

Was ist ein Feature Store im Machine Learning – und brauche ich einen?

Von
18 min read

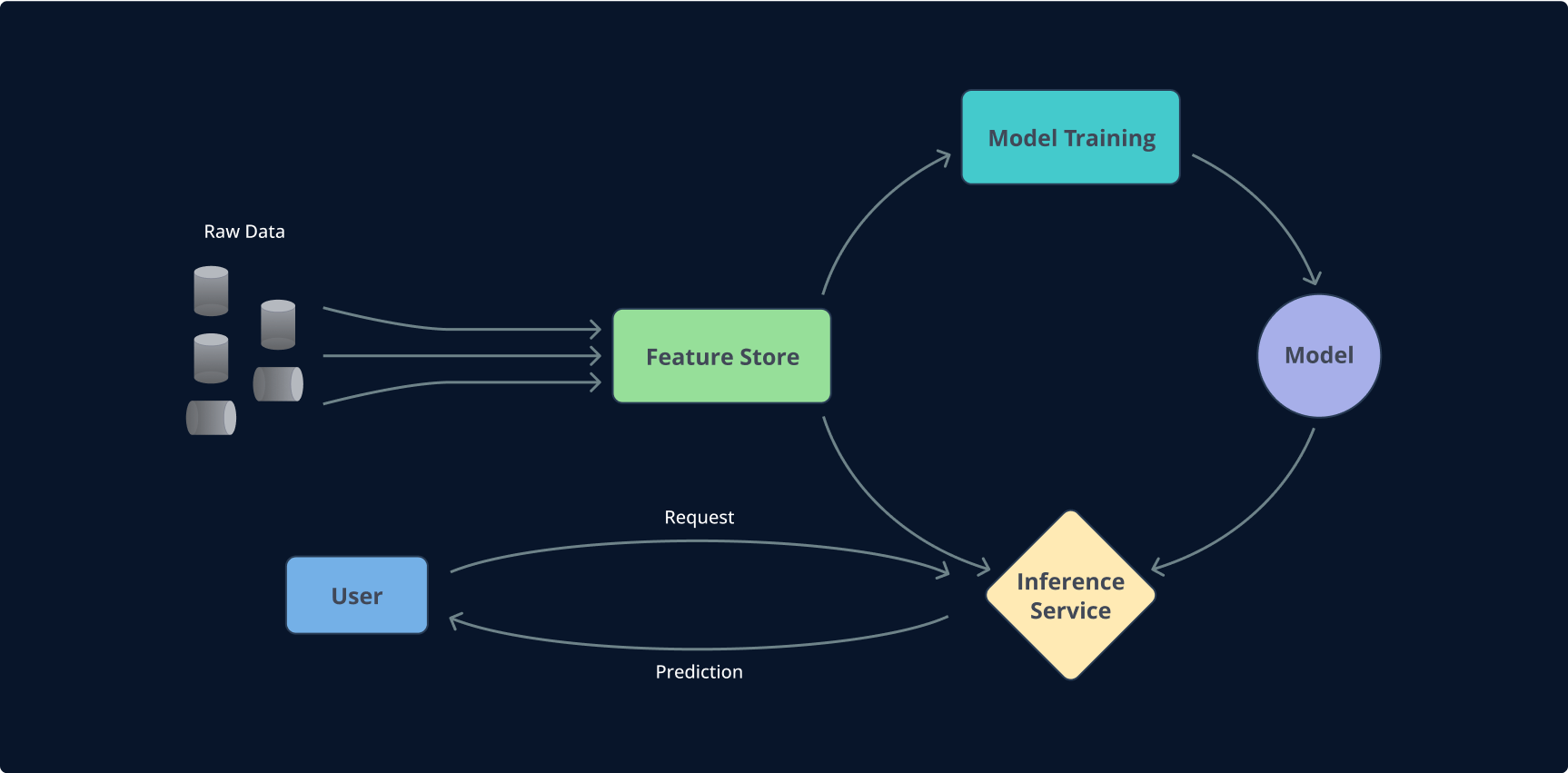
Im Wesentlichen ist ein Feature Store ein spezielles Repository, in dem Merkmale (Features) methodisch gespeichert und angeordnet werden, in erster Linie zum Trainieren von Modellen durch Data Scientists und zur Erleichterung von Vorhersagen in Anwendungen, die mit trainierten Modellen ausgestattet sind. Er ist ein zentraler Sammelpunkt, an dem Sammlungen von Merkmalen aus einer Vielzahl von Datenquellen formuliert oder geändert werden können. Darüber hinaus ermöglicht er die Erstellung und Verbesserung neuer Datensätze aus diesen Merkmalsgruppen, die für Modelle in der Trainingsphase oder für Anwendungen bestimmt sind, die es vorziehen, einfach vorberechnete Merkmale für ihre Vorhersageanalysen abzurufen.
Was ist ein Feature Store – Ihre ML-Vorratskammer
Was eignet sich besser, um komplexe Machine-Learning-Konzepte zu entmystifizieren, als der Vergleich mit etwas so Vertrautem wie Essen? Wie die richtigen Zutaten und deren Zubereitung beim Kochen entscheidend sind, funktioniert auch auf ähnliche Weise der Umgang mit Daten im Machine Learning. Um dieses Konzept greifbarer zu machen, verwenden wir eine Küchen-Analogie, um eine der Schlüsselkomponenten in ML-Workflows zu erklären: den Feature Store.
Stellen Sie sich vor, Sie arbeiten an einem Machine-Learning-Projekt und haben all diese Zutaten (Daten), die Sie vorbereiten (verarbeiten) müssen, bevor Sie ein großartiges Modell „kochen“ können. In diesem Szenario ist ein Feature Store wie Ihre zentrale Vorratskammer, in der Sie alle vorbereiteten Zutaten (ML-Features) griffbereit lagern.
Was sind diese ML-Features? Es sind sorgfältig ausgewählte und transformierte Datenpunkte, die in Ihre Machine-Learning-Modelle eingespeist werden. Denken Sie an sie als das geschnittene Gemüse, die marinierten Fleischstücke oder Gewürze, die Sie im Vorfeld zubereitet haben. Sie möchten, dass diese vorbereiteten Zutaten konsistent, hochwertig und jederzeit verfügbar sind, wenn Sie verschiedene Gerichte (Modelle) zubereiten.
Ein Feature Store hält all diese vorbereiteten Zutaten an einem Ort bereit. Er stellt sicher, dass – wann immer Sie oder Ihre Teammitglieder kochen (Modelle bauen) – alle Zutaten von derselben Qualität verwenden. So vermeiden Sie, dass eine Person alten Knoblauch verwendet, während eine andere frischen nimmt, was zu unterschiedlichen Geschmäckern (Modellleistungen) führt.
Zusammengefasst: Ein Feature Store im ML ist wie Ihre Daten-Vorratskammer. Er hilft dabei, vorbereitete Zutaten (Features) frisch, konsistent und einsatzbereit zu halten, was den Kochvorgang (Modellierungsprozess) erheblich reibungsloser und zuverlässiger macht.
Der Zweck von Feature Stores
Feature Stores gibt es schon seit einiger Zeit, angefangen bei Konzepten wie Ubers Michelangelo und Airbnbs Zipline, und sie existieren in verschiedenen Ausprägungen. Einige sind Open Source und fokussieren sich auf idiomatische Feature-Beschreibungen, während andere eher „tabellarisch“ und auf feste Datenschemata ausgerichtet sind.
In diesem Abschnitt betrachten wir die Hauptziele, die Feature Stores erfüllen – ohne uns darauf zu konzentrieren, wie sie gebaut sind. Auf die technischen Aspekte gehen wir später ein.
Feature Stores sind beim Einsatz von ML in der Produktion aus drei Hauptgründen entscheidend:
- Wiederverwendbarkeit von Features: Teams arbeiten oft isoliert und entwickeln Modelle, die dieselben Features nutzen. Diese werden jedoch unterschiedlich definiert und separat berechnet, was zu doppeltem Aufwand und höheren Rechen- und Speicherkosten führt. Feature Stores fungieren als Hub zur Standardisierung von ML-Features. Mit Feature Stores kann ein ML-Team die Features eines anderen Teams verwenden. Da diese Features organisationsweit katalogisiert und vor der Nutzung vorkalkuliert werden, spart die Organisation Cloud-Kosten, indem die gleiche Feature-Berechnung nicht mehrfach durchgeführt werden muss.
- Standardisierte Feature-Definitionen: Aufbauend auf dem vorherigen Punkt: Wenn ein Team ein Feature-Set für sein Modell definiert, wird oft nicht dokumentiert, wie diese Features extrahiert und berechnet werden. Mit einem Feature Store folgen Datenquelle und Feature-Transformation einem konsistenten und leicht verständlichen Muster, was die Wiederverwendung über Teams hinweg erleichtert.
- Konsistenz zwischen Training und Serving: Feature Engineering ist nicht nur in Notebooks von Data Scientists relevant – ein großer Teil der ML-Features wird in Echtzeitmodellen verwendet. Es ist entscheidend, dass Daten zwischen Training und Serving gleich behandelt werden, um konsistente Leistungen bei Echtzeitvorhersagen sicherzustellen. Diese Konsistenz wird als “Training-Serving Skew” bezeichnet.
Darüber hinaus ist zu beachten, dass Data Scientists oft keinen direkten Zugriff auf Datenpipelines haben – das fällt eher in den Aufgabenbereich des Data Engineering. Mit einem Feature Store kann die Feature-Engineering-Logik aus einem Notebook auch die Trainings- und Inferenz-Feature-Sets in der Produktion speisen, sodass Data Scientists ihre Modelle selbst operationalisieren können.
Das bedeutet nicht, dass jedes Data-Science-Team Zugriff auf alle Datenquellen haben wird – tatsächlich enthalten viele Feature-Store-Lösungen Governance- und Compliance-Funktionen, die bestimmten Teams den Zugriff auf spezifische Daten und Features erlauben und dennoch eine einfache Erkundung ermöglichen.
Schließlich sind Feature Stores Speichersysteme für Features, die es ermöglichen, Feature-Vektoren basierend auf ihren zugehörigen Entitäten mit sehr geringer Latenz abzurufen. Diese Fähigkeit bedeutet, dass Modelle, die typischerweise Vorhersagen in Batches durchführen, weil sie vorverarbeitete Features benötigen, nun in Echtzeit laufen können und den Feature Store bei jeder benötigten Eingabe für eine Vorhersage abfragen.
Von Rohdaten zu ML-Features
Features im Machine Learning sind vergleichbar mit den Bausteinen, mit denen Modelle die Welt verstehen und vorhersagen können. Stellen Sie sich Rohdaten als Rohmaterial vor – sie sind reichlich vorhanden, vielfältig, oft unstrukturiert und unordentlich. Diese Daten können alles sein: Zahlenreihen in einer Datenbank, Texte aus Kundenfeedback oder auch Pixel in einem Foto.
Die Umwandlung dieser Rohdaten in Features ist ein transformativer Prozess. Es ist wie das Veredeln von Erz zu Gold; die Daten werden bereinigt, geformt und in eine Struktur gebracht, sodass die Machine-Learning-Modelle diese nicht nur verstehen, sondern auch daraus lernen können. Diese Transformation, bekannt als Feature Engineering, ist eine Kunst für sich, die sowohl technisches Können als auch Kreativität erfordert.
Sobald diese Features erstellt sind, werden sie – häufig in einem Feature Store – gespeichert und stehen bereit, um von Machine-Learning-Modellen abgerufen zu werden. In dieser organisierten Form werden sie zu den entscheidenden Zutaten für das Trainieren von Modellen und für präzise Vorhersagen. Features bilden die Brücke zwischen der chaotischen Welt der Rohdaten und der geordneten Domäne der prädiktiven Analytik und ermöglichen es KI-Systemen, die Welt zu verstehen und mit ihr zu interagieren.
Die Rolle von Feature Stores in Data-Science-Workflows
Feature Stores sind zu einem Eckpfeiler in der Data-Science-Landschaft geworden und revolutionieren die Art und Weise, wie Machine-Learning-Modelle trainiert und operationalisiert werden. Ihre Einführung hat eine entscheidende Lücke im Machine-Learning-Workflow geschlossen – insbesondere in groß angelegten Unternehmensumgebungen, in denen die Operationalisierung von Machine Learning eine große Herausforderung darstellt.
Zentrale Verwaltung und Zugänglichkeit von Features
Das Herzstück eines Feature Stores ist seine Fähigkeit, sowohl historischen als auch aktuellen Feature-Datenzugriff zu verwalten und bereitzustellen. Diese Verwaltung umfasst die Erstellung von zeitlich korrekten Datensätzen aus historischen Feature-Daten. Im Wesentlichen erfüllen Feature Stores eine doppelte Rolle: Sie fungieren als Data Warehouse für ML-Features, das die Entdeckung, Überwachung, Analyse und Wiederverwendung von Features innerhalb einer Organisation ermöglicht, sowie als operativer Speicher für vorkalkulierte Features, die von Online-Modellen zur Anreicherung ihrer Feature-Vektoren mit historischen und kontextbezogenen Daten verwendet werden.
Der Feature Store: Ein Hub für Zusammenarbeit und Konsistenz
Der Feature Store ist nicht nur ein Speicherplatz, sondern eine dynamische Umgebung, in der Data Scientists Feature-Gruppen aus verschiedenen Datenquellen erstellen oder aktualisieren können. Diese Feature-Gruppen werden dann entweder zum Trainieren von Modellen oder für Vorhersagen in Anwendungen verwendet, die auf trainierte Modelle zurückgreifen. Ein entscheidender Aspekt von Feature Stores ist ihre Fähigkeit, die Entdeckung, Dokumentation und Wiederverwendung von Features zu fördern und deren Korrektheit für Batch- und Online-Anwendungen sicherzustellen. Diese Fähigkeit ist besonders vorteilhaft, um konsistente Feature-Berechnungen über Batch- und Serving-APIs hinweg zu gewährleisten.
Echtzeitanwendungen verbessern
Ein praktisches Beispiel für die Wirkung eines Feature Stores bei E-Commerce-Empfehlungssystemen: Hier können Benutzeranfragen, die inhaltlich nur wenig Informationen enthalten, mit vorkalkulierten Features aus dem Feature Store angereichert werden. Dieser Anreicherungsprozess verwandelt ein informationsarmes Signal in ein reichhaltiges, indem Features zur Benutzerhistorie und zum aktuellen Kontext – wie frühere Interaktionen oder momentan beliebte Produkte – einbezogen werden. So entstehen AI-gestützte Anwendungen, die personalisierte und relevante Nutzererlebnisse bieten.
Feature Stores fungieren als kritische Datenschicht, die Feature-Pipelines, Trainingspipelines und Inferenzpipelines miteinander verbindet. Sie sind im Grunde duale Datenbanksysteme mit einem spaltenorientierten Speicher für historische (Offline-)Feature-Daten und einem zeilenorientierten Speicher mit niedriger Latenz für das Bereitstellen von vorkalkulierten Features an Online-Anwendungen. Diese Architektur ermöglicht es Feature Stores, sich nahtlos in bestehende Enterprise-Dateninfrastrukturen und ML-Tools zu integrieren und unterschiedliche organisatorische Anforderungen zu bedienen.
Zusammengefasst haben Feature Stores den Umgang mit Feature Engineering und Management in der Datenwissenschaft maßgeblich verändert. Sie rationalisieren Workflows, fördern die Zusammenarbeit, sichern Konsistenz in der Feature-Nutzung und unterstützen die Anpassungsfähigkeit von ML-Anwendungen an reale Szenarien. Diese Entwicklung stellt einen bedeutenden Fortschritt bei der Operationalisierung von Machine Learning im großen Maßstab dar.
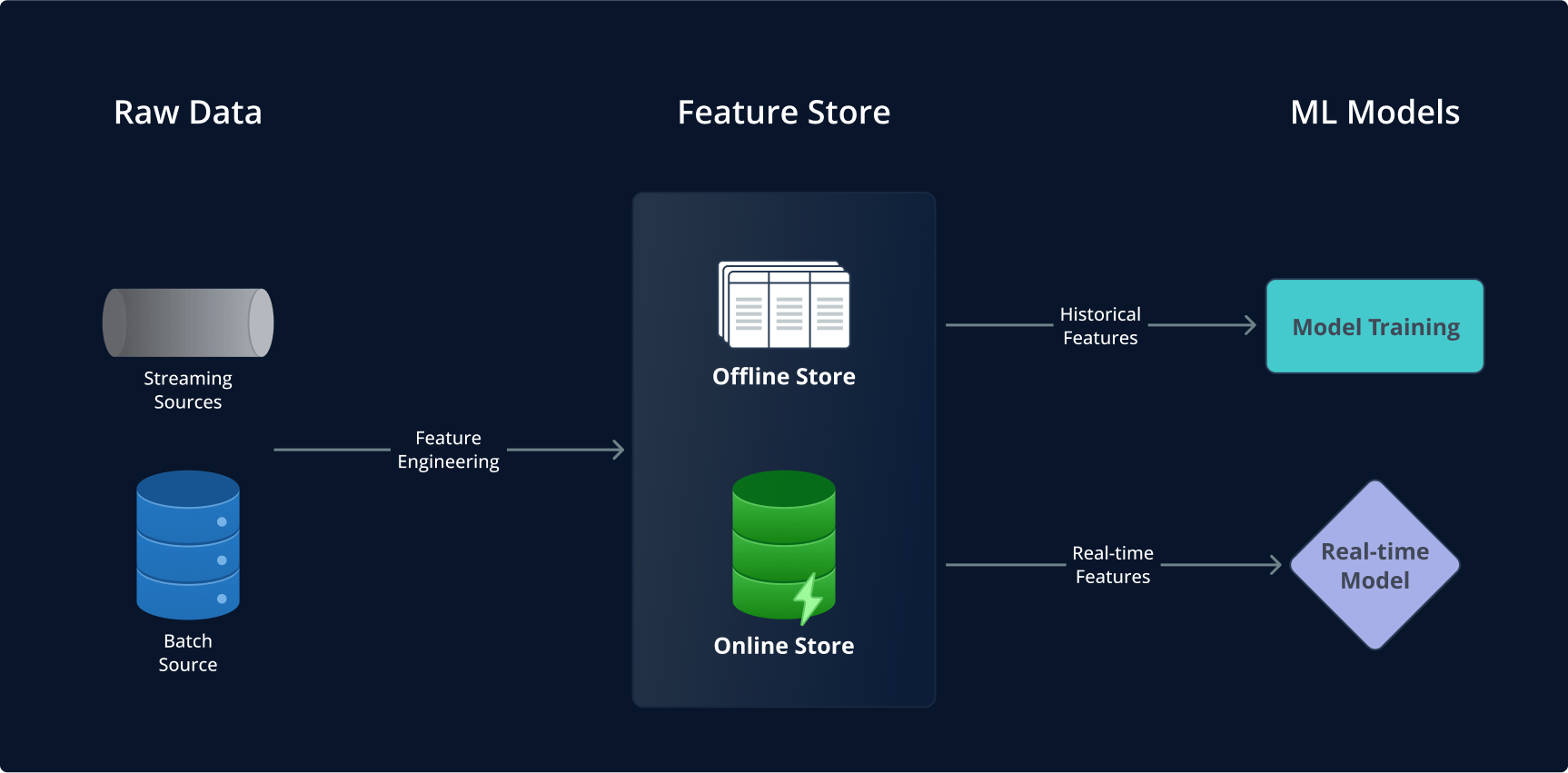
Offline Feature Stores sind das Rückgrat für Training und Batch-Vorhersagen. Sie dienen als Repositories für historische Feature-Daten und sind entscheidend für das Trainieren von Machine-Learning-Modellen mit umfassenden, zeitlich sequenzierten Informationen. Diese historische Perspektive ist essentiell für Modelle, die über längere Zeiträume hinweg Trends und Muster analysieren müssen.
Online Feature Stores hingegen sind auf Geschwindigkeit und Reaktionsfähigkeit ausgelegt. Sie unterstützen Echtzeit-Vorhersagen mit geringer Latenz für produktive Modelle. Dies ist besonders kritisch in Szenarien, in denen Entscheidungen sofort auf Basis der aktuellsten Daten getroffen werden müssen – etwa in Betrugserkennungssystemen oder bei Echtzeit-Personalisierungen auf digitalen Plattformen.
Die doppelte Ausrichtung von Feature Stores – mit sowohl Offline- als auch Online-Funktionalitäten – macht sie zu einer umfassenden Lösung für Machine-Learning-Modelle. Sie stellen sicher, dass Modelle nicht nur mit reichhaltigen historischen Daten trainiert werden, sondern auch schnell und präzise in Echtzeit reagieren können.
Diese Zweiteilung in der Architektur von Feature Stores unterstreicht ihre Vielseitigkeit und zentrale Rolle in modernen Machine-Learning-Infrastrukturen, da sie die Lücke zwischen Datenvorbereitung und realer Anwendung überbrücken.
Die 5 Komponenten eines Feature Stores
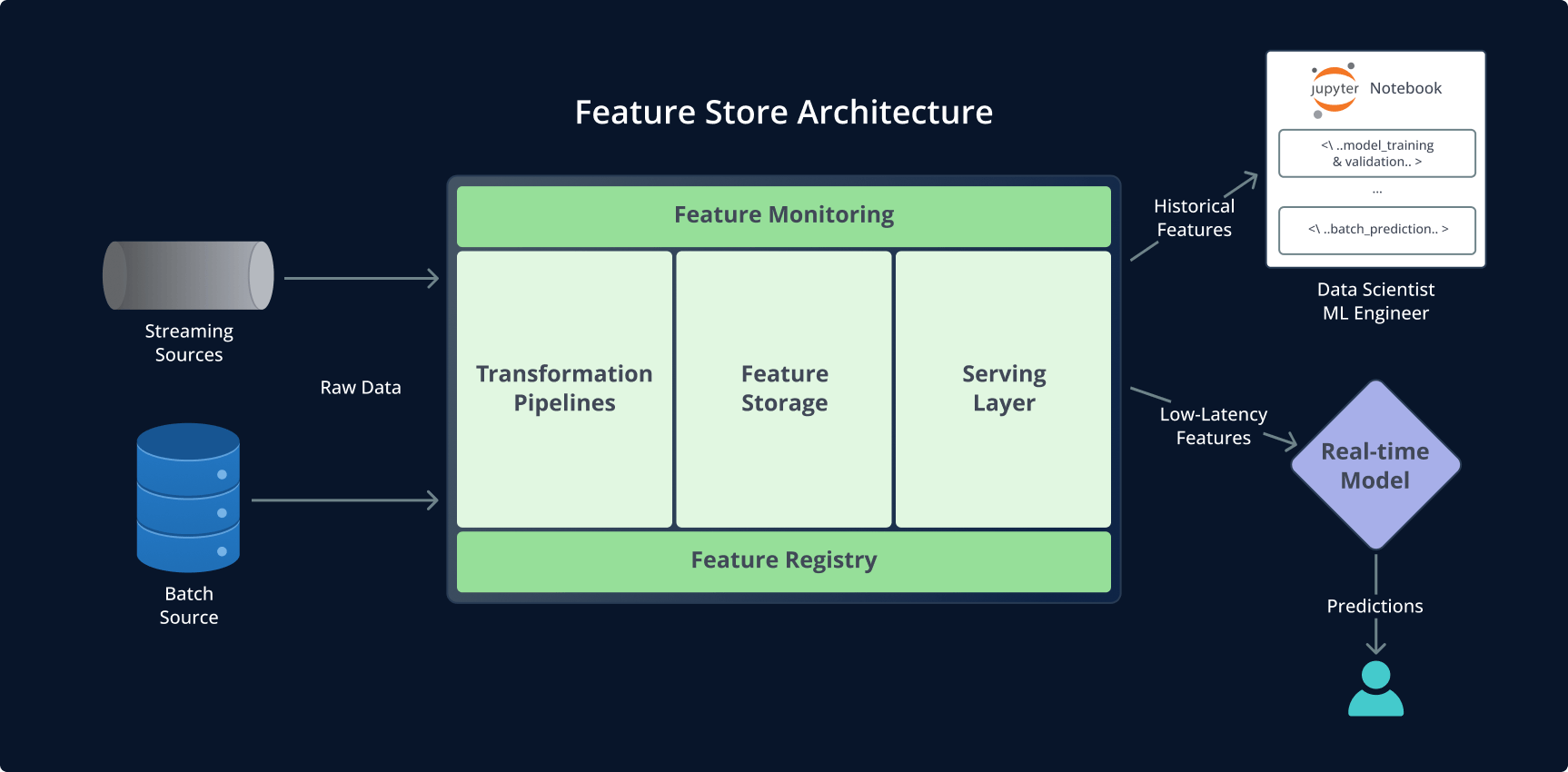
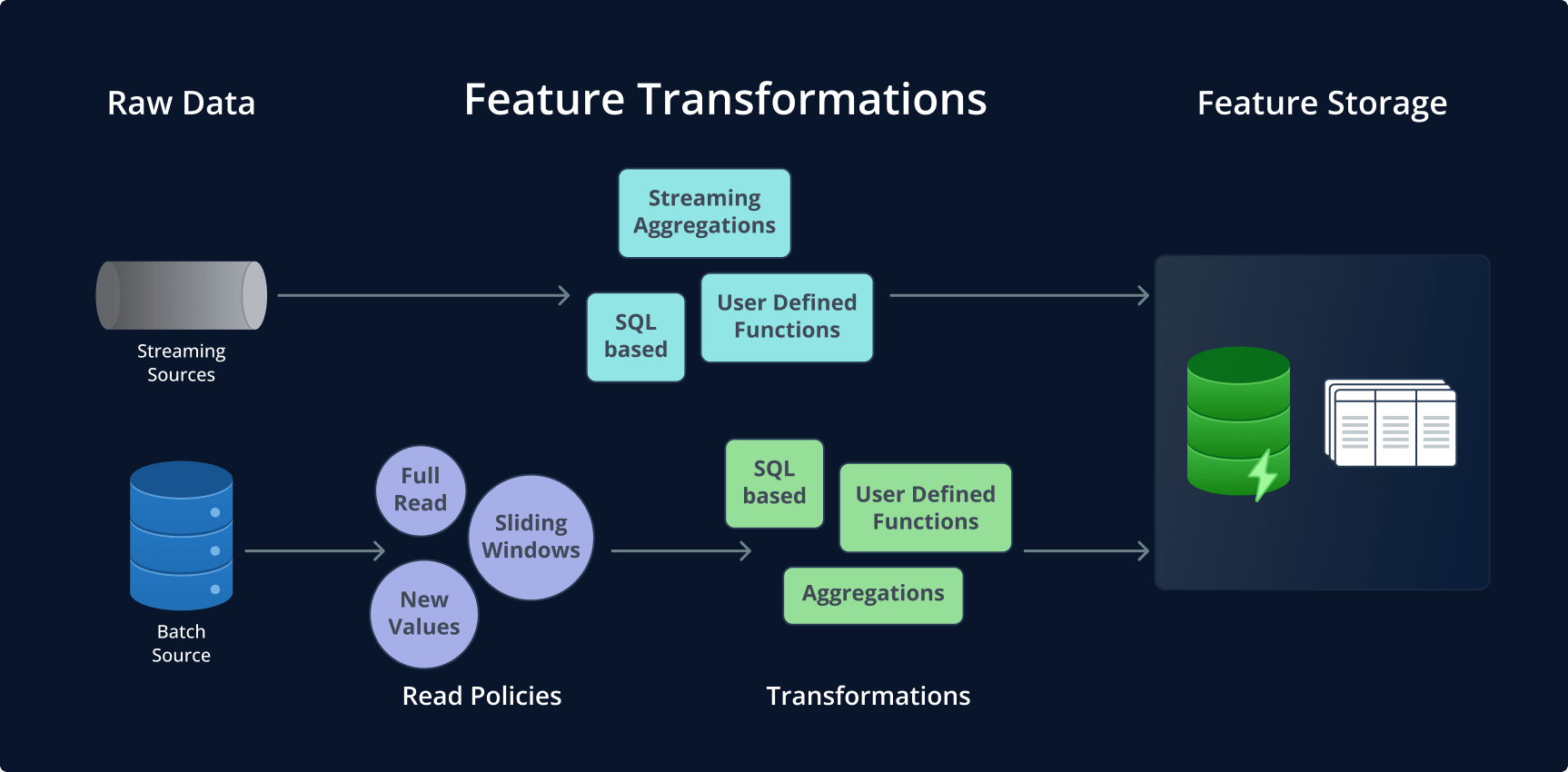
1. Feature Engineering (Transformationen)
Im Zusammenhang mit Feature Stores beschreiben Feature-Transformationen den Weg von der Datenaufnahme bis zur gewünschten Struktur für das ML-Training oder die Inferenz. Es gibt keine universelle Lösung für diese Transformationen – hauptsächlich aufgrund der Vielfalt an Datenquellen und der kreativen Herangehensweise beim Übergang von Rohdaten zu ML-Modellen.
Als allgemeine Richtlinie sollten Feature-Transformationen die Automatisierung und Standardisierung von Datenpipelines unterstützen und gleichzeitig die Flexibilität bieten, Rohdaten auszuwählen, zu filtern, zu aggregieren und zu verarbeiten, um wiederverwendbare Features für ML-Modelle zu generieren.
Es gibt verschiedene Transformationstypen, wobei SQL-basierte Transformationen häufig verwendet werden – insbesondere in schema-basierten Feature Stores. Alternativ können benutzerdefinierte Funktionen in Python verwendet werden, um Aggregationen und komplexere Berechnungen, wie statistische Funktionen, zu definieren.
Unterschiedliche Datenquellen stellen unterschiedliche Anforderungen. Streaming-Quellen beinhalten kontinuierliche Datenaufnahme und -verarbeitung, während Batch-Quellen mit eher statischen Daten arbeiten, die regelmäßig oder bei Bedarf aufgenommen werden. Manche Quellen verfügen über ein konsistentes Schema (z. B. relationale Datenbanken), andere speichern unstrukturierte Daten (z. B. NoSQL). Die Formate reichen von tabellarisch und abfragbar über einfache CSV-Dateien in einem S3-Bucket bis hin zu Parquet-Dateien hinter einer AWS-Athena-Query-Engine. Diese Vielfalt unterstreicht die Notwendigkeit von Flexibilität beim Aufbau oder der Auswahl einer Feature-Store-Lösung.
Da viele Feature-Store-Architekturen auf die Speicherung von Zeitreihendaten ausgerichtet sind, spielt der zeitliche Aspekt der Datenaufnahme – insbesondere bei Batch-Quellen – eine zentrale Rolle. Das Festlegen von Ingestion-Fenstern in Feature-Sets ermöglicht es, festzulegen, welche Daten für reguläre Ingestion-Jobs relevant sind. Beispielsweise können jede Minute neue Daten eintreffen, während ein Ingestion-Job jede Stunde ausgeführt wird und dabei nur Daten der letzten Stunde berücksichtigt.
Die Komplexität Ihrer Dateninfrastruktur und die Kreativität Ihres Feature Engineerings sind entscheidende Faktoren bei der Auswahl einer Feature-Store-Architektur, die zu den Anforderungen Ihrer Organisation passt.
2. Feature Storage
Eng verknüpft mit den Feature-Transformationen und als logische Fortsetzung nach der Datenverarbeitung dient die Feature-Speicherschicht als Dual-Datenbanksystem. Einerseits werden historische Daten mit Fokus auf spaltenbasierter Abfrage gespeichert, andererseits ermöglicht ein zeilenbasiertes System schnelle Abfragen mit geringer Latenz.
Der Feature Storage enthält ausschließlich vorkalkulierte Werte, die aus der Datenaufnahme und den Transformationen resultieren – gemäß der im Feature Registry hinterlegten Logik und Definitionen. Die Speicherschicht besteht aus zwei Typen: Offline Store und Online Store.
Der Offline Store ist von Natur aus statischer. Da Daten häufig zeitlich organisiert sind, werden sie ergänzt, aber nicht überschrieben. Das bedeutet, dass der Offline Store theoretisch alle verarbeiteten Daten enthält und damit Teil der Feature-Historie ist. Architektonisch muss er kosteneffizient für große Datenmengen ausgelegt und gut partitioniert bzw. geshardet sein.
Der Online Store hingegen speichert nur die aktuellsten Feature-Vektoren einer bestimmten Entität. Zum Beispiel wird für einen Nutzer einer Online-Plattform – identifiziert über eine ID – im Online Store nur dessen letzter Besuch gespeichert. Beim Lookup für ein Modell, das vorhersagt, ob 2FA erforderlich ist, ist nur dieser letzte Besuch relevant.
Der Zugriff auf den Feature Storage erfolgt in der Regel über eine API oder ein SDK über die Serving-Schicht – im Gegensatz zum direkten Datenbankzugriff, wie er bei traditionellen Datenspeichern üblich ist.
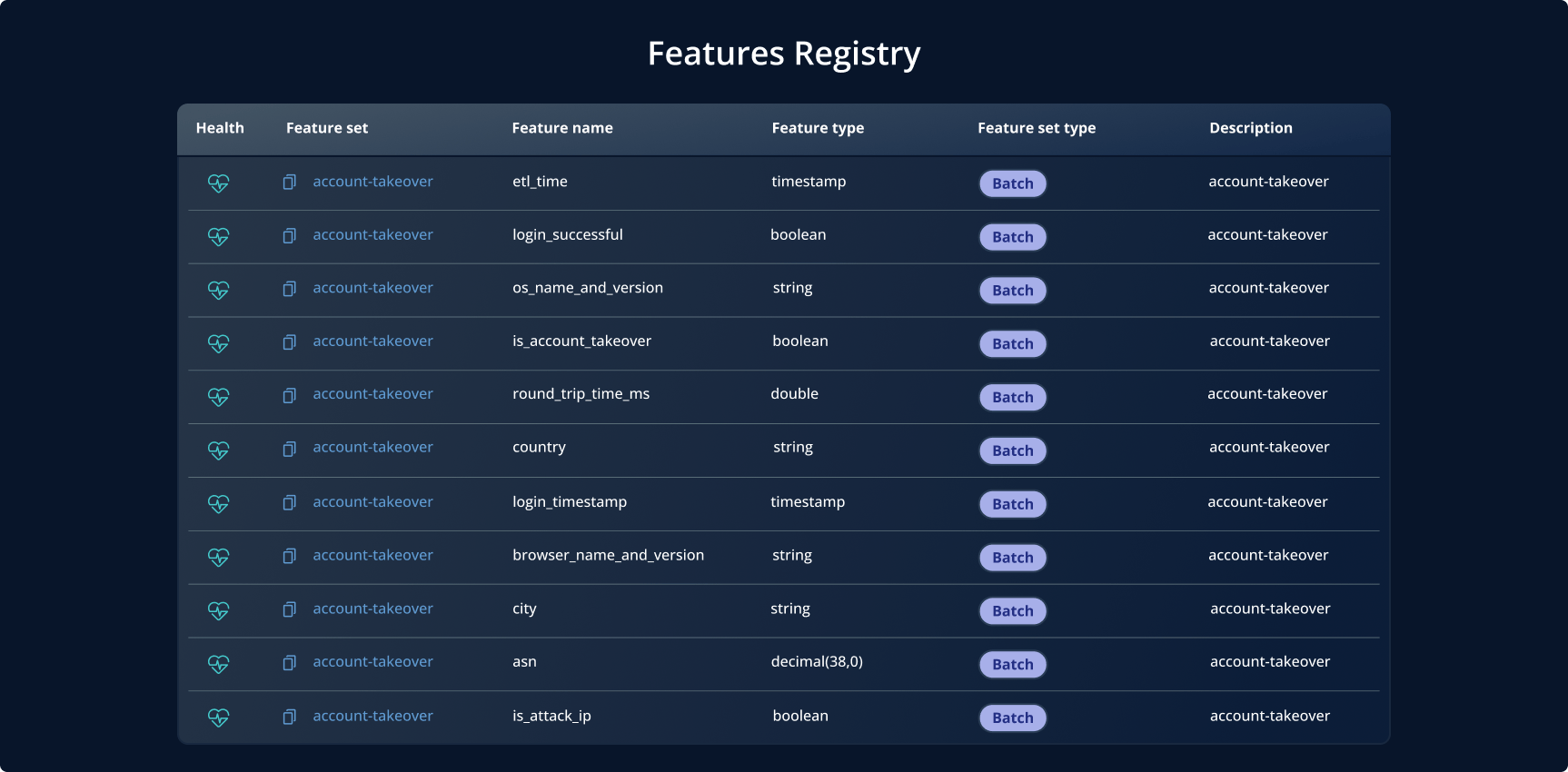
3. Feature Registry
Diese Komponente fungiert als zentrales Repository für alle Features im Feature Store. Die Feature Registry speichert umfangreiche Metadaten und stellt damit die Konsistenz der Feature-Definitionen sicher. Dazu gehören Informationen über die Herkunft der Rohdaten (Ingestion), die Daten-Transformationen, das Format sowie die Art und Weise, wie die Features in Modellen genutzt werden.
Eine weitere zentrale Funktion der Feature Registry ist die Verwaltung von Zugriffskontrollen. Sie speichert Informationen darüber, wer auf ein Feature-Set zugreifen darf und welche Rechte vergeben wurden.
Neben der Metadatenverwaltung ist die Feature Registry eine allgegenwärtige, jedoch oft unsichtbare Komponente des Feature Stores. Sie verbindet alle weiteren Komponenten und bildet die Grundlage der Feature-Linie.
In manchen Feature-Store-Lösungen ist die Feature Registry das Rückgrat des Systems. In anderen dient sie als Mittel zur Speicherung von Metadaten, die Datenquellen mit Transformationen, Ingestion-Logik und Feature-Formaten verknüpfen. Die konkrete Rolle kann variieren, aber eine Form von Registry ist in nahezu allen Feature Stores vorhanden.
4. Feature Serving
Feature Serving ermöglicht es Data Scientists und ML Engineers, mit dem Feature Storage zu interagieren – etwa um historische Features für das Training oder aktuelle Feature-Vektoren für eine bestimmte Entität abzurufen. Manche Feature Stores unterstützen auch On-the-Fly-Features – also Features, die bei Anfrage berechnet statt vorab gespeichert werden.
Im Gegensatz zu klassischen Datenbank-Clients, die komplexe Abfragen und Verwaltungsoperationen ermöglichen, basiert der Feature-Serving-Client auf einer API oder einem SDK mit klar definiertem Anwendungszweck. In der Regel dient er dazu, ausgewählte Features zwischen zwei Zeitpunkten oder für eine oder mehrere Entitäten abzurufen.
Auch wenn bestimmte Feature Stores auf spezielle Operationstypen ausgelegt sind und unterschiedliche Fähigkeiten beim Serving besitzen, bleiben die hier beschriebenen Grundprinzipien weitgehend konsistent über die gängigsten Feature-Store-Typen hinweg.
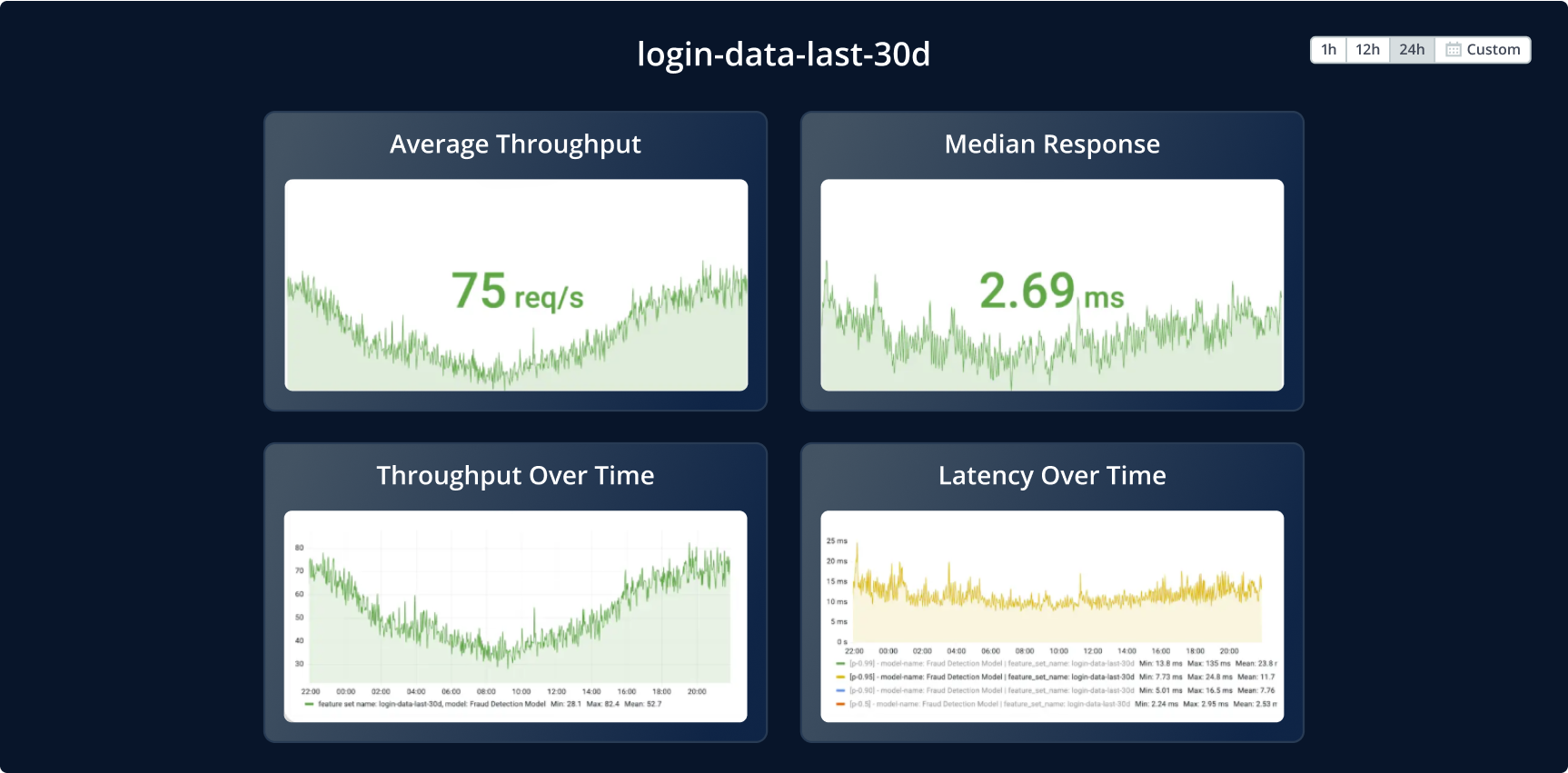
5. Feature Monitoring
In jedem produktiven ML-System ist Monitoring entscheidend für die Sicherstellung gleichbleibender Qualität. Im Kontext von Feature Stores hilft Monitoring dabei, Änderungen in der Datenqualität zu erkennen, Concept Drift zu identifizieren, Training-Serving-Skew zu bewerten und – bei Echtzeit-Features – sicherzustellen, dass die Latenzanforderungen erfüllt werden. Im Einzelnen:
- Datenqualität: Überwachung von Anomalien wie Nullwert-Anteilen, Datumsformaten oder unerwarteten Werten. Feature-Store-Lösungen bieten in der Regel Alerts oder Dashboards zur Visualisierung solcher Ereignisse und Muster.
- Data Drift / Concept Drift: Überwachung statistischer Verteilungen der Daten über die Zeit hinweg und Benachrichtigung bei signifikanten Abweichungen zum letzten definierten Zustand. Metriken wie KL-Divergenz oder PSI helfen bei der Mustererkennung.
- Serving-Performance: Die Serving-Schicht (oft als Backend-Anwendung) wird hinsichtlich Durchsatz, Antwortzeiten und Anfragen pro Sekunde überwacht.
- Training-Serving-Skew: Es können Prüfungen implementiert werden, um die Konsistenz zwischen Trainingsbedingungen und Live-Serving zu gewährleisten. Diese Checks stellen sicher, dass Modelle unter realen Bedingungen wie im Training performen.
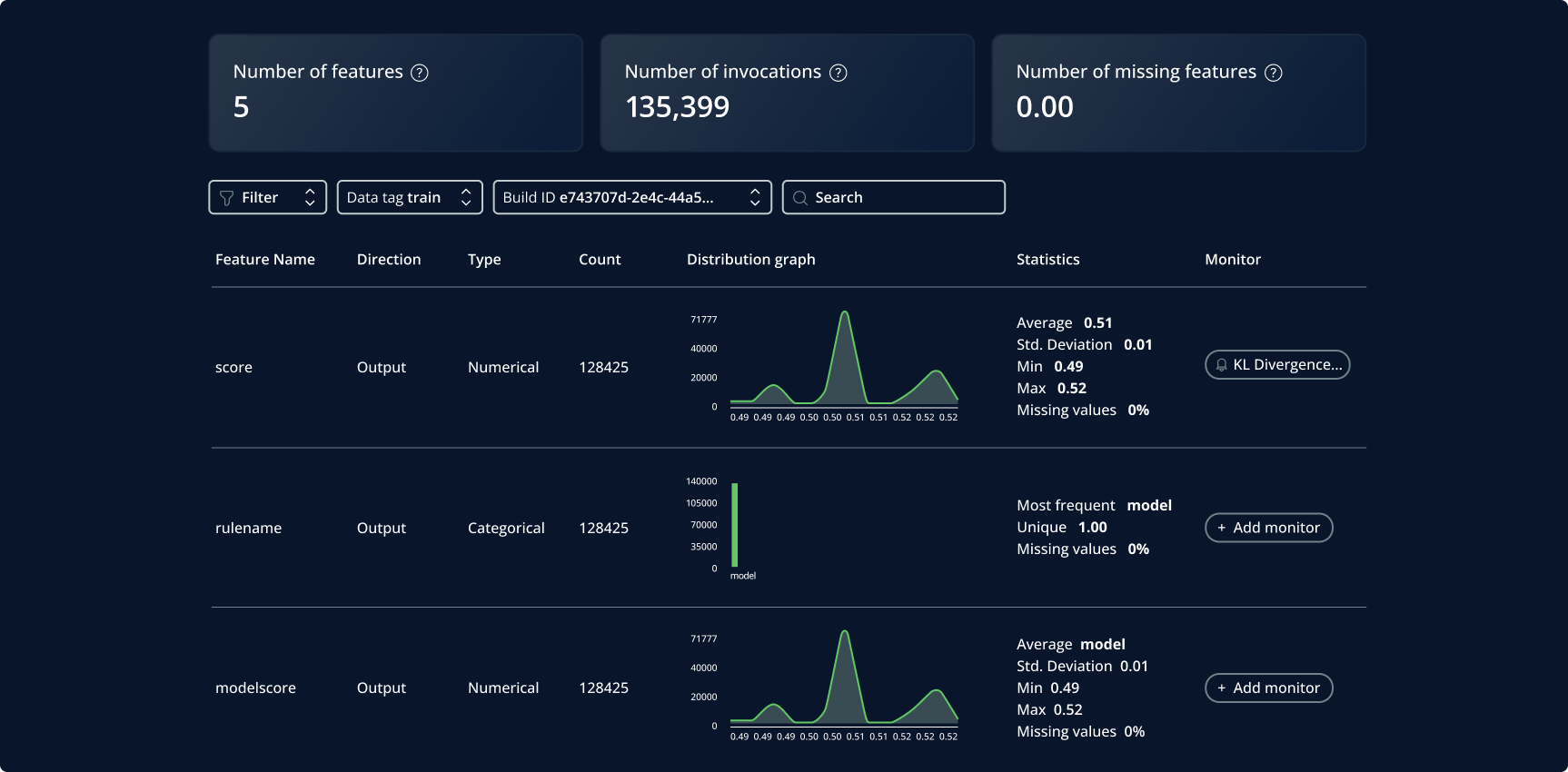
Ein Beispiel für einen Feature Store
In einem detaillierten ML-Modell mit Fokus auf Personalisierung im E-Commerce steigert die Einführung eines Feature Stores die Leistungsfähigkeit des Modells erheblich. Stellen Sie sich vor, ein Nutzer sucht auf einer E-Commerce-Plattform nach Produkten. Die Suchanfrage – in der Regel bestehend aus Text sowie Nutzer- oder Sitzungs-ID – enthält nur begrenzte Informationen. An dieser Stelle kommt der Feature Store ins Spiel, indem er mithilfe dieser Kennungen auf eine Vielzahl vorverarbeiteter Features zugreift.
Hier zeigt der Feature Store seine wahre Stärke: Er verwandelt die einfache Suchanfrage in einen reichhaltigen Datensatz. Er zieht detaillierte Nutzungsverläufe wie frühere Käufe und angesehene Artikel heran und kombiniert diese mit Echtzeitdaten wie angesagten Produkten oder saisonalen Vorlieben. Dieser Anreicherungsprozess verleiht der Suche des Nutzers nicht nur mehr Tiefe, sondern ermöglicht dem ML-Modell auch hochgradig personalisierte Produktempfehlungen. Der Feature Store fungiert als Brücke, die einfache Nutzeranfragen in detaillierte, umsetzbare Einblicke für personalisierte Nutzererlebnisse verwandelt.
Wann Sie einen Feature Store brauchen (und wann nicht)
Wenn Sie überlegen, einen Feature Store in Ihren Machine-Learning-Workflow zu integrieren, sollten Sie dessen Vorteile bei der Verwaltung einer großen Anzahl von Features über verschiedene Modelle hinweg berücksichtigen – insbesondere in komplexen, kollaborativen Umgebungen. Der Mehrwert eines Feature Stores ist besonders hoch, wenn dieselben Features in mehreren Modellen verwendet werden. Ein zentrales, konsistentes Repository reduziert Redundanz und Engineering-Aufwand. Ein Feature Store ist unverzichtbar in Szenarien, in denen eine Vielzahl an Features über mehrere Modelle hinweg verwaltet werden muss. Seine Bedeutung wächst in komplexen, teamübergreifenden Umgebungen, in denen konsistente, hochwertige Features für mehrere Teams zugänglich sein müssen.
Für Echtzeitanwendungen wie Betrugserkennung oder dynamische Preisgestaltung ist die Fähigkeit eines Feature Stores, aktuelle Features schnell bereitzustellen, entscheidend. Er sorgt dafür, dass Modelle für Live-Entscheidungen stets mit den relevantesten und aktuellsten Daten versorgt werden – was ihre Effektivität direkt beeinflusst.
Auf der anderen Seite kann sich die Investition in einen Feature Store bei kleineren Projekten oder in frühen Phasen von Machine-Learning-Initiativen, in denen Komplexität und Wiederverwendbarkeit gering sind, möglicherweise nicht lohnen. Auch wenn Ihre ML-Anwendungen hauptsächlich auf Batch-Verarbeitung beruhen und keine Echtzeit-Feature-Aktualisierungen benötigen, sind die Echtzeitfunktionen eines Feature Stores möglicherweise nicht erforderlich.
Letztlich sollte die Entscheidung für einen Feature Store in Einklang mit der Komplexität und Skalierung Ihrer ML-Operationen, der Natur Ihrer Projekte (Echtzeit vs. Batch) und den verfügbaren Ressourcen für Implementierung und Wartung getroffen werden.
Die Abwägung dieser Faktoren – Feature-Wiederverwendbarkeit, Echtzeitbedarf und ML-Skalierung – im Verhältnis zum Aufwand für Implementierung und Betrieb eines Feature Stores ist entscheidend. So stellen Sie sicher, dass seine Einführung zu den Anforderungen Ihres Projekts und Ihrer ML-Strategie passt.
Vorteile vs. Nachteile eines Feature Stores
Nachfolgend finden Sie eine zusammengefasste Tabelle mit den Vorteilen von Feature Stores im Bereich Machine Learning und KI:
| Vorteile | Nachteile |
| Wiederverwendbarkeit von Features: Reduziert Duplikation und Rechenkosten, da Teams Features gemeinsam nutzen können. | Komplexe Implementierung: Einrichtung und Wartung können aufwendig sein. |
| Standardisierte Feature-Definitionen: Sorgt für einheitliche, dokumentierte Features über Teams hinweg. | Hohe Anfangsinvestition: Erfordert viel Zeit und Ressourcen beim Start. |
| Konsistenz zwischen Training und Serving: Einheitliche Feature-Logik für Training und Echtzeitvorhersagen, weniger Skew. | Overhead bei kleinen Projekten: Für einfache oder kleine Projekte oft überdimensioniert. |
| Zentrale Verwaltung: Eine „Single Source of Truth“ für Features verbessert Zusammenarbeit und Effizienz. | Wartungsaufwand: Kontinuierliche Pflege bei sich ändernden Daten und Anforderungen notwendig. |
| Echtzeit-Features: Unterstützt Feature-Abrufe mit geringer Latenz für Echtzeitanwendungen. | Integrationsaufwand: Anbindung an bestehende Infrastruktur kann komplex sein. |
| Governance und Compliance: Unterstützt kontrollierten Zugriff und Einhaltung von Datenschutzrichtlinien. | Performance-Engpässe: Risiko von Leistungsproblemen bei großen Workloads, wenn nicht richtig optimiert. |
Der Einstieg in Feature Stores
Der Einstieg in Feature Stores erfordert eine strategische Entscheidung: Selbst entwickeln, eine spezialisierte Lösung (Managed Solution) kaufen oder eine Open-Source-Option nutzen. Die Eigenentwicklung ermöglicht maximale Anpassung, benötigt aber erhebliche Ressourcen und Expertise. Vorgefertigte Lösungen von Anbietern wie JFrog ML, AWS SageMaker oder Google Cloud Vertex bieten einsatzbereite, skalierbare Plattformen mit weniger Betriebsaufwand. Open-Source-Alternativen wie Feast oder Hopsworks bieten Flexibilität und Community-Support. Jede Option hat ihre Vor- und Nachteile in Bezug auf Kosten, Kontrolle und Integration – daher ist es wichtig, die Fähigkeiten Ihres Teams, Ihre Projektanforderungen und Ihre langfristigen Ziele zu berücksichtigen.
Fazit
Zusammenfassend zeigt unsere Betrachtung von „Was ist ein Feature Store“ im Machine Learning seine unverzichtbare Rolle in modernen Data-Science-Workflows auf. Feature Stores sind nicht nur hilfreich, sondern essentiell für Organisationen, die ihre ML-Aktivitäten effizient skalieren wollen. Sie lösen reale Herausforderungen, indem sie Datensilos aufbrechen, die Time-to-Market für ML-Modelle verkürzen, Datenqualität sichern und Konsistenz über verschiedene ML-Anwendungen hinweg gewährleisten.
JFrog DataOps ist als zentrale Lösung für das Feature Management konzipiert – mit sofort einsatzfähigen Funktionen für Datenaufnahme, Transformation, Speicherung und Monitoring. Es ist nicht nur ein Tool, sondern eine umfassende Plattform, die sich nahtlos in bestehende MLOps-Pipelines integriert und sowohl Produktivität als auch Performance steigert.
Mit der weiteren Reifung von Machine Learning werden Feature Stores so selbstverständlich werden wie Data Lakes und Data Warehouses.
Erfahren Sie mehr über JFrog ML bei einer Online-Tour oder bei einer persönlicher Demo.
See what JFrog & GitHub can do together



