

How to Deploy Machine Learning Models into Production

By
12 min read
Machine learning (ML) models are almost always developed in an offline setting, but they must be deployed into a production environment in order to learn from live data and deliver value.
A common complaint among ML teams, however, is that deploying ML models in production is a complicated process. It is such a widespread issue that some experts estimate that as many as 90 percent of ML models never make it into production in the first place.
For the relatively few ML models that do make it to the production stage, ML model deployment can take a long time, and the models require constant attention to ensure quality and efficiency. For this reason, ML model deployment must be properly planned and managed to avoid inefficiencies and time-consuming challenges.
In this blog post, we are going to explore the basics of deploying a containerized ML model, the challenges that you might face, and the steps that can be taken to make the process more efficient.
What is ML Model Deployment?
The goal of building a machine learning application is to solve a problem, and a ML model can only do this when it is actively being used in production. As such, ML model deployment is just as important as ML model development.
Deployment is the process by which a ML model is moved from an offline environment and integrated into an existing production environment, such as a live application. It is a critical step that must be completed in order for a model to serve its intended purpose and solve the challenges it is designed for. Deployments create an online learning machine methodology where a model is trained and continuously updated with new data as it becomes available.
The exact ML model deployment process will differ depending on the system environment, the type of model, and the DevOps processes in place within individual organizations. That said, the general deployment process deployed into a containerized environment can be summarized into four key steps, which we will cover later.
Model Deployment Process – The Planning
Before we dive into the steps involved in deploying ML models, it’s important to consider why so many ML teams cite deployment as a pain point.
The truth is that many ML teams embark on machine learning projects without a production plan in place. This approach is risky and invariably leads to problems when it comes to deployment. It’s important to remember that developing ML models is expensive, both in terms of time and money, so embarking on a project without a plan is never a good idea.
While it would be impossible for us to tell you how to plan your own ML project — there are simply too many variables at play — we can highlight three important things that you should consider during the planning stage. These are:
Where You’ll Store Your Data
We don’t need to tell you that your ML model will be of little use to anyone if it doesn’t have any datasets to learn from. As such, you will likely have a variety of datasets covering training, evaluation, and testing. Having these is not enough, though; you must also consider storage.
Consider questions like:
- How is your data stored?
- How large is your data?
- How will you retrieve your data?
Storage: It makes sense to store your data where model training will take place and where results will be served. Data can be stored either on-premises, in the cloud, or in a hybrid environment, with cloud storage generally used for cloud ML training and serving.
Size: The size of your data is also important. Larger datasets require more computing power for processing and model optimization. If you are working in a cloud environment, then this means that you will need to factor in cloud scaling from the start, and this can get very expensive if you haven’t thoroughly pre-planned and thought through your needs.
Retrieval: How you will retrieve your data (i.e., batch vs real-time) must be considered before designing your ML model.
Which Frameworks and Tools You’ll Use
Even with the best datasets in the world, your ML model isn’t going to train and deploy itself. For this, you will need the right frameworks, tools, and software, which can be anything from programming languages like Python to frameworks and cloud platforms like Pytorch, AWS, and JFrog ML.
Consider questions like:
- What is the best tool for the challenge we’re facing?
- Do we need the flexibility of open source?
- How many platforms support the tool?
How You’ll Collect Feedback
Machine learning projects are dynamic and constantly evolving. Feedback and iteration form important parts of development and deployment processes, and you must consider these from the outset.
Consider questions like:
- How can we retrieve feedback from production models?
- How can we ensure constant delivery?
- How can we test new iterations of the model?
- How can we iterate our model without interrupting its operation?
Getting continuous feedback from a ML model in production can alert you to issues like performance decay, bias creep, and training-serving skew. This ensures that such issues can be rectified before they have an impact on the model and the end-user.
How to Deploy ML Models
Deployed ML models provide incremental learning for online learning machines that adapts models to changing environments to make predictions in near real-time. As we alluded to above, the general ML model deployment process can be summarized in four key steps:
1. Develop and Create a Model in a Training Environment
To deploy a machine learning application, you first need to build your model.
ML teams tend to create several ML models for a single project, with only a few of these making it through to the deployment phase. These models will usually be built in an offline training environment, either through a supervised or unsupervised process, where they are fed with training data as part of the development process.
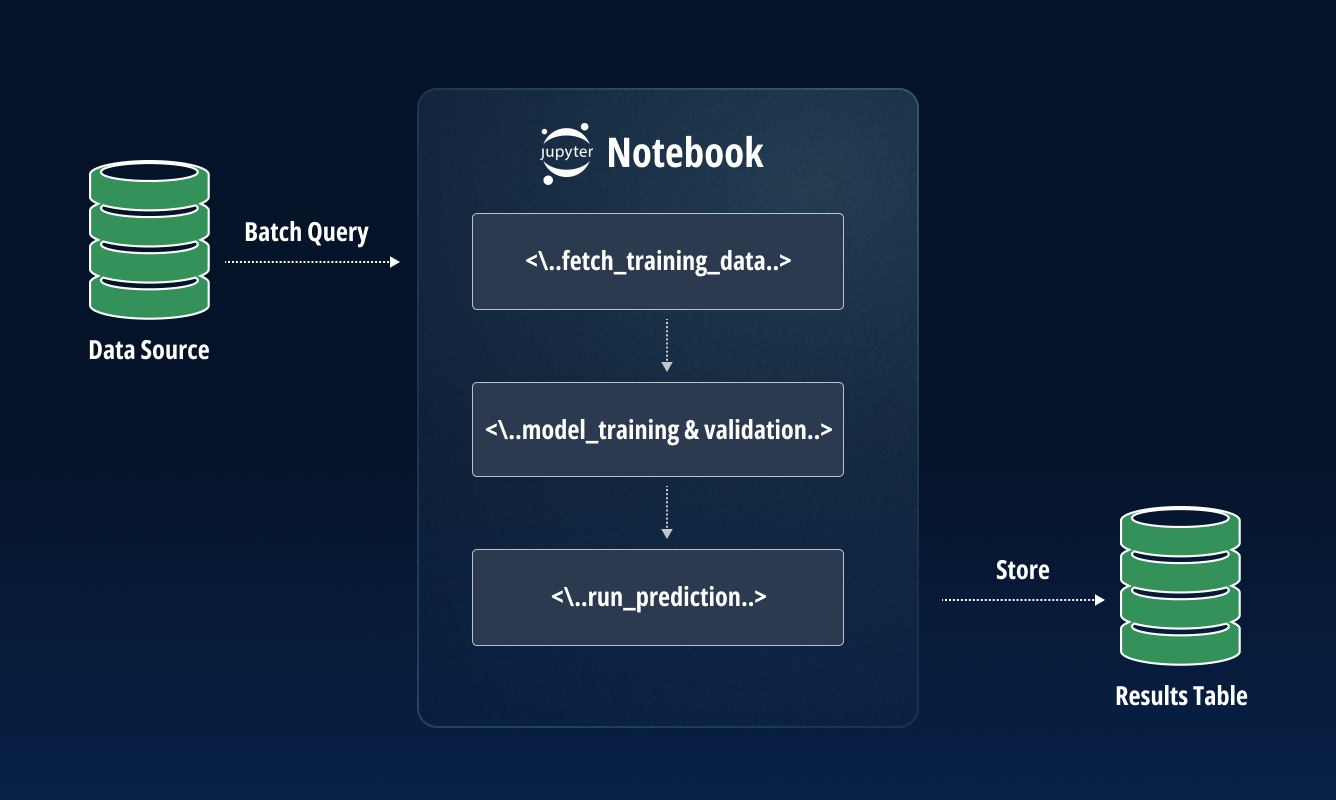
2. Optimize and Test Code, then Clean and Test Again
When a model has been built, the next step is to check that the code is of a good enough quality to be deployed. If it isn’t, then it is important to clean and optimize it before re-testing. And this should be repeated where necessary.
Doing so not only ensures that the ML model will function in a live environment but also gives others in the organization the opportunity to understand how the model was built. This is important because ML teams do not work in isolation; others will need to look at, scrutinize, and streamline the code as part of the development process. Therefore, accurately explaining the model’s production process and any results is a key part of the process.
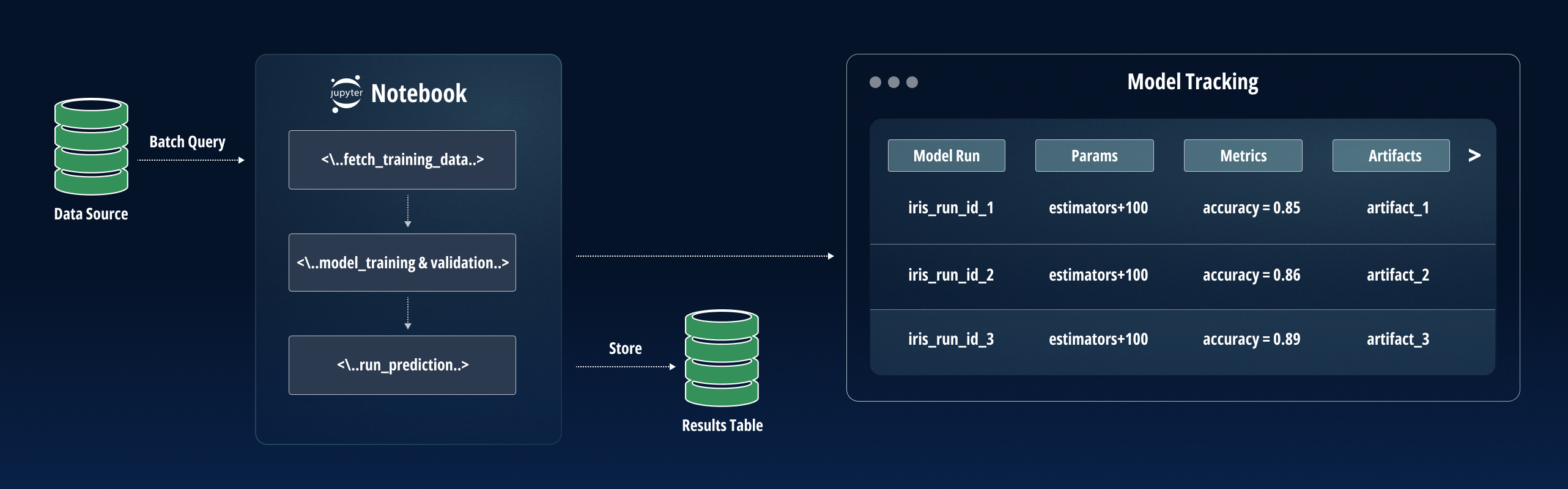 Click to enlarge
Click to enlarge
3. Prepare for Container Deployment
Containerization is an important tool for ML deployment, and ML teams should put their models into a container before deployment. This is because containers are predictable, repetitive, immutable, and easy to coordinate; they are the perfect environment for deployment.
Over the years, containers have become highly popular for ML model deployment because they simplify deployment and scaling. ML models that are containerized are also easy to modify and update, which mitigates the risk of downtime and makes model maintenance less challenging.
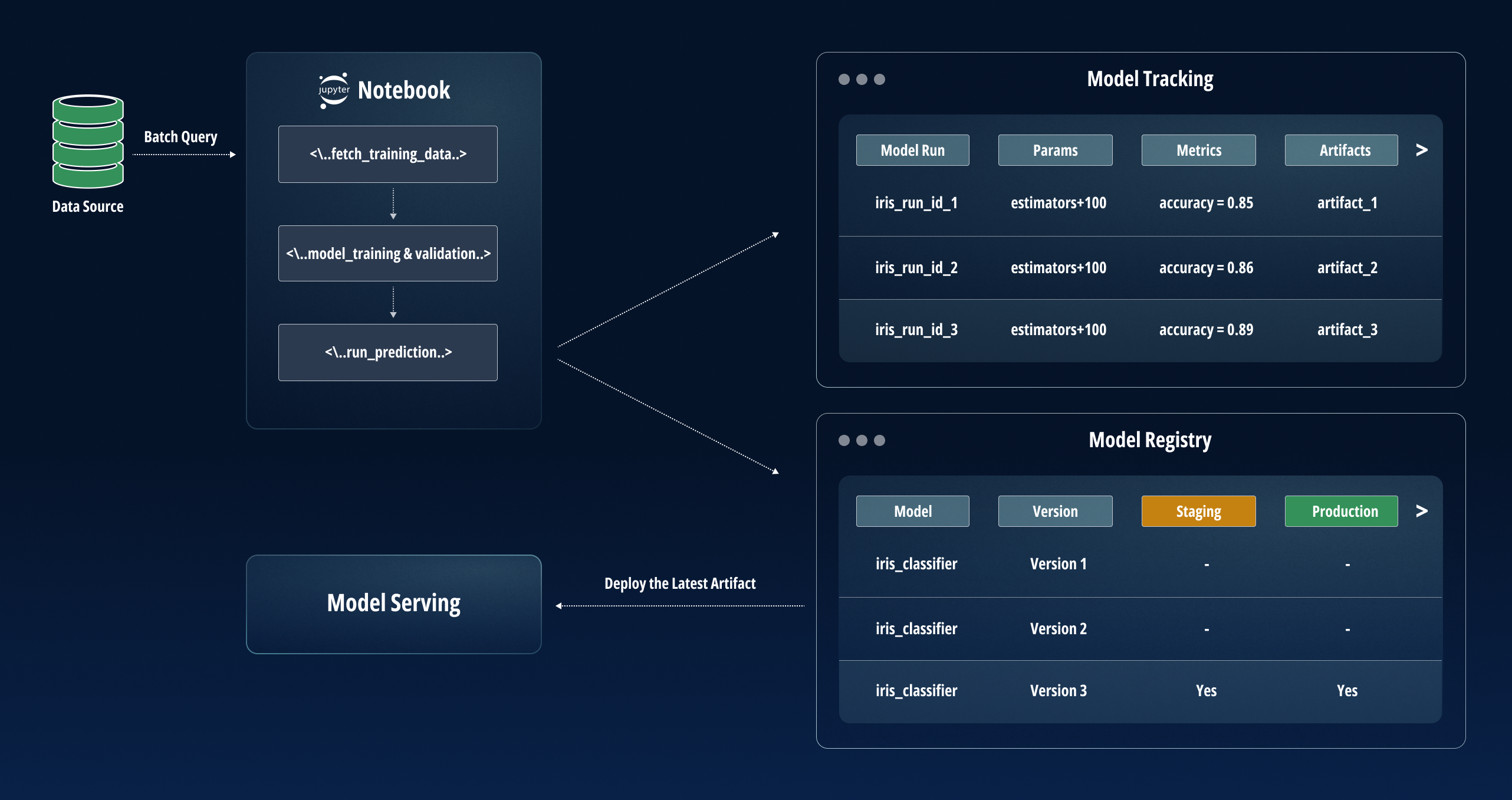 Click to enlarge
Click to enlarge
4. Plan for Continuous Monitoring and Maintenance
The key to successful ML model deployment is ongoing monitoring, maintenance, and governance. Merely ensuring that the model is initially working in a live setting is not enough; continuous monitoring helps to ensure that the model will be effective for the long term.
Beyond ML model development, it is important for ML teams to establish processes for effective monitoring and optimization so that models can be kept in the best condition. Once continuous monitoring processes have been planned and implemented, issues like data drift, inefficiencies, and bias can be detected and rectified. Depending on the ML model, it may also be possible to regularly retrain it with new data to avoid the model drifting too far away from the live data.
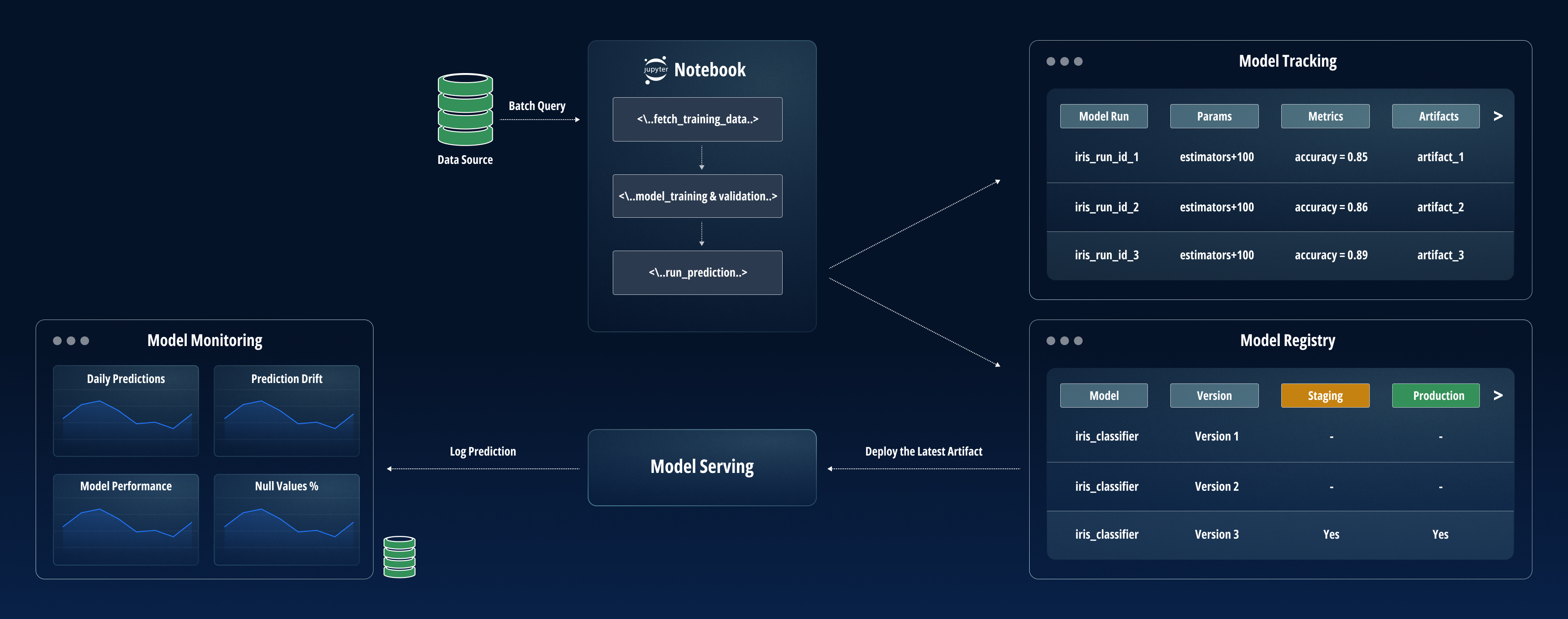 Click to enlarge
Click to enlarge
Potential ML Model Deployment Challenges
ML model development is invariably resource-intensive and complex. Taking a model that has been developed in an offline environment and integrating it into a live environment will always bring with it new risks and challenges, including:
- Knowledge: A ML model is typically not built and deployed by the same team; data scientist teams build it while developer teams deploy it. A major challenge is bridging the gap between the two, because skills and experience may not overlap between the two distinct areas.
- Infrastructure: ML deployment can be made more challenging if there is a lack of robust infrastructure. This slows down the process because infrastructure must then be built, and this runs the added risk of a model having to be unnecessarily retrained with fresh data.
- Scale: It is important to recognize that your model will likely need to grow over time and scaling the model to meet the need for increased capacity adds another level of complexity to the ML deployment process.
- Monitoring: Ongoing effectiveness of the model also presents a potential challenge. As we mentioned, models should be continuously monitored and tested after deployment to ensure accurate results and drive performance improvements.
Making ML Model Deployment More Efficient
What if we told you that deploying your ML models could be as easy as following three simple steps? It’s true! Here are our tips for deploying your own model and avoiding many of the challenges at the same time:
1. Decide on a Deployment Method
The first step is to figure out which deployment method you want to use. There are two main ones: batch inference and online inference.
Batch inference: This method runs periodically and provides results for the batch of new data generated since the previous run. It generates answers with latency and is therefore useful where model results are not needed immediately or in real-time. The main benefit of batch inference is the ability to deploy more complex models.
Online inference: Also known as real-time inference, this method provides results in real-time. While this sounds like the better method, it has an inherent latency constraint that limits the type of ML models that can be deployed using it. Since results are provided in real-time, it is not possible to deploy complex models with online inference.
Diagram 5

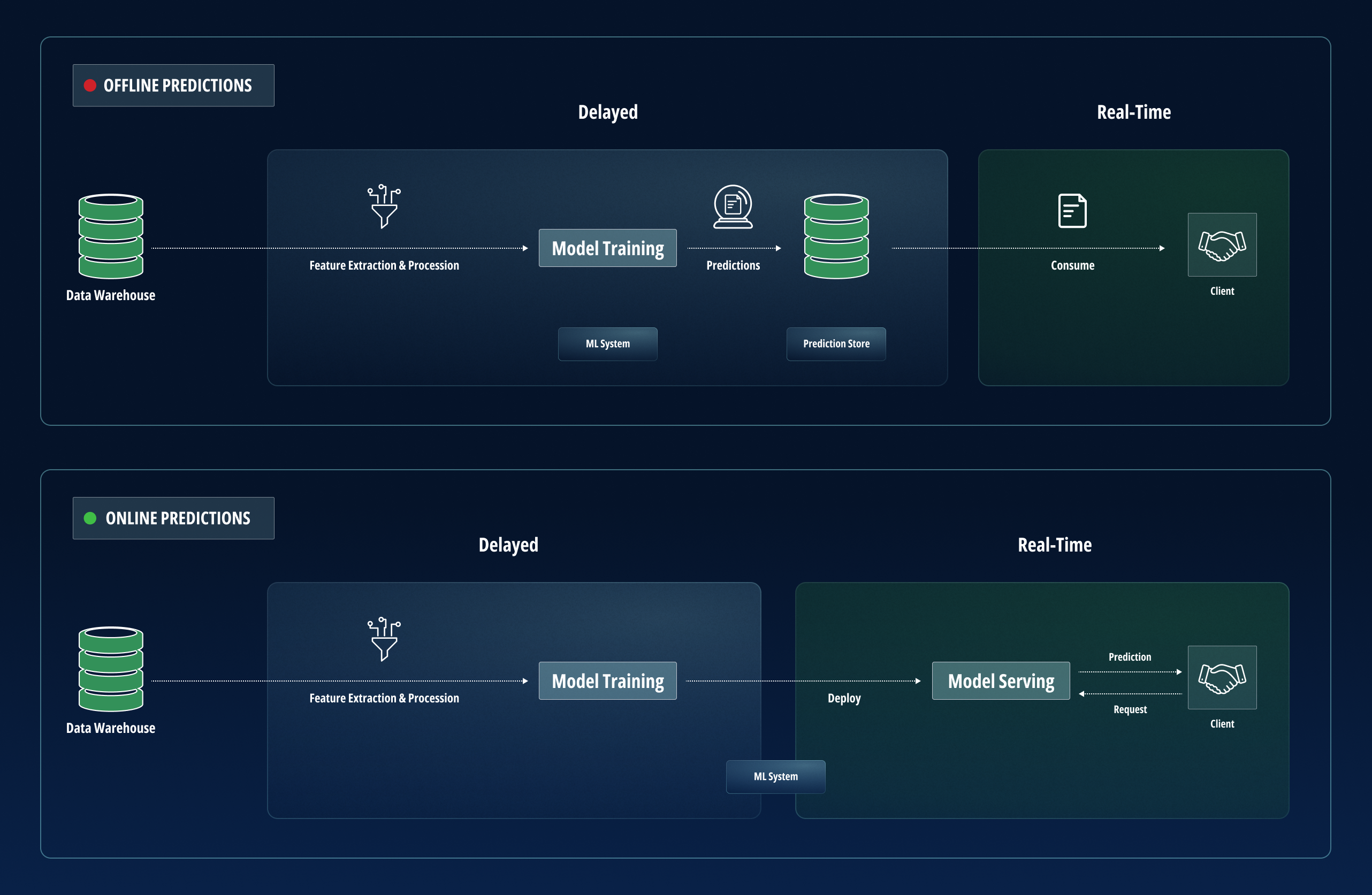
When deciding which method to use, consider questions like:
- How often do we need our model to generate predictions?
- Should model results be based on batch data or individual cases?
- How much computational power can we allocate?
- How complex is our model?
2. Automate Deployment and Testing
It is possible to manage the deployment and testing of a single, small model manually. For larger or multiple models at scale, however, you should automate.
This will enable you to manage individual components more easily, ensure that ML models will be automatically trained with data that is of consistently high quality, run automatic testing (e.g., of data quality and model performance), and scale models automatically in response to current conditions.
3. Monitor, Monitor, Monitor
As we have already covered, a successful deployment process lives and dies with continuous monitoring and improvement. This is because ML models degrade over time, and continuous monitoring means you can highlight potential issues such as model drift and training-serving skew before they cause damage.
Important considerations:
- Initial Data Flow Design: Before you even start collecting data, you’ll need to architect a data flow that can handle both training and prediction data. This involves deciding how data will be ingested, processed, and eventually fed into Evidently for monitoring.
- Data Storage Strategy: Where you store this integrated data is crucial. You’ll need a storage solution that allows for easy retrieval and is scalable, especially if you’re dealing with large volumes of real-time data.
- Automated Workflows: Consider automating the data flow from Seldon and your training data source to Evidently. This could involve setting up automated ETL jobs or utilizing orchestration tools to ensure data is consistently fed into the monitoring tool.
See the following suggested architecture to address this process.
Diagram 6
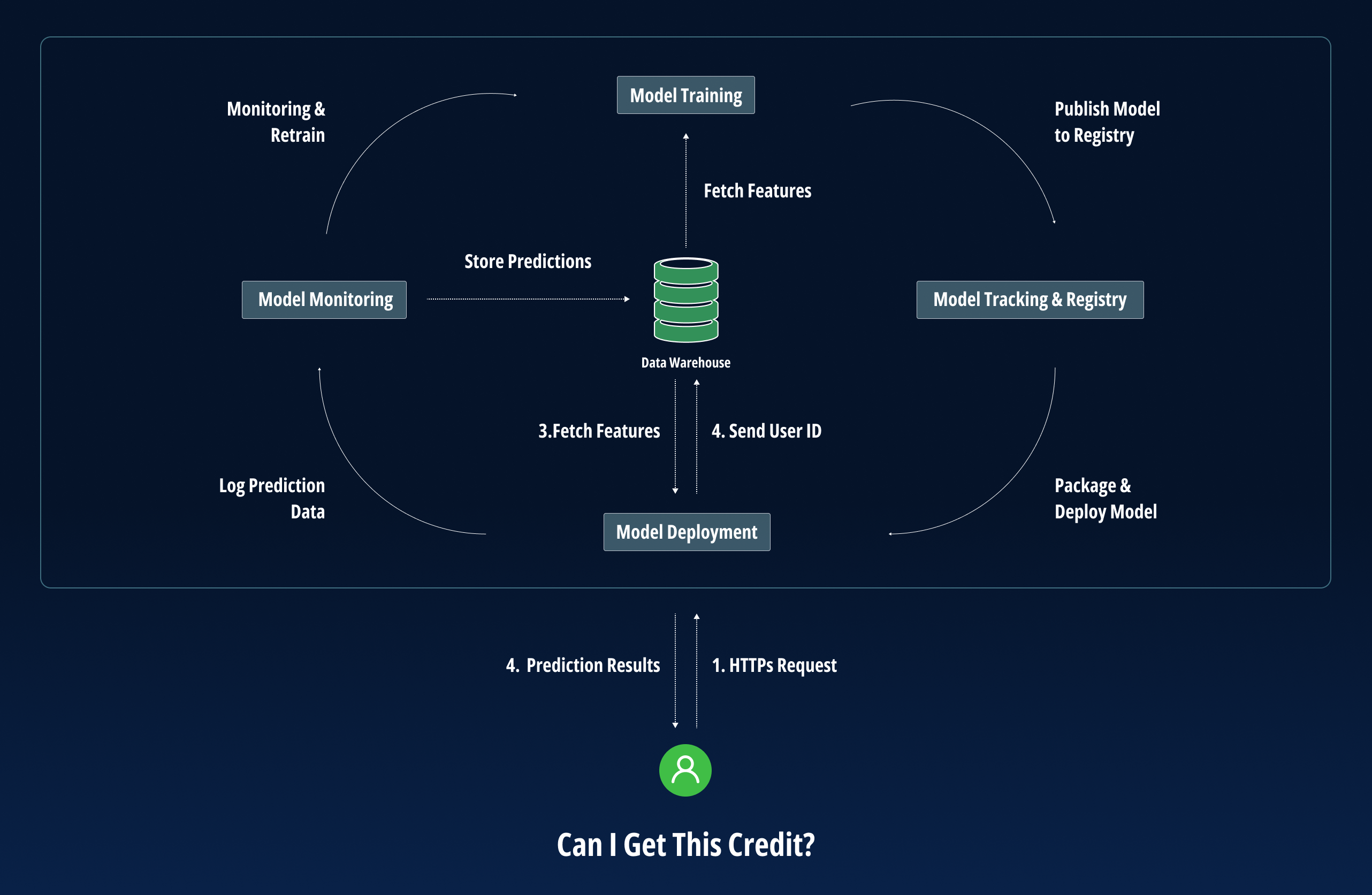
Streamline ML Development
In conclusion, deploying machine learning models in production environments is a complex but crucial process for the successful application of ML technology. The deployment process involves several steps, from planning and model development to optimization, containerization, and continuous monitoring and maintenance. Challenges such as knowledge gaps between teams, infrastructure limitations, scalability issues, and the need for ongoing monitoring can arise, but with careful planning and the right tools and methods, these can be effectively managed. By focusing on important aspects like data storage, choosing appropriate frameworks, collecting feedback, and automating deployment and testing, teams can streamline the deployment process. Ultimately, efficient deployment not only ensures the smooth functioning of ML models but also maximizes their value in solving real-world problems.
Are you looking for a solution for deploying your ML models into production? Book a demo to check out JFrog ML and learn how you can transform your models into applications quickly, efficiently and securely.


