

Simplifying App Deployments for Developers – A Short History from Timesharing to Serverless

By
11 min read

I have been in the IT industry for a few decades now and have helped launch waves of technology in the constant pursuit of making computing easier, cheaper and with greater uptime. This all started well before my entry into the IT industry and will continue to well past the time I retire. However, it is always good to understand where we have been and look how far we have come to understand how we can continue to make it even better. After all, computing is simply the automation of manual tasks as a way to help organizations better serve their customers or citizens.

Why Automation is Important
It is not a surprise that the initial applications of computing were for governmental needs. Very quickly the demand for such automation extended to businesses, but to do so the computing had to become even more affordable, more available and more flexible.
In the early days of computing each customer had to own and manage their own computer systems. There were no service providers. Then came timesharing of Mainframes and this provided an entry point for service providers to launch their businesses. Later on additional partitioning/virtualization technologies arose such as virtual machines with hypervisors, containers and then serverless. The point of the article is to recap the progression of these “virtualization” technologies to make computing more nimble, more available, more flexible and less costly and why this matters for both developers and operators. The goal is to further release us from the mundane tasks and free us up to do real value-add work of creating and deploying new applications which deliver services for the business to better serve end customers.
The First Leap Forward
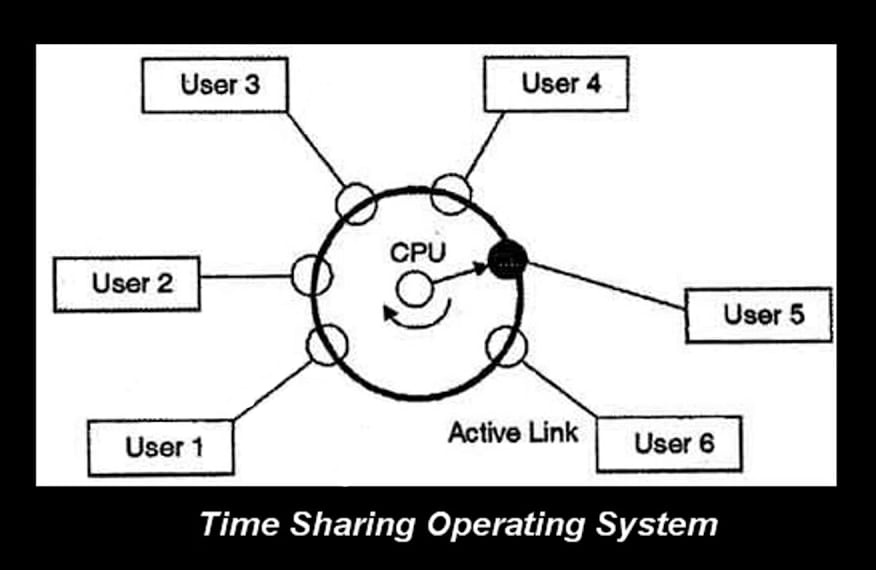
The major advancement in the data center in the 1970s was the jump from a single user or single application per machine to a shared service model known as timesharing. Unlike a dedicated PC per user today where the cost is relatively affordable, the Mainframe computers of the 1950s-1970s were horrendously expensive machines costing millions of dollars in hardware alone. It was made worse by the large amount of idle compute time it took to enter a single program via punch cards or paper tape for use by a single user. The return on investment was poor with these large single user/single application machines. Thus leading to timesharing where multiple users can simultaneously use a single computer through the fractional allocation of computing resources and only be billed for that usage.
Source: Computer Notes
Timesharing was the forerunner to virtual machines, containers and serverless computing as we know them today. However, timesharing was a coarser implementation where ALL available resources were quickly switched between users for different tasks. Users experienced a sufficiently quick response time that led them to believe they were the sole user. Timesharing, though, impacted all users whenever there was an outage. Timesharing gave developers access to scarce Mainframe resources, but was always pushing the boundaries of acceptable latency.
Virtual Machines
Virtual machines, containers and serverless computing address this fragility by minimizing the impact of system failures and breaches on different users. Virtual machines, invented by IBM for Mainframes and later popularized by VMware on x86 industry standard computing, provided separate computing instances, each with its own operating system and application stack, as a way to dedicate resources to particular workloads or users. This helped developers avoid having the applications they developed be trapped by the latency of Timesharing.

Source: USF Explorer
Containers
Containers dedicate critical resources more efficiently by providing separate instances for applications, but allowing the instances to all share a single copy of an operating system which minimizes the system overhead burden. Containers also perform faster than virtual machines and can be spun up and down much more quickly since they don’t require a hypervisor. Given containers’ small size, hundreds or thousands of them can be run on a single server versus a few dozen virtual machines running on a single server. The leading container offerings are Docker and the Open Container Initiative (OCI) for single nodes and Kubernetes for clustered container management.
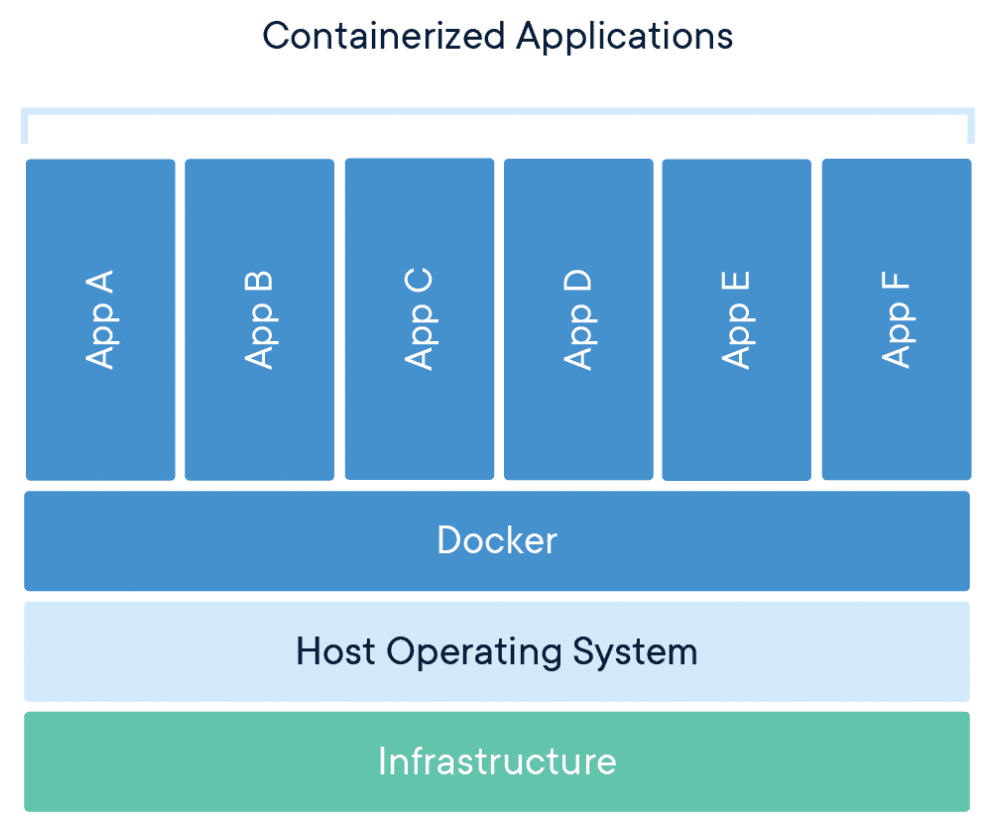
Source: Docker
Containers provide you the freedom to deploy version specific software packages, including the OS, programming languages and runtime environments. Of course that freedom comes with a cost — containers require effort to set-up and maintain them over time. Furthermore, as you divide monolithic applications into smaller microservices, these will each need their own containers, which will then need some type of orchestration to work together. And all of these containers will need their own OS updates, security patches, etc.
| “While you can configure the container orchestration platform to automatically handle traffic fluctuations for you (a.k.a, self-healing and auto-scaling), the process of detecting those traffic pattern changes and spinning the containers up or down won’t be instantaneous. A complete shutdown where no container-related infrastructure is running at all (e.g. when there’s no traffic) will also not be possible. There will always be runtime costs.” — Phillip Muns, Serverless Inc. |
Serverless
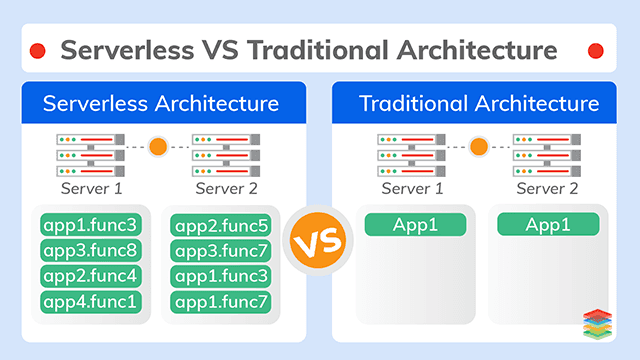
The next evolution in virtualization is serverless (sometimes referred to as Functions as a Service or FaaS). Serverless functions are smaller than container microservices and have no system dependencies to configure, thus they can be faster to deploy. Whereas containers are configured to run on any current Linux or certain versions of Microsoft Windows Server operating systems on any x86 industry standard machine, serverless is typically deployed on a public cloud service and closely tied to that public cloud’s architecture. Thus, though they may be more nimble, different serverless implementations can be thought of as proprietary and are not portable across different cloud vendor platforms.
Currently, there are some limitations with vendor support and ecosystem lock-in. Programming languages and runtimes are limited to whichever the provider supports (though there are some workarounds (or “shims”) available to overcome those restrictions). Event sources (which trigger all your functions) are usually services that the specific cloud provider offers.
Source: XenonStack
Despite the name, serverless functions still run on servers from the public cloud provider. However, the offering is focused on providing back-end services to spin up and run applications on an as-used basis, but offload from the developer the burden of configuring to any particular hardware — therefore the name serverless. An example of serverless offerings would be Google Cloud Functions. The beauty of serverless is that the software developer focuses on the business logic and does not worry about the infrastructure as the public cloud vendor provides that.
| “In that vein, serverless is great if you need traffic pattern changes to be automatically detected and handled instantly. The application is even completely shut down if there’s no traffic at all. With serverless applications, you pay only for the resources you use; no usage, no costs.” –Javier Ramos, ITNext |
Serverless is not a replacement for containers. Rather, both are tools with different purposes and in some cases can be combined. More on that in a moment.
Serverless focuses on stateless, short term instances of applications built in real-time as suites of small services (or functions) which are frequently provisioned and then decommissioned when no longer in use. These serverless applications are built around business capabilities and the activation of their functions can be triggered by events and independently deployable by fully automated deployment machinery. Typical use cases include:
- Stateless HTTP applications
- Web and mobile backends
- Real-time or event-driven data processing
The consumer of serverless functions gets billed based on usage of compute time by these functions rather than a fixed amount of resources which are rented (such as number of processor cores or network bandwidth assigned). Since serverless is intended to be auto-scaling up and down, then a usage- or consumption-based model makes good sense. No money is wasted on unused, rented fixed compute capacity. There are no policy prerequisites to comply with in order to auto-scale resources. Thus capacity can be expanded as needed on a piecemeal basis thus speeding time to market to deploy new business capabilities. The downside is that when a serverless function has not been called in awhile then the cloud provider will decommission the resources assigned in order to avoid over-provisioning and free up the resources for other serverless applications to use. Then, when you want to re-create that same serverless set of functions you will need to start again from scratch which is often referred to as “cold start.”
As previously mentioned, serverless and containers are not technology successors or replacements for each other, but rather are targeted for different usages. In some cases you can actually use them in combination to help get the benefits of both.
Here is a video of a session presentation by Phil Beevers of Google at JFrog’s SwampUp 2021 conference which provides a great overview of serverless, “The future of serverless, developing apps for the fast-paced world.”
Blended Serverless Containers with Google Cloud Run
One example where aspects of containers and serverless have been combined is Google Cloud Run. Rather than triggering a collection of functions based on some event as in traditional serverless, with Google Cloud Run you invoke execution of a container via HTTP requests with much the same nimbleness as serverless. By deploying an application in a container you can have the option to maintain persistence and not automatically decommission the instance when not actively in use. Furthermore, with Google Cloud Run you can have more control over the OS and runtime versions and the types and capacities of the hardware assigned in contrast to traditional serverless deployments.
For more information on how Google Cloud Run works and could benefit you, please see the SwampUp 2021 session video by Guillaume Laforge and Ayrat Khayretdinov of Google, “Going Serverless, with Artifactory and Containers on Cloud Run.”
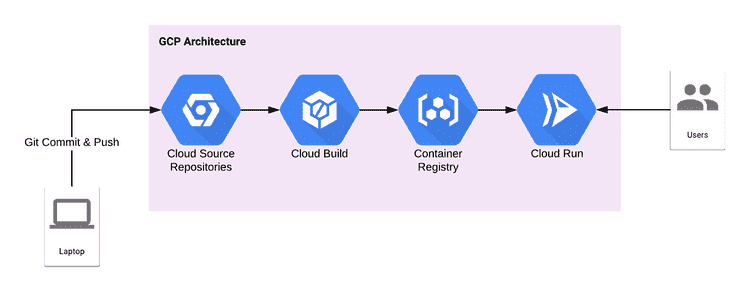
Source: Rob Morgan
For developers, choose containers and container orchestration when you need persistence of the application, flexibility of what hardware to assign or when you need to migrate legacy services. Choose serverless when you need speed of development, automatic scaling and significantly lowered runtime costs. A container-based hybrid serverless offering like Google Cloud Run will enable you to maintain the instance even when not active, while also automatically scaling with consumption-based billing.
With each stage of virtualizing computing from timesharing to virtual machines to containers to serverless we have addressed different choke points of cost or application ease of deployment or both.
- With timesharing the focus was reducing the cost of hardware assigned to a user or application to allow more developers access to computing
- With virtual machines the goal was to abstract the software from the underlying hardware and increase utilization of the infrastructure and allow resizing and migration of instances
- With containers we gained portability of applications across hardware even from legacy platforms to modern platforms and the ability to spin-up hundreds or even thousands of instances
- With serverless we have achieved the ability for events to trigger automatic assembly of functions into applications on the fly and in a very granular way only pay for what you use
- With hybrid serverless containers you get nimbleness of serverless, but with the persistence of containers
For more information on the innovation of serverless and the benefits it could bring to you as a developer or manager of developers, please download the eBook titled “Serverless Guide to Success.”
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



