

Open Source is Under Attack

In this talk, Dan explains what software supply chain attacks are, what you need to know about them, and how you can start to protect yourself. Supply Chain attacks are nothing new to containers and cloud native computing. In fact, they predate software! But they are on the rise, and several aspects of containerized software make them easier to carry out and more lucrative. In fact, supply chain attacks increased by 78 percent in 2019, according to Symantec. Container images are much larger and more opaque than traditional software artifacts, making it easier to hide malicious code inside them. And container build tools are powerful enough to package code in any language, making it easier to accidentally include some compromised code. Finally, the ecosystem is still young, and best practices around artifact signing and distribution are still under development. Not all hope is lost, though! In this talk, you’ll also learn how to protect yourself against the most common attacks today, what work is going on across the industry to help solve the problem at its roots, and how you can get involved.



VIDEO TRANSCRIPT
Hey everyone, thanks for listening in to my session on open source supply chain security today. My name is Dan Lorenc, and I’m recording this session live from Austin, Texas. I’m a software engineering lead at Google and I’m also currently the chair of the Technical Oversight Committee for the continuous delivery foundation. I’ve been working in and around open source software for close to a decade now. So this topic is one that really hits close to home for me and keeps me up at night. Most of my time in open source has been spent in projects related to platform as a service systems, cloud technologies, containers and ci CD or continuous integration continuous delivery systems. Most recently, I helped start the tecton open source project.
And I’m now working on an industry wide effort to help secure the open source supply chain for everyone. Both of which I’ll talk about a little bit later. This is my first virtual event. And I’m hoping have a little fun with it. We’re gonna do a couple quizzes and polls later on where I want you to be interactive and answer in the chat. And please be honest with your questions. This is a judgment free talk. So here’s what I’m gonna cover today. I’m going to start by covering the state of open source supply chain security. Unfortunately, it’s under attack. I’ll cover how, by who and what you can do to protect yourself today. I’ll also discuss what we’re doing as an industry to help solve this for everyone. And then at the end, I’ll finish with with some links and pointers for how you can get involved to help out if you’re interested.
Before I get started, open source software is amazing. First of all, I spent most of my career using it and building. But we do need to face the facts as a community. Hiding the problems that we’re currently facing is not a solution to solving them. I’ll start by explaining one of the most terrifying and pressing problems facing open source today. And if you’re not terrified by the time this time, the session is over, please rewind and watch it again. It’s one of the benefits to doing this in a pre recorded fashion. All right, so our first interactive portion of this talk today, let’s do a quiz. I’m gonna start by trying to explain the problem facing open source security and open source supply chains with a metaphor. Hopefully, some people in this room recognize these. These are USB thumb drives, before Dropbox and Google Drive.
These are how people actually use to store and transfer files between computers. Crazy, right. All right, so let’s get start with a couple of questions. I want you to type yes or no in the chat to respond to these, right? If you found one of these on the street, if you’re just walking around and found one, sitting on the ground, would you pick it up? Take it inside and plug it into your personal laptop? All right, I’m gonna wait here for your answers in the chat. Please participate. Don’t make me call on people individually. Okay, great. All right. Question number two: let’s pretend you were heading into your office at work and you found one of these on the sidewalk. Would you bring this into your office? Plug this into a work computer? Okay, hopefully people are starting to get the theme here. All right. Now one final one.
Let’s take this to the extreme. Let’s pretend you work in a data center, and you’re on your way into your production data center, saw a flash drive sitting on the sidewalk outside your production data center. Sounds silly. Explain a little bit more there. Would you take this into your production data center and plug it into a Server? Okay, one last one to wrap this up. Since everybody hopefully gets answers to these correctly, have you received any kind of security training from any company you’ve worked for and what to do in one of these situations? Have you ever gone through training. They told me not to plug untrusted devices into your computers. Okay, hopefully most people have received some kind of training on this and understand why you’re not supposed to do this. Never tried to do a q&a in a recorded talk before.
Hopefully that worked out well. And we can continue this throughout the talk as you’re playing along. Hopefully. So there’s some examples. Hopefully everybody knows not to plug in untrusted devices into their machines, especially inside of a production environment. Because this has hopefully been hammered into us strongly by all of our security departments. This isn’t silly, though. This has been an actual attack that’s been used many, many times. It’s even carried out at the international level. If anybody remembers the Strusts net worm that was used to disrupt uranium enrichment in Iran, that was allegedly carried out like this.
USB flash drives were dropped near facilities in order to breach an air gap to get the Stusts net worm into these enrichment facilities to disrupt production. And personally, I even had to run out with this one’s almost showing how seriously my company Google takes this threat. I was living in San Francisco back in the time, probably 2013 or 2014. And a friend of mine had just gotten a brand new drone to fly it near the Bay Bridge on Embarcadero. Right next to where the Google offices is located. Drone technology was a little bit new at the time he was a little inexperienced flying it and I guess some wind came along while he was taking off. It sent the drone flying and got a little out of control and ended up crashing into a building across the street. He got lucky, he hit the Google building where I was working at the time.
He turned out to be pretty lucky with this. I went home and got my badge and went into the office and tried to look for the drove. By the time I’d gotten in there, the drone had already been confiscated by our security team. They’re a little bit concerned he was trying to spy on the office, but since I was an employee and vouched for him, and they agreed to give him the drone back as long as you show them the pictures on it, and that he wasn’t taking any pictures of the office. But this surprised me at the time, I hadn’t even thought of this. They were smart enough to not plug in his SD card to their machine themselves.
They made him go get his own laptop, plug that in and show it to them. That’s how scary plugging untrusted devices into a computer is. And that’s how creative some of these attacks are trying to get people to plug devices into their computers. I was really impressed by our security. Alright, so why am I talking about drones and uranium and what does that have to do with open source software? Time for another quiz. This one is a little bit more open ended. No Yes, no questions here. The same rules as before wants you to type your guesses into the chat. What’s the difference between plugging in USB flash drive that you find on the street into your laptop, and typing a command like this using your favorite package manager of choice to install an open source dependency? Type your guesses into the chat here.
What is the difference between these two situations? My answer, only one of these runs as root in production. This is a little bit funny. But it isn’t really a joke. In both of these scenarios, you’re taking code or binaries, you found somewhere whether it might be the internet or on a sidewalk and running this on a computer. The only difference is that usually NPM install express or whatever package manager of your choice you want to use, gets packaged up and runs alongside your code in a production environment. Well, the flash drive is stuck just on your work laptop. And that’s kind of the theme we’re getting at here.
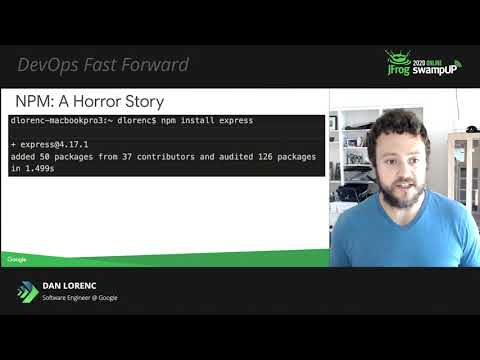
Running untrusted code, no matter how you found it is dangerous. Here’s an example of what we’re looking at with the NPM install Express case, some numbers broken out. When you type this command, before you get started writing a node application installing 53,000 lines of code that you probably haven’t looked at, just get started writing a simple Node JS app. This includes code from 37 different people. And then the transitive dependency tree here has over 126 packages just to install one package before you’ve written a single line of code. Again, I’m not trying to pick on NPM here, I’m just using this one as an example.
Um, next we’ll take a look at Go my favorite programming language and show how that suffers from some of the same problems. Okay, so in this next session, I’m gonna do a quick demo showing how easy it is to carry out one of these supply chain attacks and how hard it can be to spot one as an open source maintainer. For this demo, I’m going to be using a sample application I have here called numbers CI. This is written in the Go programming language and uses the new Go modules patch management system. This basically runs a simple command line app that takes an input as a number and tells you whether it’s even or odd. You go ahead and run this here. The demo gods are with me today, and will pass 4, an even number, so hopefully it prints 4 is even. Excellent. It works, this is where the applause should come in from my live demo working.
Alright, let’s try it down with an odd number just to make sure it works in both cases. I don’t know about you, as well, if that’s enough for me, and I’d be happy to ship this to production. Fortunately, if one of my teammates doesn’t like the custom logic, I have here, the modulo operator, and I get it, it’s been a while. If you haven’t taken a computer science class, you might not remember what this percent sign does. My teammate sent a PR to use a third party library here, it’s hopefully better tested. It tells us whether a number is even or odd. So let’s jump over to that PR and take a look. So here’s my repo on GitHub, number CLI and here’s a pull request. I’m going to switch over to using a library instead of our custom logic. My teammate says that this library is well tested and it should make our code easier to maintain and long term.
Alright, I get my custom logic here didn’t have any test here before. Let’s take a look at the diff. Here we go see that this uses the awesome library is odd in the Go dot mod file to take a look at the diff, cool, we use that dependency instead of our own. Now if you want to be a conscientious reviewer, we can go look at that code and check out the tests and make sure that it does work as described. So let’s pull that up. is odd. Cool. That seems to have some tests, you can look through those nice test cases, I’ll even cover zero which I forgot to test in mine. Let’s take a look at how it works. Let’s just be extra careful – cool, it uses another library called “is even” We’re going to be really careful routers today and even take a look at this library to make sure that this does what it says it’s going to do before we merge this code, up over here, look at the is even library. Awesome. This has its own tests to guess about that zero case we forgot about before and it seems pretty simple.
Even dot is even, this does the same modulo operator we did before. But hope since this one has tested reviewed and maintained, it should be better than using our own function. All right, we’re going to be really careful today and actually merge this PR locally and do some testing before we merge the branch. Go back to my editor here, I’m gonna check out that use library branch and we’re gonna run it again, just to make sure that we get the same results. Whoops, I can see here, this library started a crypto minor. Now my laptop might be mining crypto coins, it might have exploited all my passwords have no idea what happened. How is that possible? We were really careful.
We took a look at the third party library that was getting added. We didn’t look at its dependencies to see what was happening. This just goes to show how easy it is to carry out how hard your job is an open source maintainer is if you’re not reviewing all of your dependencies, and even if you are, it’s very tricky. I’ll give people a second here to think about how I could have done this without giving the answer and show where that crypto mining code came from. Alright, let’s see some guesses. If you have any guesses here, type them into the chat. Now I’ll show exactly what happened here and how you could have prevented this. The new Go modulo system doesn’t check your dependencies, it checked them into a vendor directory by default. So it can be hard to figure out exactly which version you’re using just by clicking around in the repositories if I did, if we do want to vendor it, which we don’t necessarily need to check these in, but if the vendor makes it easier to review exactly what’s being used, we can type go mod vendor, it’ll actually download the version from the Go module proxy and put them in our repo so we can take a look at that command, and now we have a vendor directory. Let’s open this up. The “Is odd code” code is still pretty simple.
This just calls even.iseven again, we can even jump over to that one. Whoops VS code isn’t working right now. Awesome. So even.iseven function still pretty simple, where is the crypto mining code coming in? Well, if we look through the rest of this repo, see there’s another file hidden here utils.go. This isn’t called directly, this uses the init function inside Go to hook in some logic doesn’t actually mine crypto, I wouldn’t do that to myself. But it does hopefully print that. If that print line hadn’t happened, then there would have been no way for me to detect this. So how did this sneak in, given that we even looked at the is even code and couldn’t find this. Let’s go back to that repo. Well, because there can be a whole bunch of different versions of this package published, and we didn’t necessarily look at the right one. So look through all the commits. This is the one that we’re using in our dependency manager. And you can see that this added that file to make it a little bit harder to find this was removed in the next few minutes. So if you just look at the head branch of this repo, you would miss that and see that I removed it right after. Now, if I wanted to be even worse, could have actually forced pushed over this branch and master deleting all records from GitHub and the Go module proxy system was still preserved that version. So my build would have worked in the future.
The point of this demo is to scare you a little bit. Imagine you’re a maintainer of an open source project that gets dozens of pull requests a week. Some of these might be changing one, two, or even hundreds of dependencies. If you’re not taking the time to actually look through every single line of code, that third party code that you’re pulling in your package management system, one of these supply chain attacks could happen to you, especially if you’re not reviewing the vendor directory. If you don’t know exactly what code is in your system, then you have no idea if you’re packaging stuff like this. Okay, now we’ll summarize a supply chain attack I just demonstrated with my sample application.
First, I introduced a new dependency to an open source project through standard GitHub pull request. If you’re the maintainer of any open source products, then you’re familiar with getting these from third party contributors. This dependency I added didn’t contain the malicious code itself, but it declared another dependency that did, that dependency in turn hid the malicious code, it was only present in one commit. Other commits were layered after that. So it was hard to find even if you were looking for it. This worked for a couple reasons that are unique to the GitHub pull request flow, and the Go module package management system. First of all, code review in a GitHub pull request, when you’re using a Go module package management system only shows dependency metadata by default. Code is not vendored or checked into the repository. So there’s no built in way in that code review flow to see all the vendor dependencies you’re pulling in without taking that repository, origin the pull request locally and building it yourself. This is time consuming.
And I’m willing to bet that the vast majority of open source maintainers don’t do this for every pull request, they merge. To Go module proxy is what actually stores the code in the system. So even though I left it up there on GitHub, just for demonstration purposes, I could have deleted that commit and still had the malicious version search by the Go module proxy. Now this is done for a whole bunch of good reasons. This makes it so that builds are reproducible, and an author deleting or renaming a repository doesn’t break the build of every downstream package. But it does have a side effect of making attacks harder to find by being able to remove them from git history. And finally, the number of dependencies in most projects in the Go ecosystem and all programming language ecosystems is growing rapidly. Even if we did have the tooling that allowed us to review this code line by line, it will be very hard for the maintainers of open source projects to be able to spend the time on that. So to sum this problem in a language agnostic way, we really need to take code review seriously. Hopefully, everyone is already doing this for first party code. Everyone working on a team.
It’s pretty standard practice now to review the code that your teammates are writing. But we’ve somehow with open source code let third party dependencies slipped through the cracks here. In general, we hope that there are many eyes on the problem. Since we’re using a trusted library. We hope that somebody else is looking at it and reviewing that code. But in general, when everyone is responsible for looking at code and open source system, that means no one is responsible. There’s no single person reviewing every library on GitHub, that would be impossible. I mean, we’re just hoping that somebody else is reviewing it, or that somebody else would notice something like this, and let us know. That’s not a great solution to this problem. Just to show the scale of the dependency management issue for a popular open source project, this here’s a snapshot of the dependency graph for Kubernetes, one of the most active repositories on GitHub today. Again, this uses the Go programming language and Go package management systems. So this graph is a printout of the Kubernetes dependency tree from a couple months ago, when the snapshot was taken. You can see just the vast scale is problem, every single one of these nodes, you can see how deeply interlinked they are.
Every single one of these nodes represents a potential attack vector for the Kubernetes tree. Malicious code gets inserted into any one of these that has a chance of making it into a Kubernetes mainline being part of a Kubernetes release. You can imagine how terrible that would be. Kubernetes does vendor their code by default which helps quite a bit in their review process. Over on the right side of the slide, we can see a snapshot of the vendor directory of Kubernetes. The way this works is the code is organized by the URL. So typically github.com slash some organization name, slash the repository. So this is just the top level showing the organizations, some of the packages coming in look like they’re coming from trustworthy sources like Microsoft. What about the others? I’m not trying to pick on these.
But we have no idea where this code is coming from. In general, it hasn’t been reviewed line by line, when we don’t necessarily trust the authors of this code. And even for the code that claims it’s from Microsoft, we have no real way of verifying that this isn’t signed anywhere. We have no way to ensure that Microsoft released this code. This is just placed in a folder in a vendor directory that claims it’s from Microsoft, and contributors sending code in a pull request to Kubernetes could have modified this. So we have tons and tons of attack points and very bad tooling in order to catch issues like this. We really need new tools, new practices and new systems to scale this problem to help solve it across the industry. As if 2020 couldn’t get any worse. Why is this happening now? Open Source has been around forever.
Package management has been around forever. Why is this suddenly a problem? This is a little timeline of supply chain attacks, including some recent ones. So we’ve known about this type of attack for decades and decades and decades. This was first published in a paper called reflections on trusting trust, which details the bootstrapping problem. Not only do you have to know the exact origin of all the code you’re using, you also have to know the exact origin of all of the binaries that are used to build and transform that code. If a compiler is hacking becomes vulnerable, that compiler can enter the backdoor and every binary builds after that, you might not even see it in review of the code. This demonstrates some novel attacks, where code was hidden inside of compilers and made it very, very hard to find. Much later on, we started seeing a lot more of these attacks in 2006, a whole bunch of the repositories for operating system level patch management inside of Debian and Red Hat, Linux distributions poisoned. This was a credential leak, so people were able to insert packages directly into the package manager.
Later on in 2010 is the Struts network that I talked about before. This use USB flash drives as a way to get into the supply chain where there was an air gap there pretty good wasn’t even being used. Later on in 2011, current dot org, where the Linux kernel source code was compromised. Large audit revealed that nothing serious was done. But imagine what could have happened if the Linux kernel was compromised all the way back in 2011 to today. This isn’t necessarily an attack in 2016. The left pad issue but this does show how deeply linked to third party package management systems can be inside programming communities, particularly node. js, which tends to have a bunch of small packages that are dependent on each other rather than large packages. Left pad was a package similar to mine is odd is even samples before it just contained one function, left pad, it added padding to the left side of a string or to line. This package was deleted. From the NPM package repository, which broke the builds of pretty much everything in the node ecosystem, because this package was a dependency of a dependency of a dependency of something that was used everywhere. The NPM package repository made some changes after that to prevent deletion outside of extreme cases. This was one of the biggest shocks to people using third party packages in NPM. To help kick off awareness of this issue. In 2017, there’s a very serious supply chain attack called Docker 123321.
Somebody set up this repository on Docker Hub, named a whole bunch of useful images, things like MySQL, and Tomcat were published here under Docker 123321. After these images got quite a bit of usage, partly because of the rising popularity of Docker images. A supply chain attack was inserted into these to install a crypto minor. The Go example we talked about before, it’s pretty easy to look through the code if you actually want to take the time to see where this stuff coming from. Inside of a Docker image it is generally on the order of a gigabyte large and getting table plaintext files and binaries. If you don’t take the time to review every single piece of that binary and realistically, how are you going to do that? And you have no idea what’s inside of it, you really have to make sure you’re trusting both the source code you’re using the package manager that source code is coming from, and the organization responsible for maintaining publishing those limits. There’s been a whole bunch more after this.
Bootstrap sass was a another example that’s not on here. And then most recently, there’s another one called webmin. Webmin is a popular web administration tool. It’s used all over to administer servers easily. A backdoor was inserted into a web=min release that compromised on the build server itself. Yeah, even if you have full access to the source code and review it, the binaries can be compromised. So you have to trust the organization is publishing those binaries as well. Again, a little bit more bad news here. Sorry, hopefully 2021 is a little bit better. I really hate to add fuel to the fire, but open source supply chain attacks in 2020 aren’t looking good. This is looking like the worst year on record. Any interpretation of these numbers, this is a massive problem that is only going to get worse over time. 11 million developers are using NPM. Each month manage node.js packages. There’s been almost an 80% rise in supply chain attacks in 2019. And 2020 is looking worse so far. Pretty much everyone is using open source software. Surveys carried out by different groups like black duck, Linux Foundation, have shown this to be true. And this isn’t a trend that’s declining, this is increasing. Organizations are not reducing dependency and open source is increasing over time.
So again, why now why are we only seeing these attacks? Well, it’s a combination of factors. The cost per hack in software is getting lower. There are more targets being published every day as people use more open source software. That means these are better targets, which is going to lead to more attacks. Open sources is rising again, the more the greater the usage of open source the greater the risk of open source supply chain attacks, and finally, improve General Security. Hackers and attackers want to take the easiest way in. As we finally get the tooling to harden all the other entry points and make it harder to insert backdoors. Open Source supply chain attacks are becoming more attractive because they’re the easiest way in that’s left so far. The scary part of this talk is over, everyone can relax.
If you need to pause here and go look at every line of your vendor code, please do so recording will be waiting for you. Now we’ll jump to the optimistic constructive hopeful part of the talk. We’ll talk about how you can protect yourself today. And then what we’re doing about this as an industry to help protect everyone. So, let’s start with some simple recommendations on how you can protect yourself your source code and your customers today. First of all, you need to lock down your repos. Repos are where everything starts in software development for your code is stored and the source of truth for all your dependencies as well. You want to lock these down as much as possible, limit the number of contributors and maintainers that have permission to merge things to your repositories and do basic other protections like enabling and requiring two factor authentication. Disable force pushes to make it harder for people to rewrite history and require code reviews so nobody can unilaterally make a change to the repository. Next, a simple way to protect yourself from attacks and your third party dependencies is to reduce the number of your third party dependencies. This can be a little bit painful. Using open source libraries is easy and a quick way to get started.
But these uh, this always comes with a trade off. By using these open source libraries, you’re placing trust in the authors and maintainers. Make sure to think critically about each one of these and decide if the benefit of using it is worth the cost, with the potential security problems. Every dependency is an attack vector. Then evaluate if you really need them all. Sometimes copying a little bit of code is better than taking a dependency on the entire library. So the ones that you can’t remember, if you want to audit these, you’re gonna take a careful look at them line by line to make sure there’s nothing you don’t want in your dependency tree. As you take updates, make sure that you’re tracking those too. Once you’ve got a good stable footing, being able to review changes to your dependencies on a weekly or monthly basis is a lot less painful and a lot easier to do as a team. You want to review these changes in these updates just like you would first party code. Nobody on your team can commit code without it being reviewed.
So why are you trusting a stranger on the internet to be able to make changes to your code without it being reviewed. And then a final way to help here is adding observability into your CI/CD pipeline. Your continuous integration continuous deployment system is what takes your source code all the way through to production. You want to make sure sure it’s observable and auditable so that in the case that something does go wrong, you have enough information stored to be able to figure out how vulnerable you are and exactly what happened. For example, if you don’t know exactly which versions of your source code are packaged and running in production, then you have no idea how to find out if something like this happened to you, and how vulnerable you are. Imagine a CVE report and the third party dependency. Do you have the tooling to know if you’ve ever deployed that version with third party dependency, you have the choice to know if that version is running in production today. If you don’t have this, and you don’t have your CI/CD system instrumented, then you’re in a world of hurt if something like does happen to you. So hopefully you’re taking the steps to protect yourself. I’m going to talk about what we’re doing to help solve this as an industry to make it easier and reduce the burden on maintainers. The first piece here is identity in software development. By removing a lot of the anonymity for critical open source software and understanding who the developers are, then it’s easier to place trust in these people. Today, a lot of artifacts are just signed and we have some weak pki infrastructure or know where code and binaries are coming from. But it’s hard to use and it’s not enough. We’re looking at this and kind of three main parts as an industry wide solution.
First of all, we need some kind of database and up to date identity for contributors. An anonymous person on GitHub with the default avatar should not be able to unilaterally make changes to a Linux kernel driver, for example. We need some kind of federated database here that isn’t owned by any single company. With up to date identity information, public key information, contact information for the contributors and maintainers of critical open source software. Next, we also need identity verification services for critical maintainers, you can sign up and create a bank account on your phone by taking a picture of your ID. But you can’t do that today for any kind of open source software. A whole bunch of critical infrastructure is protected by key exchange parties that hadn’t happened in the last 10 years. We need these services so that you can verify who you are. And people can place trust in that identity beyond just any of the existing services around today. And then we need a whole bunch of groundwork built up to make all of this possible. We need formats and tooling to securely manage this identity metadata.
So if people can look it up, people’s identities aren’t compromised, and it’s easy to sign up for and use. A couple different efforts are going on here. Sign commits and Git today are possible, but they’re a little bit tricky to set up. There’s some work going on inside of the core Git to a point to make this easier. Everyone already has SSH keys added to their GitHub accounts and there’s no reason you shouldn’t be able to use those SSH keys to sign commits rather than having to generate separate GPG ones and manage them across machines. We’re also seeing some upstream work to allow SSH key signatures into Git and to make it easier and more ubiquitous to sign commits on GitHub. The next big one is two factor auth everywhere. So many different compromises on source control systems and patch management systems happen because developers are not using two factor authentication where it’s available. We’re advocating for making this feature available on any source control management system and on the artifact management system.
And then helping flag repositories that don’t use two factor authentication. Even if you trust the maintainer of an open source package you’re using. If that maintainer is not using two factor authentication, then you’re trusting the strengthen their password and every other site that might ever use that password on today, there’s no tooling to see if it’s maintained.
If you’re using two factor authentication, making that visible, we really need to adopt these security practices that already exist across the industry. So once we’ve moved up beyond trusting the contributors and individuals involved and identity so we know who they are, we need to start building tooling to trust the source protocols. And this is a whole bunch of basic questions we need to be able to answer here. If you take a binary from the internet or inside of a container image, what code went into that binary, what tooling was used to produce that binary from that code? Today, none of this is packaged with that binary, it’s possible to figure out about a whole bunch of reverse engineering. Some efforts are going on in here, and software bill of material space, BoM, standard formats in order to describe how binaries were built and exactly what source code and libraries went into those binaries. That’s useful both for auditing as well as for CVE monitor. If you’re using a tool that has a whole bunch of dependencies and a CVE is found in those dependencies, you know, you’re supposed to be watching out for that.
I talked about identity before, but being able to attach information about who wrote it, who built who produced it, who is distributing a binary and source code is another huge one. And finally, is it secure? Not all vulnerabilities are introduced intentionally some of them are introduced accidentally as well, by crowdsourcing reviews and publishing findings and security audits and setting up a funding for all these programs, that we can help secure things in a scalable way. Every company shouldn’t necessarily need to audit every line of every dependency they’re using, we should be able to do this in a collective manner. Trusting the sources is necessary but an insufficient first step. You also need to trust the build process that’s used to transform that source code into artifacts that are used. If you don’t know who built the code, then you can’t really trust that artifact, even if you know who wrote the code. This requires us to build these federated strong identity programs I mentioned before. You also need to know what tool chain was used to build that code. Even if you trust the person that built it. If you don’t know which version of the compiler which version of the built environment was used, and it could still be issues.
CVEs are found in compilers all the time. If you don’t have that metadata, and you can’t trust that men data about exactly what was used to build your binary, then you’re still in trouble here. And finally, was the build secure? Think of all those curl pipe to bash lines and Docker files all over GitHub and Docker Hub? You don’t know what endpoints those are hitting and what’s being returned from those endpoints, then you can’t really trust the entire build process. There’s a whole bunch of work going on to make hermetic reproducible builds easy and usable by everyone. The artifact management system is kind of the final piece here. Attacks happen all the time where people with credentials to artifact management systems don’t type them well enough, and those get leaked, and malicious attackers are able to upload artifacts that have been compromised directly to the package manager bypassing the CI/CD system and the source code management system altogether. So you can secure identity information for who has access to these artifacts and package managers to trust to upload. Also a whole bunch of attacks on update process. Imagine if you had a way to block an update notification or update detection from a certain individual.
Then once known CVS are found you can force them to stand an older version and exploit those vulnerabilities. There a whole bunch of systems and research going on here to help prevent these types of attacks. Network is going on and the update framework and The notary v2 project for container images. Then tempering. Just because I uploaded an artifact and you download an artifact doesn’t mean it wasn’t tampered with in the middle. Signatures have been around for a while. But they’re not that ubiquitous, especially in the language ecosystems. So we need to make it easy to sign these change of custody so that when you get something you know that I was the one that produced it. And again, the standard software bill of material formats are important for making sure that we know what’s wrong with the packages. Package managers are everywhere today and new ones are appearing every day. There’s also a bunch of work that we need to do to improve package managers state of the art for them and get those improvements into all the new ones that are appearing for languages. In Go modules, I picked on them a little bit before my demo, but they have done some major improvements here. The new version selection algorithm helps prevent developers from accidentally upgrading something if you have changes they didn’t intend. In the module proxy server and transparency log make it easier to detect changes and prevent people from distributing malicious packets.
This work has resulted in some cool transparency log systems. And we need to extend this to online contract management systems and container images out there today. And finally, I talked about before, we need to make CVE reporting accessible and scalable for all the language package managers out there. That was just a high level overview of some work we need to do to summarize some of the other work happening. Programming Languages today, don’t really let you apply permissions at a dependency level. Imagine the Android app store or an app developer has to request permissions to do things like access the network or files on your device. Admins, you can install a package with NPM and not give it file system permissions because you don’t think it needs them. It would make it a lot harder to prevent things like cryptocurrency, mining and export and credentials. And then just that kind of boring, general hygiene improvement work I talked about. We have two factor auth, you know how signatures work, but people aren’t using it because it’s hard. We need to encourage them, teach them the importance of it and make it as easy to use as possible. All right, so hopefully I’ve scared you. But then given you a little bit of hope that this is going to be alright.
I’ll talk about how you can get involved and why you should. Supply Chain attacks are a serious problem for open source software and software in general, if you’re using it. So this is something you should be interested in solving. The there’s nothing new here. This is a standards, automation and data problem, nothing really groundbreaking, we just need to do the work that we know we need to do. So if we all focus on this together, I think that we can solve it and help prevent these attacks going forward. If this is interesting to you. We’re working on it and a whole bunch of different places. The tecton cd slash change repository on GitHub is a great place to jump in if you want to help work on a reproducible builds and trusting build processes in general. Alright, thanks for listening to my first virtual talk. And thanks for having me at swampUP. Here’s my contact information. And feel free to reach out if you’re interested in this talk or any of the things I mentioned.




