

Definition
Das Fine-Tuning von LLM-Modellen auf eng fokussierte Datensätze ermöglicht es ihnen, tiefgehendes Domänenwissen zu erwerben, was ihre Genauigkeit erheblich verbessert und ein Verhalten erlaubt, das präzise auf spezifische Anwendungsfälle zugeschnitten ist.
Eine Einführung zum Fine-Tuning von LLMs
Das Aufkommen generativer Modelle – insbesondere von Large Language Models (LLMs) wie ChatGPT und Bard – stellt einen bedeutenden Fortschritt im Bereich der künstlichen Intelligenz dar. Diese Modelle zeichnen sich dadurch aus, dass sie menschenähnliche Texte erzeugen können, und verändern grundlegend, wie wir mithilfe von Maschinen mit Sprache interagieren. In diesem Beitrag geht es um die Feinabstimmung von LLMs mit benutzerdefinierten Datensätzen, um ihre Leistungsfähigkeit und Präzision für spezifische Anwendungsfälle gezielt zu verbessern.
LLMs und generative Modelle verstehen
LLMs, ein zentrales Element generativer Modelle, sind darauf ausgelegt, Texte aus umfangreichen Datensätzen zu verarbeiten und zu erzeugen. Ihr Einsatz in verschiedensten Branchen hat die Customer Experience erheblich verbessert und Unternehmen einen unvergleichlichen Wettbewerbsvorteil verschafft. Von der Automatisierung komplexer Servicedialoge mit Kunden bis hin zur Erstellung personalisierter Inhalte definieren LLMs die technologischen Möglichkeiten neu.
Der Bedarf an Fine-Tuning von LLMs
Warum sollten LLMs finegetunt werden? Trotz ihrer enormen Leistungsfähigkeit stoßen allgemeine LLMs bei spezialisierten Aufgaben mitunter an ihre Grenzen – bedingt durch ihr breites und vielfältiges Trainingsspektrum. Die Feinabstimmung dieser Modelle auf eng fokussierte Datensätze ermöglicht es ihnen, tiefgehendes Domänenwissen zu erwerben, was ihre Genauigkeit deutlich verbessert und ein Verhalten erlaubt, das präzise auf spezifische Anwendungen zugeschnitten ist.
Leistungssteigerung von Modellen durch Fine-Tuning
- Domänenspezifisches Wissen: Durch das Fine-Tuning erhalten LLMs ein tiefgreifendes Verständnis für spezialisierte Bereiche – sei es juristischer Fachjargon, medizinische Terminologie oder die Feinheiten im Kundenservice.
- Verbesserte Genauigkeit und Relevanz: Durch das Lernen anhand domänenspezifischer Beispiele liefern finegetunte Modelle Antworten, die nicht nur präzise, sondern auch hochgradig relevant für die jeweilige Aufgabe sind.
Generalisierung vs. Spezialisierung
Das Gleichgewicht zwischen Generalisierung und Spezialisierung ist entscheidend. Während Allzweck-Modelle vielseitig einsetzbar sind, fehlt ihnen oft die nötige Tiefe für spezialisierte Anwendungsbereiche. Spezialisierte Modelle hingegen überzeugen in bestimmten Kontexten, indem sie Erkenntnisse und Lösungen liefern, die eng auf die Anforderungen einer bestimmten Domäne abgestimmt sind. Die Feinabstimmung bildet die Brücke zwischen beiden Ansätzen und ermöglicht es, Modelle zu entwickeln, die sowohl anpassungsfähig als auch fachlich fundiert sind.
Praxisnahe Anwendungsfälle – Die Vielseitigkeit über Branchen hinweg
- Analyse juristischer Dokumente: Spezialisierte LLMs können komplexe juristische Texte analysieren und interpretieren und so bei Recherchen sowie der Vorbereitung von Fällen unterstützen.
- Medizinische Forschung: Finegetunte Modelle können umfangreiche Forschungsdatenbanken durchsuchen, relevante Studien identifizieren und Erkenntnisse in einem Bruchteil der Zeit zusammenfassen, die ein Mensch dafür benötigen würde.
- Kundenservice: Automatisierte Beantwortung von Kundenanfragen mit differenziertem Verständnis und Kontextbewusstsein – das verkürzt Wartezeiten und steigert die Kundenzufriedenheit.
- Content-Erstellung: Artikel, Geschichten und Berichte generieren, die auf bestimmte Zielgruppen, Stile oder Formate zugeschnitten sind – für höhere Relevanz und größere Reichweite.
- Gesundheitswesen: Zusammenfassung von Patientendaten, Fachliteratur und Forschungsergebnissen zur Unterstützung von Diagnose- und Behandlungsprozessen.
Der Fine-Tuning-Prozess
Das Fine-Tuning eines LLM ist ein vielschichtiger Prozess, der mehrere zentrale Phasen umfasst – von der Vorbereitung des Datensatzes über das Training bis hin zur Bereitstellung des Modells und der kontinuierlichen Optimierung.
Ein Modell für das Fine-Tuning von LLMs auswählen
Die Wahl des richtigen Modells ist der erste Schritt auf dem Weg zum Fine-Tuning. In diesem Fall erfolgt das Fine-Tuning eines LLMs von Hugging Face – einer Plattform, die für ihr umfangreiches Repository an Open-Source-Modellen und ihre lebendige Community bekannt ist und somit einen idealen Ausgangspunkt darstellt. Für diese Anleitung verwenden wir das Open-Source-Modell DialoGPT-large von Microsoft, das sich durch Robustheit und Vielseitigkeit in der Textgenerierung auszeichnet.
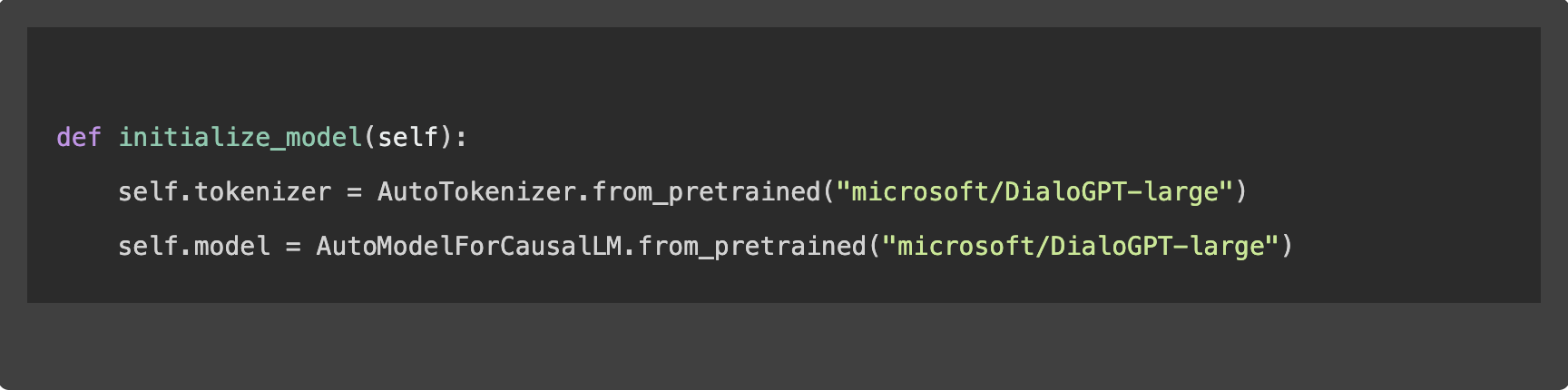
1. Initialisierung des Modells
Die Einleitung des Fine-Tuning-Prozesses beginnt mit dem Laden des ausgewählten Modells und des zugehörigen Tokenizers, der den Text für die Verarbeitung durch das Modell vorbereitet:
2. Fine-Tuning des Modells
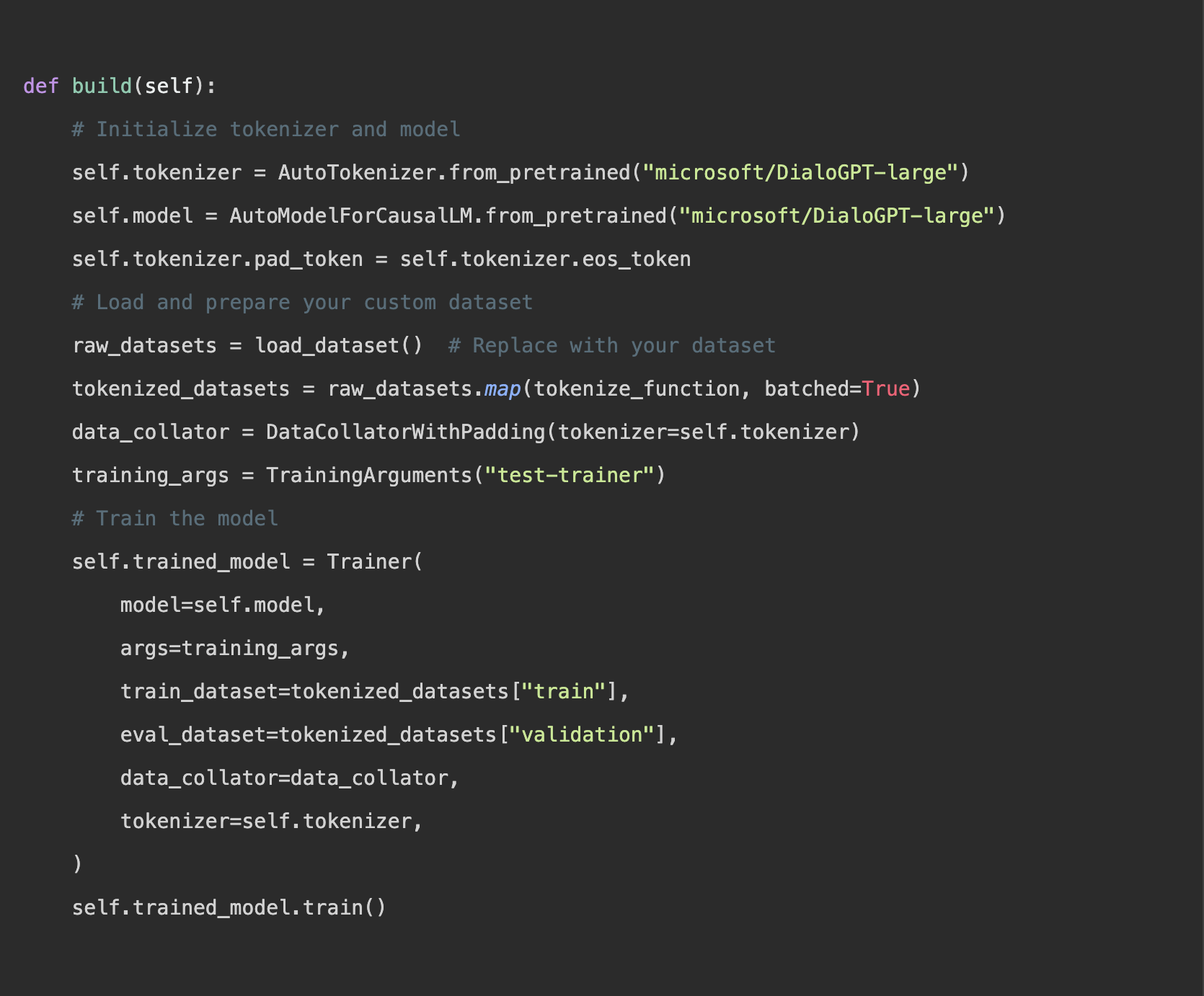
Der Kern des Fine-Tunings besteht darin, das Modell an den eigenen Datensatz anzupassen. So kann es aus spezifischen Daten lernen und sich besser auf die jeweilige Aufgabe ausrichten:
3. Für Inferenz vorbereiten
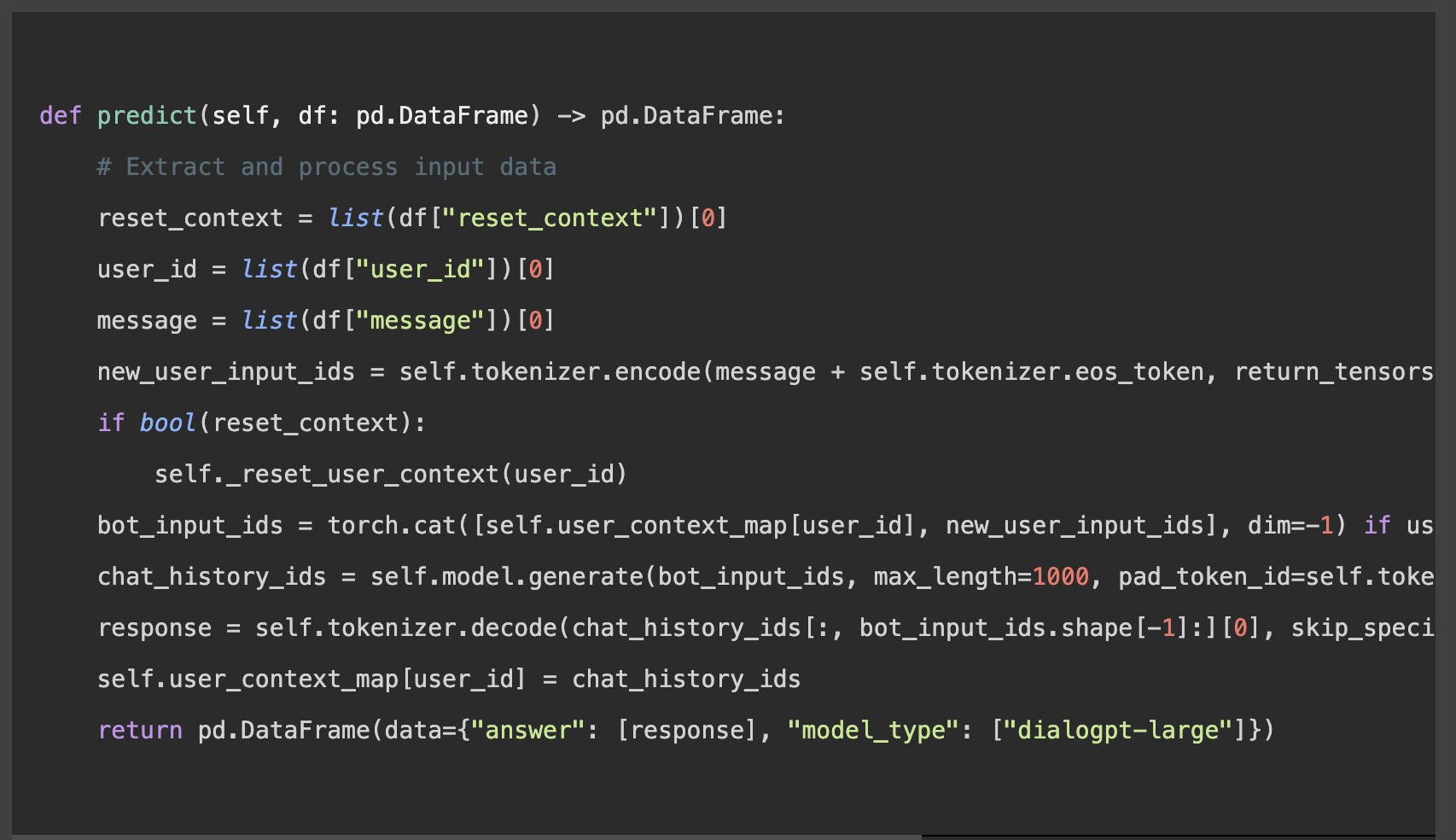
Um Vorhersagen zu ermöglichen, muss sichergestellt werden, dass die Daten korrekt formatiert sind, sodass Kontext und Benutzerinteraktionen erhalten bleiben:
4. Vorhersagen
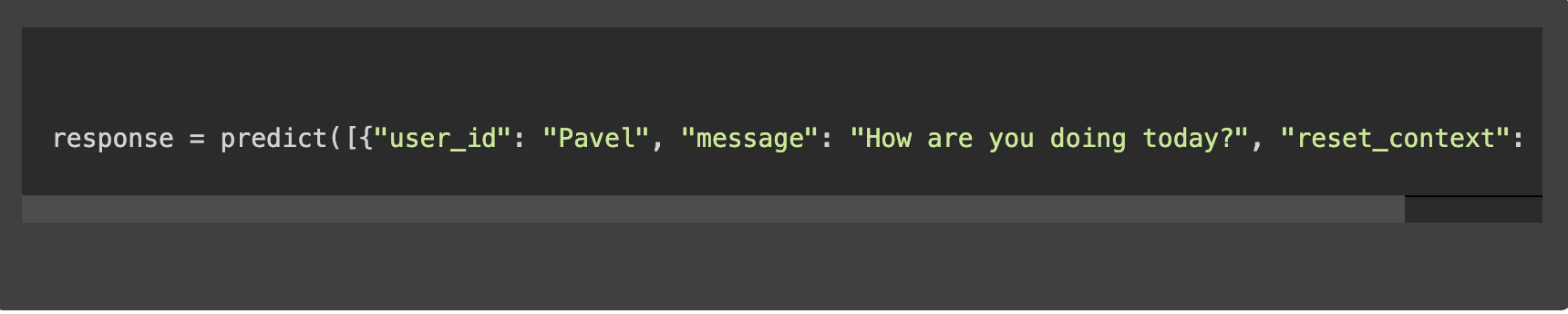
Ein Beispielaufruf der Vorhersagefunktion könnte folgendermaßen aussehen:
Wichtige Aspekte beim Fine-Tuning eines LLM
Datenvorbereitung und -auswahl
Die Grundlage eines effektiven Fine-Tunings ist die Zusammenstellung eines hochwertigen, relevanten Datensatzes. Dieser Datensatz steuert nicht nur den Lernprozess des Modells, sondern definiert auch den Rahmen seines Fachwissens.
Um beispielsweise ein LLM für die Optimierung eines technischen Support-Chatbots zu finetunen, umfasst der Prozess mehrere klar strukturierte Schritte:
- Datenerfassung: Zusammenstellung eines Datensatzes aus Kundenservice-Interaktionen mit Fokus auf technische Anfragen und Antworten, z. B. 50.000 Einträge.
- Datenbereinigung: Entfernen irrelevanter Inhalte wie personenbezogener Informationen und themenfremder Gespräche, um sicherzustellen, dass das Modell aus hochwertigem Material lernt.
- Annotation: Optionale Kategorisierung der Daten (z. B. nach Fehlertyp wie Installations- oder UI-Probleme), damit das Modell verschiedene Problemfelder besser erkennt.
- Datensatzaufteilung: Aufteilung des bereinigten Datensatzes in Trainings- (80 %), Validierungs- (10 %) und Testdaten (10 %), um den Lern- und Bewertungsprozess zu unterstützen.
- Vorverarbeitung: Nutzung des Tokenizers des Modells, um den Text in ein verständliches Format zu bringen und für die Feinabstimmung vorzubereiten.
Dieser Ansatz stellt sicher, dass das Chatbot-Modell gezielt auf Softwareprobleme abgestimmt ist – und so relevanten, präzisen Support bieten kann.
Rechenressourcen
Die Feinabstimmung von Large Language Models (LLMs) erfordert erhebliche Rechenleistung und macht in der Regel den Einsatz von GPUs oder Cloud-Computing-Ressourcen notwendig, um Arbeitslasten effizient zu bewältigen. Um diesen Anforderungen zu begegnen, bieten sich Cloud-Plattformen wie AWS oder Google Cloud an, die skalierbare Rechenressourcen zur Verfügung stellen. Zusätzlich tragen Optimierungstechniken wie Model Pruning und Quantisierung dazu bei, die Modellgröße und den Ressourcenverbrauch zu reduzieren, ohne dabei die Leistungsfähigkeit wesentlich zu beeinträchtigen. Diese Strategien sorgen dafür, dass der Fine-Tuning-Prozess sowohl praktikabel als auch kosteneffizient bleibt.
Hyperparameter-Tuning und Modelltraining
- Lernrate: Bestimmt die Größe der Schritte, die das Modell während der Optimierung macht. Ist die Lernrate zu hoch, kann das Modell optimale Lösungen verfehlen; ist sie zu niedrig, verlangsamt sich das Training erheblich. Ein gängiger Ansatz ist es, mit einer Lernrate von 5e-5 zu starten und sie basierend auf der Validierungsleistung anzupassen.
- Batch-Größe: Gibt an, wie viele Trainingsbeispiele pro Iteration verwendet werden. Kleinere Batch-Größen führen oft zu einer stabileren Konvergenz, während größere den Trainingsprozess beschleunigen können. Für Fine-Tuning-Aufgaben sind Batch-Größen von 16 oder 32 üblich.
- Anzahl der Epochen: Gibt an, wie oft der Trainingsdatensatz vollständig durchlaufen wird. Mehr Epochen können das Lernen verbessern – bis zu einem Punkt, an dem Überanpassung auftreten kann. Ein Einstieg mit 3 bis 5 Epochen hat sich in der Praxis bewährt.
Die Anpassung dieser Hyperparameter erfordert ein ausgewogenes Verhältnis zwischen Geschwindigkeit und Genauigkeit. Effektives Tuning bedeutet oft, mehrere Trainingsläufe mit unterschiedlichen Einstellungen durchzuführen und den Validierungsverlust zu überwachen, um die optimale Konfiguration zu finden.
Experimente und Validierung
Experimente und Validierung sind entscheidende Bestandteile beim Fine-Tuning von LLMs, um sicherzustellen, dass Modelle sowohl leistungsfähig als auch generalisierbar sind.
- A/B-Tests: Dabei werden Experimente durchgeführt, bei denen zwei oder mehr Hyperparameter-Konfigurationen parallel getestet und miteinander verglichen werden. Zum Beispiel kann eine Version A des Fine-Tuning-Prozesses mit einer Lernrate von 5e-5 und eine Version B mit 3e-5 laufen. Durch den Vergleich der Ergebnisse auf einem Validierungsdatensatz lässt sich ermitteln, welche Lernrate zu besseren Resultaten führt.
- Validierungsdatensätze: Diese sind ein zentraler Bestandteil des Trainingsprozesses. Sie dienen dazu, die Modellleistung anhand von Daten zu bewerten, die während des Trainings nicht gesehen wurden. So lässt sich Overfitting vermeiden – also der Fall, dass ein Modell zwar bei Trainingsdaten gut, bei unbekannten Daten jedoch schlecht abschneidet. Nach jeder Epoche wird z. B. die Genauigkeit oder der Modellverlust (“model loss”) anhand des Validierungssets überprüft. Dieser Rückkopplungsprozess ermöglicht gezielte Anpassungen vor der finalen Bewertung und stellt sicher, dass das Modell robust ist und auch mit neuen Daten zuverlässig arbeitet.
Bereitstellung und kontinuierliche Optimierung
Nach dem sorgfältigen Prozess der Auswahl, Initialisierung und des Fine-Tunings markiert die Bereitstellung des Modells in einer realen Umgebung einen entscheidenden Meilenstein. In dieser Phase zeigt sich, wie leistungsfähig das Modell im tatsächlichen Einsatz ist – sei es bei der Automatisierung von Kundenservice-Antworten oder der Generierung von Inhalten. Die Bereitstellung eines finegetunten Modells zur Optimierung eines Kundenservice-Chatbots umfasst dabei nicht nur die technische Integration, sondern auch den Aufbau einer Infrastruktur, die Echtzeit-Interaktionen unterstützt – ein Vorhaben, das Know-how aus den Bereichen Data Science und Engineering erfordert.
Doch mit der Bereitstellung ist der Prozess nicht abgeschlossen. Kontinuierliche Optimierung spielt eine zentrale Rolle, um die Relevanz und Leistungsfähigkeit des Modells langfristig zu sichern. Dieser kontinuierliche Zyklus aus Monitoring, Bewertung und Aktualisierung stellt sicher, dass das Modell sich an neue Daten, Trends und Anforderungen anpasst. Ein Beispiel: Ein E-Commerce-Empfehlungssystem, das auf früheren Verkaufsdaten finegetunt wurde, muss regelmäßig aktualisiert werden, um neue Produktlinien und verändertes Kaufverhalten zu berücksichtigen – nur so bleibt es genau und wirkungsvoll.
Management des Software-Lebenzyklus
Ein effektives Lebenszyklus-Management ist unerlässlich – es umfasst sowohl Monitoring-Tools als auch kontinuierliches Lernen. Der Einsatz von Plattformen wie TensorBoard oder Weights & Biases ermöglicht es Teams, Leistungsmetriken zu überwachen und frühzeitig zu erkennen, wann Modelle abweichen oder an Genauigkeit verlieren. Dieser proaktive Ansatz stellt sicher, dass Modelle auch lange nach ihrer ersten Bereitstellung effizient und wirkungsvoll bleiben.
Kontinuierliches Lernen, bei dem neue Daten regelmäßig in den Trainingsdatensatz integriert werden, sorgt dafür, dass sich das Modell kontinuierlich weiterentwickelt und an sein operatives Umfeld anpasst. Diese Anpassungsfähigkeit ist besonders in dynamischen Feldern wie News-Suchmaschinen oder in der Finanzanalyse entscheidend – dort ist aktuelles Wissen essenziell, um die Leistungsfähigkeit und Relevanz des Modells dauerhaft sicherzustellen.
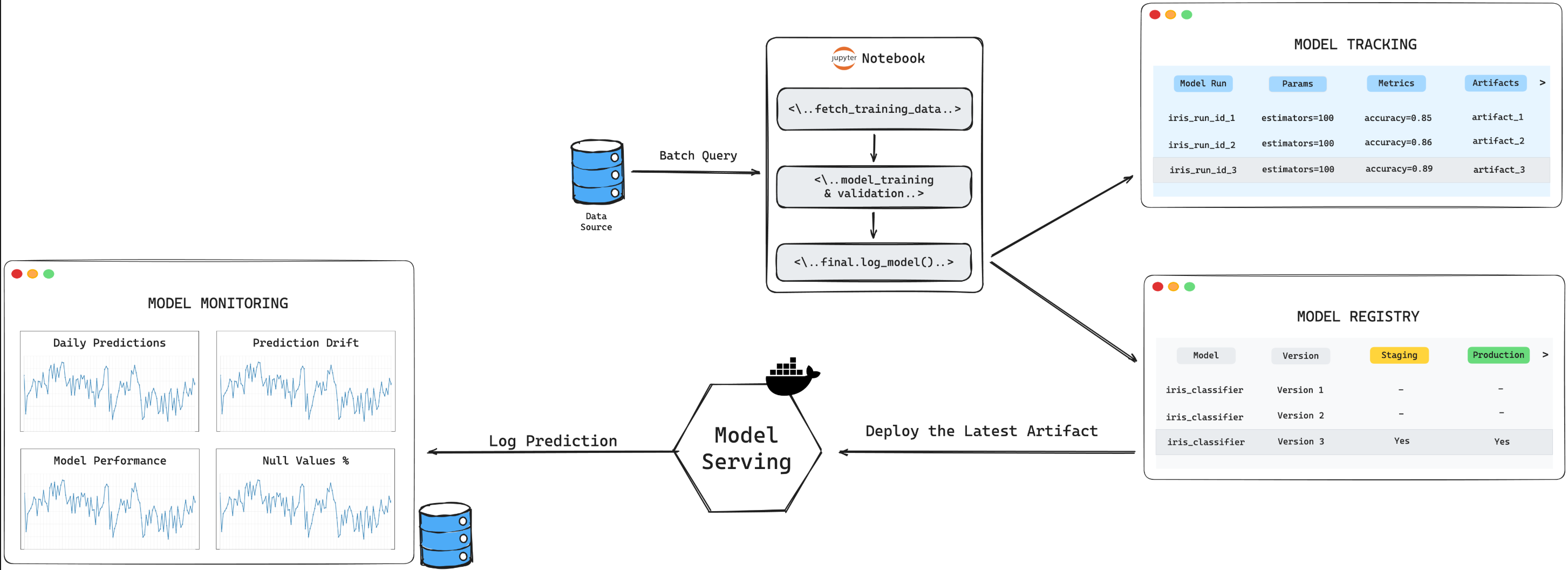
Die Zukunft von LLMs und die Rolle von ML-Anwendern
Die Zukunft von Large Language Models (LLMs) verspricht noch ausgefeiltere und vielseitigere Einsatzmöglichkeiten in unterschiedlichsten Branchen. Mit der Weiterentwicklung dieser Modelle wird die Expertise von Machine-Learning-Anwendern aus mehreren Gründen unverzichtbar:
- Strategische Weiterentwicklung: ML-Experten spielen eine zentrale Rolle bei der Ausrichtung der LLM-Entwicklung hin zu effizienteren, präziseren und kontextsensibleren Modellen. Ihre Fachkenntnis hilft beispielsweise dabei, Modelle wie GPT-4 für spezialisierte Aufgaben – etwa juristische Analysen oder personalisierte Bildung – gezielt weiterzuentwickeln, sodass diese hochspezialisierten Content verstehen und erzeugen können.
- Feinabstimmung auf spezifische Anforderungen: Durch gezieltes Fine-Tuning passen ML-Anwender universelle Modelle an branchenspezifische Bedürfnisse an. Ein Beispiel: Ein Modell zur Unterstützung bei medizinischen Diagnosen kann mithilfe umfangreicher medizinischer Literatur und Patientendaten trainiert werden. Die richtige Wahl von Datensätzen und Hyperparametern stellt sicher, dass das Modell präzise und zuverlässige Ergebnisse liefert.
- Ethische Anwendung: Die verantwortungsvolle und ethisch korrekte Nutzung von LLMs ist von zentraler Bedeutung. ML-Anwender nehmen hier eine Schlüsselrolle ein – etwa bei der Reduktion von Verzerrungen (Bias) und beim Schutz sensibler Daten. So entwickeln und überwachen sie zum Beispiel Fairness-Frameworks für den Einsatz von LLMs im Recruiting, um diskriminierende Praktiken zu vermeiden.
Mit der zunehmenden Integration von LLMs in industrielle Prozesse wächst auch die Verantwortung und Bedeutung von ML-Anwendern. Sie nehmen eine Schlüsselrolle ein, damit diese leistungsstarken Werkzeuge verantwortungsvoll, innovativ und im Sinne der Gesellschaft eingesetzt werden.
Zusammenfassung
Das Fine-Tuning von LLMs mit benutzerdefinierten Datensätzen ist ein vielschichtiger Prozess, der von der sorgfältigen Auswahl und Aufbereitung der Daten bis hin zur ethisch verantwortungsvollen Bereitstellung und kontinuierlichen Betreuung des Modells reicht. Dieser Weg verbessert nicht nur die Leistungsfähigkeit und Präzision des Modells, sondern hebt auch die zentrale Rolle von Machine-Learning-Anwendern hervor – bei der Bewältigung technischer Herausforderungen ebenso wie bei der Berücksichtigung ethischer Aspekte. Mit der fortschreitenden Entwicklung von LLMs wächst auch ihr Potenzial, ganze Branchen grundlegend zu verändern. Dabei entsteht ein wachsender Bedarf an kontinuierlicher Innovation und verantwortungsvollem Umgang mit KI – sowohl in der Entwicklung als auch im praktischen Einsatz.



