executable that wraps the REST API. It can be easily downloaded and is very intuitive to use. Once again, let’s consider the simple example of uploading a binary called “hello.txt” to a generic repository (i.e., a repository of type “Generic”) called “generic-local” in Artifactory. Here’s how simple it is:
jfrog rt u --url=https://localhost:8071/artifactory --apikey=$artifactory_key hello.war generic-local
Another common use case is to promote artifacts to another repository in Artifactory after they have passed certain quality gates This next example shows how to trigger promotion based on build information of a former build. Note that this example copies (not moves) the artifact to a staging repository without copying its dependencies:
jfrog rt bpr --include-dependencies=false --apikey=$artifactory_key --url=https://localhost:8071/artifactory --copy=true $JOB_NAME $BUILD_NUMBER libs-qa
Here too there is much more you can do with the artifacts you specify such as including Java deployment units, adding meta information to and much more. Read about all the possibilities in the JFrog CLI User Guide.
So you needn’t let the drawbacks of Maven deploy get you down. This post has shown different ways to use JFrog Artifactory and its ecosystem to overcome them. The examples I have brought are very specific, but demonstrate a point. It’s up to you to explore Artifactory, its REST API and JFrog CLI to see how to solve your own issues with Maven deploy.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



