Of course, the focus of the developer is very much on developing useful features as fast as they can. While the operators are looking to increase reliability and reduce risk. Now these things are very much intention. Your developers want to go faster, and typically your operators want to go slower. Now more than ever, the challenge is actually to build reliable, always on, highly scalable applications without compromising on agility, or reliability. Now, as it happens, software has never been easy to write, to run, or indeed to manage. Even with the move to the cloud, and to containerization in recent years, the reality is that there is significant complexity in managing both infrastructure and application through things like scaling, patching, rollouts, and upgrades and of course, dealing with those inevitable infrastructure failures.
Yet, what we’ve seen with the pandemic of the last 18 months is unprecedented demand for agility as much the economy has been forced to rapidly pivot to an online mode. And also, there’s been an increasing desire to outsource infrastructure concerns.
We’ve also seen a really strong need for very responsive infrastructure that can scale up or down very quickly without requiring hours of setup. So these are the types of challenges that serverless computing is uniquely placed to address. Crucially, serverless abstracts away the infrastructure, removing many of the traditional concerns around provisioning and capacity planning and automating the response to infrastructure failures.
Serverless really reduces that operational complexity, and allows your engineers to actually focus on the place they can add value in their applications. With serverless computing, you can build, develop and deploy your workload quickly in a fully automated environment.
There’s no need to provision, patch or manage servers and clusters, and securit, operations and DevOps best practices are built in. So with serverless, the cloud is no longer just a case of renting somebody else’s computer, where you can run your clusters or your VMs.
Instead, the cloud becomes a genuine compute utility, a place to run your app on demand, without hassle, paying only for what you use.
What’s more, serverless abstracts away failures of that infrastructure. So things like machine failures, networking failures, even entire data center failures are handled in a manner which is invisible to your application, and with minimal impact to your users.
Now, of course, everything comes at a price. And the price you’ve traditionally paid for being released from the constraints of infrastructure has been a lack of flexibility.
Serverless platforms have often been very constrained environments, suitable for a particular type of Greenfield application development. But at Google, our serverless container strategy aims to remove those constraints, allowing more and more workloads over time to reap the benefits of running in an entirely serverless manner.
We’re calling this next generation serverless.
There are three key capabilities that make this the next generation are not the serverless that you find elsewhere. The first of these is the idea of having built in DevOps practices and that SRA experience really baked in under the hood. The second is developer centricity. And then finally, a versatility on the platform that you won’t find elsewhere.
So let me talk about each one of these in more detail. Firstly, let me talk about the DevOps and SRA best practices that are built into the platform. So our vision of serverless is a really tight integration of cloud operations, security tools, and CI\CD, which will enable faster software delivery. Through all of that our customers can take advantage of Google’s SRA experience, removing operational overhead, and allowing your team to focus on areas where they can add more value.
As an example, serverless platforms automatically scale up and down. That removes the need for your operations team to plan and provision capacity as load waxes and wanes. So if your application suddenly starts fielding a lot of traffic, maybe because of a big surge in customers or perhaps because you launched a new service. The serverless platform detects that additional load and spins up more resources to handle it. No more dreaded timeouts, no more spinning wheels of death or hour glasses and perhaps crucially, no page is going off for your operations team to provision more VMs.
Likewise, as soon as the demand goes down, the platform takes care of decommissioning those resources. So you’re not paying for compute cycles that you no longer need.
Now, we all know that change is often the cause of outages. And as a result, being able to roll out new software in a way that allows you to spot problems whilst the impact is small, is really critical to reliability.
In our cloud run products, we have a set of traffic management features, which allow you to roll out new versions of your application in parallel with existing ones, and route some small percentage of traffic to the new release. This allows your developers to experiment and test ideas quickly in just a few clicks, driving really quick feedback and agility but without risking large scale outages. We also make sure that your serverless applications have built in security at every layer, features that allow you to ensure that your CI\CD workflow is secure, that your secrets are secure at runtime. And of course, when you’re using cloud run, you’re automatically leveraging the security features, and Google’s data centers and network.
As an example, we’ve just launched a strong integration of cloud run with our cloud secrets manager, which allows you to securely store and retrieve secrets your applications need to run. You can also protect your data and code with customer managed encryption keys, ensuring that only you have access to all of your build artifacts.
A great new feature that we have on cloud run is something called binary authorization. That allows you to enforce a secure software delivery pipeline through policy, ensuring that only containers that have been appropriately built and signed can make it into production. And as part of this, we have an automated container analysis service, which can also check those containers for various standard security vulnerabilities before we deploy them too. We also have integration with cloud armor with Google’s identity aware proxy. And with our egress control staff. Put together that allows you to enforce a security perimeter, limiting both those who can access specific services, and which resources can be accessed by your services running in production.
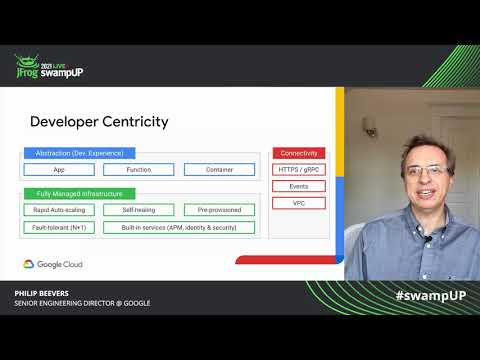
Next up is developer focus. Now, I’ve spent a lot of time hiring engineers over my time in this industry. And I can say with a lot of confidence that attracting and retaining top talent is really hard. Once you get that talent in the door, you want it to be focused on creating value for your business, not dealing with infrastructure problems. Now, as well as abstracting away the infrastructure, it’s also important to have a really great developer experience that supports rapid iteration.
If we want everyone to be able to develop smart, really highly reactive applications, we’ve got to make it easy. And in large enterprises, that’s all about bringing your technical talent closer to where you generate your business value. So to make it easy, we give developers options.
They can start with a container build using their favorite frameworks and toolchain and submit that to be run on cloud run. Alternatively, they can use our build packs to create and deploy applications directly from the source code. With no real need to understand anything about Docker, or containers or clusters.
Developers can quickly deploy their code to cloud run to test and iterate with a single command or alternatively just build and run their container locally. Now, we also see our functions in orchestrations products is key to developer productivity because those products are intentionally designed to make it easy to rapidly combine existing services into new pipelines or new applications. So in particular, our events, our products, which we launched earlier this year, provides an architecture for triggering functions or containers, when particular events happen elsewhere, either in your application or in the infrastructure. So there’s a rich set of events that can be generated either elsewhere in GCP, or created by your application itself. In fact, events arc is integrated with over 60 different event sources within Google Cloud Platform. So that gives you a huge amount of power out of the box.
A typical use case there might be something like triggering some kind of transformation activity once data has been uploaded to a storage bucket, or a database, or BigQuery, or something like that. Now I like to think of these products functions and orchestration together as a little bit like scripting languages for the cloud. And just like scripting languages, they let you tie together existing binaries or services without having to modify them.
We’ve taken this a step further with our new workflows products, which lets you combine those application building blocks together with minimal code.
You can use workflows to integrate with existing code running on cloud run, and Cloud Functions, or indeed any HTTP based API service, which includes, of course, much the rest of GCP.
The third point is versatility. Now, our vision for the future of serverless is that you’ll be able to run literally any type of workload written in any programming languages on our serverless compute products.
We’re a long way down the road to that vision today, but over the coming months and years, you’ll see us adding more and more compute capabilities to our serverless platforms, eventually removing all of the traditional restrictions, which can turn people off of serverless technology. An example of a place we’ve done, this is weird support for WebSockets and streaming gRPC.
We recently announced these on cloud run, and it’s a good example of where we’re increasing versatility and increasing the breadth of workloads that can be run on the platform. With these new additions, you can now get the benefits of serverless to build responsive, high performance streaming applications on the web. And we also added something called min instances to cloud run, which cuts constant time and allows you to run more latency sensitive applications on the platform.
Why do we need this? Well, serverless platforms scale up really quickly but of course, nothing is actually instant. That scaling up takes a little bit of time. When your application is not receiving traffic, cloud run will stop running instances of your containers, and that saves you money. But that means when traffic arrives, we’ll need to start off a new instance of your container. And of course, at that point, we’ll need to run any required initialization code, both in our platform and also in your container. You can avoid that additional latency for that first request, by using the min instances feature to keep the number of instances of your container running at all times.
Now I’m going to hand it over to my colleague Preston, who’s going to show you a demo about how this all works together.
Let’s see some of this developer experience in action. So I’ll go ahead and choose cloud run in the console. We see the no services are deployed yet. So let’s go ahead and create a service. We’re going to call this Hello serverless. We can pick a container we’ve already uploaded. Let’s look at a couple of these settings really quickly. So first thing is I want to actually run this as a specific identity. So I’m going to choose the Hello service account, I can set different amounts of memory or CPU, set the timeout for how long requests can respond, the number of requests handled at one time, whether we keep idle or standby containers available and a ceiling on the number of containers so that we don’t overload downstream databases.
I can easily set environment variables. We can easily create connections to databases. So here we’ll connect to a demo database and here we can also create network allow private network into the VPC. So we can do that.
We can restrict how network arrives to the container and we can enable our built in authentication and authorization layer, as well as trigger this service from other events have happened in the platform. And then we can deploy it. So this will automatically create a fully scaled deployment.
Here we can see the summary information of those settings we picked, we can see the variables, existing connections, all of this is here. This is the first revision, it’s now serving traffic at this public URL. And so that’s running. Again, we can choose to deploy additional revisions and manage traffic and do all sorts of kinds of things.
We have built in metrics here. We can even look at this in YAML, if we want. Now, if we switch over to this project, you can see that we actually have the choice via containers to deploy in almost any language in runtime, you can imagine. And we’ve deployed each of these languages in cloud run. And we’ve deployed one of these into each of the 24 cloud regions Google Cloud supports.
All of these different languages and all of these regions all can funnel all of their operations into the cloud ops suite. So here we see logging, we can do things like easily query for logs in Europe, and run this query. And then we see those results. We can also build dashboards that shows things like request latencies across all these different services, as well as looking at memory utilization.
These are all built in out of the box metrics, regardless of which language and runtime you choose.
So to sum up, we believe the future is serverles and that more and more workloads over time will naturally move to serverless platforms.
That will allow developers to build applications and deliver business value quicker than they ever have done before.
Whilst at the same time, it’ll increase reliability and security by adopting the DevOps best practices that are built into the platform from the ground up.