

Silos aufbrechen: DevOps und MLOps zu einer einheitlichen Software Supply Chain vereinen – Teil 1
Von getrennten Pipelines hin zu einer vereinheitlichten Software Supply Chain

Von
10 min read

Als Unternehmen das Potenzial von Künstlicher Intelligenz (KI) erkannten, begann ein Wettlauf, um Machine Learning Operations (MLOps) in ihre Geschäftsstrategien zu integrieren. Doch die Implementierung von Machine Learning (ML) in der Praxis stellte sich als äußerst anspruchsvoll heraus – die große Kluft zwischen Entwicklung und produktivem Einsatz wurde schnell deutlich. Laut Gartner schaffen es 85 % aller KI- und ML-Projekte nicht bis zur Produktion.
In dieser Blogserie beleuchten wir, warum es entscheidend ist, bewährte DevOps-Praktiken mit MLOps zu verschmelzen. Ziel ist es, die Lücke zwischen klassischer Softwareentwicklung und Machine Learning zu schließen – für einen nachhaltigen Wettbewerbsvorteil und fundiertere, datengestützte Entscheidungen. Teil 1 befasst sich mit den Herausforderungen getrennter DevOps- und MLOps-Pipelines und zeigt auf, warum eine Integration notwendig ist. Unser Ziel in diesem ersten von drei Beiträgen ist es, Ihnen klarzumachen, was auf dem Spiel steht, wenn Sie weiter am Status quo festhalten.
Herausforderungen durch getrennte Pipelines
Traditionell arbeiten DevOps- und MLOps-Teams mit getrennten Workflows, Tools und Zielsetzungen. Diese Trennung führt jedoch zu zahlreichen Ineffizienzen und Redundanzen, die die Softwarebereitstellung negativ beeinflussen.
1. Ineffiziente Integration der Workflows
DevOps-Pipelines sind darauf ausgelegt, den Software-Entwicklungszyklus (SDLC) zu optimieren – mit Fokus auf Continuous Integration, Continuous Delivery (CI/CD) und zuverlässigen Betrieb. Zwar gibt es Überschneidungen zwischen klassischer Softwareentwicklung und ML-Modellentwicklung, doch MLOps-Pipelines bringen eigene, spezifische Phasen mit sich: Datenaufbereitung, Modelltraining, Experimentphase und Deployment – oft unter Einsatz spezialisierter Tools und Prozesse.
Diese Trennung führt zu Engpässen, sobald Machine-Learning-Modelle in klassische Softwareanwendungen integriert werden sollen.
Ein typisches Beispiel: Data Scientists arbeiten in Jupyter Notebooks, während Software Engineers auf CI/CD-Tools wie Jenkins oder GitLab CI setzen. Die Integration von ML-Modellen in Anwendungen erfolgt dann meist manuell – ein fehleranfälliger und aufwendiger Prozess. Modelle müssen konvertiert, validiert und so bereitgestellt werden, dass sie mit bestehenden DevOps-Workflows kompatibel sind.
Die Folge: Verzögerungen, mangelnde Standardisierung und ein erhöhtes Risiko für Fehler – die Innovationsgeschwindigkeit leidet.
2. Redundanzen bei Tools und Ressourcen
Sowohl DevOps als auch MLOps verfolgen ähnliche Ziele: Automatisierung, Versionierung und Deployment. Doch anstatt auf gemeinsame Lösungen zu setzen, verwenden beide Bereiche oft separate Tools und Prozesse.
DevOps-Teams nutzen in der Regel Technologien wie Docker, Kubernetes oder Terraform. Im Gegensatz dazu setzen MLOps-Teams auf ML-spezifische Werkzeuge wie MLflow, Kubeflow oder TensorFlow Serving. Diese Fragmentierung anstatt der Nutzung einheitlicher Tools führt dazu, dass beide Seiten doppelte Arbeit leisten, um letztlich identische Ziele zu erreichen.
Beispielsweise wird in DevOps die Versionierung typischerweise über Git umgesetzt, während MLOps zusätzlich spezielle Versionierungssysteme für Datensätze und Modelle nutzt. Dadurch entsteht ein erheblicher Mehraufwand in Infrastruktur, Verwaltung und Kosten – denn es müssen zwei getrennte Systeme gepflegt werden, obwohl sie funktional denselben Zwecken dienen: Versionskontrolle, Reproduzierbarkeit und Nachverfolgbarkeit.
3. Fehlende Synergien zwischen den Teams
Die fehlende Integration von DevOps- und MLOps-Pipelines führt zu Silos zwischen Engineering, Data Science und Operations. Diese isolierten Arbeitsweisen beeinträchtigen die Kommunikation, führen zu Zielkonflikten und verzögern Deployments.
Data Scientists haben oft Schwierigkeiten, ihre Modelle für die Produktion bereitzustellen – nicht wegen technischer Hürden, sondern aufgrund mangelnder Abstimmung mit den DevOps- und Softwareentwicklungs-Teams. Die Folge: fehlende Standardisierung, Inkonsistenzen im Entwicklungsprozess und geringe Wiederverwendbarkeit.
Zudem werden ML-Modelle häufig nicht wie klassische Software-Artefakte behandelt. Sie durchlaufen dann nicht die etablierten Sicherheits-, Test- und Qualitätsprüfungen, die in DevOps-Prozessen Standard sind. Das kann zu erheblichen Qualitätsproblemen führen – von unerwartetem Verhalten im Live-Betrieb bis hin zu einem Vertrauensverlust zwischen den Teams.
4. Herausforderungen beim Deployment und verlangsamte Iterationszyklen
Die Trennung von DevOps und MLOps hat direkte Auswirkungen auf die Geschwindigkeit und Flexibilität von Deployments. In klassischen DevOps-Umgebungen sorgt CI/CD für regelmäßige und zuverlässige Software-Updates. Beim Machine Learning hingegen erfordert ein Modell-Update oft eine erneute Trainingsphase, eine gründliche Validierung und gelegentlich sogar eine Anpassung der Architektur für die Integration.
Diese Diskrepanz führt zu verlangsamten Iterationszyklen, da beide Pipelines unabhängig voneinander arbeiten – mit jeweils eigenen Validierungs- und Freigabeprozessen.
Ein typisches Szenario: Das Engineering-Team ist bereit, ein neues Feature zu veröffentlichen. Doch wenn dafür ein aktualisiertes ML-Modell erforderlich ist, verzögert sich das Release – weil das Modell zunächst neu trainiert und getestet werden muss. Solche Abhängigkeiten sorgen für lange Markteinführungszeiten bei Funktionen, die auf Machine Learning basieren.
5. Schwierigkeiten bei Konsistenz und Nachverfolgbarkeit
Getrennte DevOps- und MLOps-Konfigurationen erschweren eine einheitliche Versionierung, Auditierung und Nachverfolgbarkeit im gesamten Softwaresystem. In DevOps-Pipelines sind Codeänderungen typischerweise gut dokumentiert, versioniert und auditierbar. In der MLOps-Welt kommen jedoch zusätzliche Dimensionen hinzu: Trainingsdaten, Hyperparameter, Modellversionen und Experimente. Diese Informationen werden häufig in separaten Systemen mit unterschiedlichen Logging-Mechanismen gespeichert.
Das Fehlen einer durchgängigen Nachverfolgbarkeit erschwert das Troubleshooting erheblich. Wenn ein Modell in der Produktion unerwartet reagiert, kann es äußerst aufwendig sein herauszufinden, ob das Problem im Trainingsdatensatz, in der Modellversion oder im Anwendungscode liegt – besonders dann, wenn es keine einheitliche Pipeline und keinen gemeinsamen Kontext gibt.
Getrennte ML und DevOps Pipelines
Argumente für die Integration: Warum DevOps und MLOps zusammenführen?
Wie gezeigt, führen isolierte DevOps- und MLOps-Pipelines zu Ineffizienzen, Redundanzen und einem Mangel an Zusammenarbeit zwischen Teams. Das Ergebnis sind langsamere Releases, inkonsistente Prozesse und eingeschränkte Innovationsfähigkeit.
Die Integration beider Pipelines zu einer einheitlichen Software Supply Chain ist der Schlüssel, um diese Herausforderungen zu überwinden. Sie schafft Konsistenz, vermeidet doppelte Arbeit und fördert die teamübergreifende Zusammenarbeit – von der Entwicklung bis zum produktiven Einsatz.
Gemeinsame Zielsetzungen von DevOps und MLOps
Auch wenn sich ihre Schwerpunkte unterscheiden – DevOps konzentriert sich auf die klassische Softwareentwicklung, während MLOps auf Machine-Learning-Workflows ausgerichtet ist – stimmen ihre Kernziele in den folgenden Punkten überein:
- Schnelle Auslieferung
Sowohl DevOps als auch MLOps verfolgen das Ziel, durch häufige, iterative Releases die Markteinführungszeit zu verkürzen. DevOps erreicht dies durch kontinuierliche Integration und Auslieferung von Codeänderungen, während MLOps den Zyklus von Modellentwicklung, Training und Deployment beschleunigen will.
Schnelle Auslieferung in DevOps stellt sicher, dass neue Softwarefunktionen so schnell wie möglich bereitgestellt werden. Ebenso ermöglicht MLOps mit der Bereitstellung aktualisierter Modelle mit verbesserter Genauigkeit oder verbessertem Verhalten eine schnelle Reaktion auf Veränderungen in den Daten oder Geschäftsanforderungen. - Automatisierung
Automatisierung ist zentral für beide Ansätze, da sie manuelle Eingriffe reduziert und das Risiko menschlicher Fehler minimiert. DevOps automatisiert das Testen, Erstellen und Ausliefern von Software, um Konsistenz, Effizienz und Zuverlässigkeit sicherzustellen.
In MLOps ist Automatisierung ebenso entscheidend. Die Automatisierung von Datenaufnahme, Modelltraining, Hyperparameter-Tuning und Deployment erlaubt es Data Scientists, sich stärker auf Experimente und die Verbesserung der Modellleistung zu konzentrieren, anstatt repetitive Aufgaben zu erledigen. Zudem sorgt Automatisierung in MLOps für Reproduzierbarkeit – ein entscheidender Faktor für das Management von ML-Modellen in produktiven Umgebungen. - Reliability
Sowohl DevOps als auch MLOps legen Wert auf Zuverlässigkeit in produktiven Umgebungen. DevOps setzt auf Praktiken wie automatisiertes Testen, Monitoring und Infrastruktur als Code, um die Stabilität der Software zu gewährleisten und Ausfallzeiten zu minimieren.
MLOps zielt darauf ab, die Zuverlässigkeit eingesetzter Modelle zu gewährleisten, damit diese auch unter sich verändernden Bedingungen erwartungsgemäß funktionieren. Praktiken wie Modellmonitoring, automatisiertes Retraining und Drifterkennung sind Bestandteil von MLOps, um die Robustheit und Zuverlässigkeit des ML-Systems langfristig sicherzustellen.
Behandlung von ML-Modellen als Artefakte in der Software-Lieferkette
Im traditionellen DevOps ist das Konzept, sämtliche Softwarekomponenten – wie Binärdateien, Bibliotheken und Konfigurationsdateien – als Artefakte zu behandeln, fest etabliert. Diese Artefakte werden versioniert, getestet und durch verschiedene Umgebungen (z. B. Staging, Produktion) promotet – als Teil einer integrierten Software Supply Chain. Wird dieser Ansatz auch auf ML-Modelle angewendet, lassen sich Workflows erheblich vereinfachen und die bereichsübergreifende Zusammenarbeit verbessern. Hier sind vier zentrale Vorteile der Behandlung von ML-Modellen als Artefakte:
1. Einheitliche Sicht auf alle Artefakte
Wenn ML-Modelle als Artefakte behandelt werden, werden sie in dieselben Systeme integriert, die auch für andere Softwarekomponenten verwendet werden – etwa Artefakt-Repositories und CI/CD-Pipelines. So können Modelle auf dieselbe Weise versioniert, nachverfolgt und verwaltet werden wie Code, Binärdateien und Konfigurationen.
Eine einheitliche Sicht auf alle Artefakte schafft Konsistenz, verbessert die Nachverfolgbarkeit und erleichtert die Kontrolle über die gesamte Software-Lieferkette.
Ein Beispiel: Werden Modelle gemeinsam mit dem zugehörigen Code versioniert, ist bei jedem neuen Release klar dokumentiert, welche Modellversion verwendet wurde. Das reduziert Verwirrung, verhindert Missverständnisse und stellt sicher, dass Teams genau wissen, welche Code- und Modellversionen reibungslos zusammenarbeiten.
2. Vereinfachte Workflow-Automatisierung
Die Integration von ML-Modellen in die übergeordnete Software-Lieferkette stellt sicher, dass die Automatisierungsvorteile aus DevOps auch auf MLOps übertragen werden. Durch die Automatisierung von Trainings-, Validierungs- und Deployment-Prozessen können ML-Artefakte – ähnlich wie in CI/CD-Pipelines – eine Reihe automatisierter Schritte durchlaufen, von der Datenvorverarbeitung bis zur finalen Bereitstellung.
Das bedeutet: Wenn Entwickler Codeänderungen pushen, die sich auf ein ML-Modell auswirken, kann dasselbe CI/CD-System automatisch das Retraining, die Validierung und das Deployment des Modells anstoßen. Durch die Nutzung der bestehenden Automatisierungsinfrastruktur erreichen Unternehmen eine durchgängige Auslieferung, die sowohl Softwarekomponenten als auch Modelle umfasst – ganz ohne zusätzliche manuelle Schritte.
3. Bessere Zusammenarbeit zwischen Teams
Ein zentrales Problem bei getrennten DevOps- und MLOps-Pipelines ist der fehlende Zusammenhalt zwischen Data Science, Engineering und DevOps. Die Behandlung von ML-Modellen als Artefakte innerhalb der Software Supply Chain fördert die bereichsübergreifende Zusammenarbeit, indem Prozesse standardisiert und gemeinsame Tools genutzt werden.
Wenn alle Beteiligten dieselbe Infrastruktur verwenden, verbessert sich die Kommunikation – denn es entsteht ein gemeinsames Verständnis darüber, wie Komponenten entwickelt, getestet und ausgeliefert werden.
Beispiel: Data Scientists können sich auf die Entwicklung hochwertiger Modelle konzentrieren, ohne sich um die Feinheiten des Deployments kümmern zu müssen – die integrierte Pipeline übernimmt das Packaging und die Auslieferung des Modellartefakts automatisch. Software Engineers wiederum können das Modell wie jede andere Komponente der Anwendung behandeln – versioniert und getestet wie gewohnt. Dieses gemeinsame Verständnis ermöglicht effizientere Übergaben, reduziert Reibungsverluste zwischen Teams und sorgt für klare Zielausrichtung.
4. Verbesserte Compliance, Sicherheit und Governance
Werden Modelle als reguläre Artefakte in der Software Supply Chain behandelt, können sie denselben Sicherheitsprüfungen, Compliance-Checks und Governance-Richtlinien unterzogen werden wie andere Softwarekomponenten. Die Prinzipien von DevSecOps – also die Integration von Sicherheit in jede Phase des Software-Lifecycles – lassen sich so auch auf ML-Modelle übertragen.
Gerade weil Modelle zunehmend zentral für Geschäftstätigkeiten sind, ist das essentiell: Nur wenn sie auf Schwachstellen geprüft, auf Qualität validiert und im Einklang mit unternehmensweiten Sicherheitsvorgaben bereitgestellt werden, lassen sich Risiken im produktiven Einsatz von KI/ML zuverlässig minimieren.
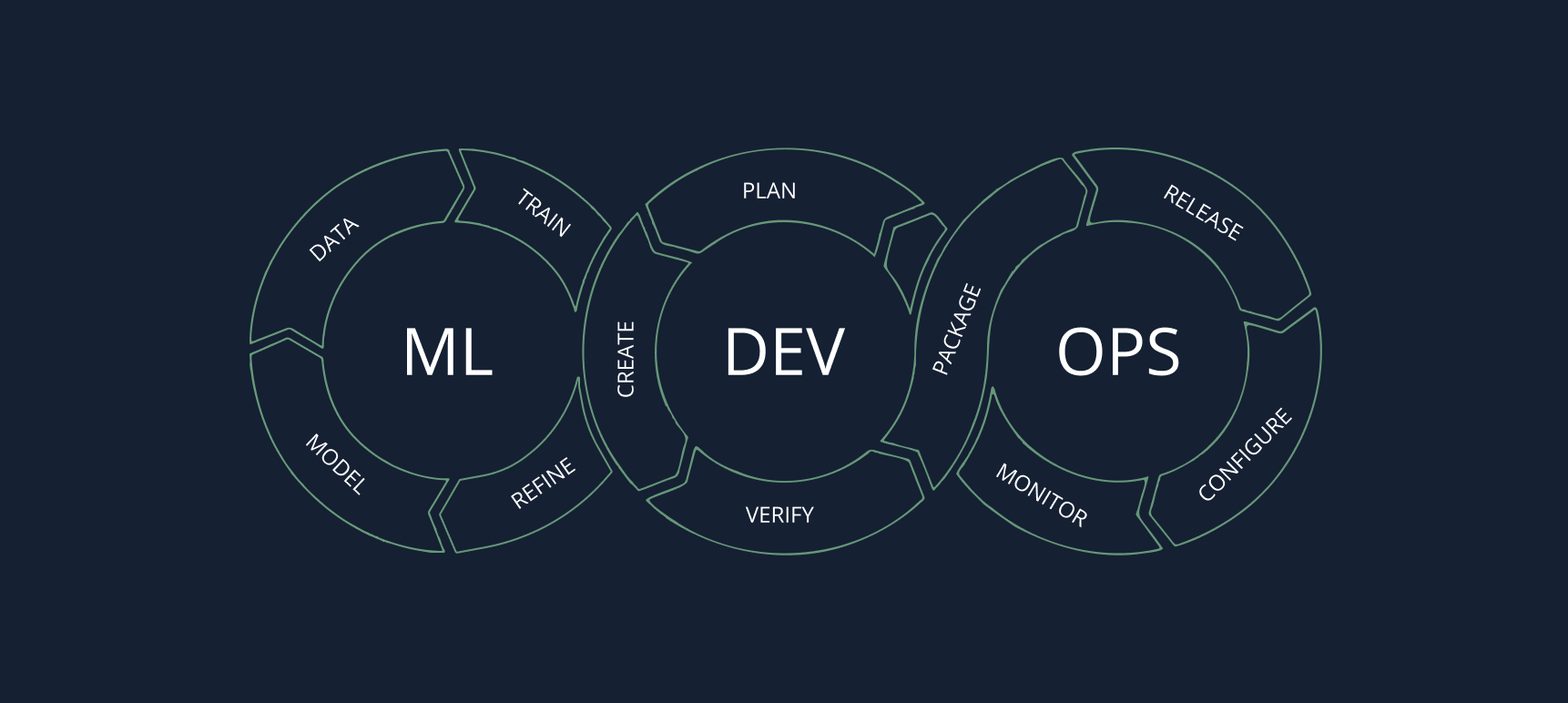
Vereinte ML- und DevOps-Pipeline
Fazit
Die Behandlung von ML-Modellen als Artefakte innerhalb der übergreifenden Software Supply Chain verwandelt den bisherigen Ansatz – getrennte DevOps- und MLOps-Prozesse – in einen einheitlichen, durchgängigen Workflow. Diese Integration optimiert Abläufe durch die Nutzung bestehender CI/CD-Pipelines für alle Artefakte, stärkt die Zusammenarbeit durch standardisierte Prozesse und Infrastruktur und stellt sicher, dass sowohl Code als auch Modelle denselben Anforderungen an Qualität, Zuverlässigkeit und Sicherheit genügen.
Durch die Zusammenführung von DevOps und MLOps in einer einzigen Software-Lieferkette erreichen Teams in Unternehmen ihre gemeinsamen Ziele – schnelle Auslieferung, Automatisierung und Zuverlässigkeit – deutlich effektiver. So entsteht eine effiziente und sichere Umgebung für die Entwicklung, das Testen und das Deployment des gesamten Software-Spektrums – vom Anwendungscode bis hin zu Machine-Learning-Modellen.
Mehr dazu finden Sie in Teil zwei dieser Serie, in dem wir die Vorteile und Chancen einer einheitlichen Software-Lieferkette näher beleuchten.
See what JFrog & GitHub can do together




