

Definition
Un registre MLOps centralise et gère les modèles ML, assurant leur suivi et contrôle de version du développement au déploiement
Aperçu
Face à l’augmentation de la complexité et du nombre de modèles en data science, un registre de modèles s’avère indispensable pour faciliter la collaboration, assurer la reproductibilité et établir une supervision efficace.
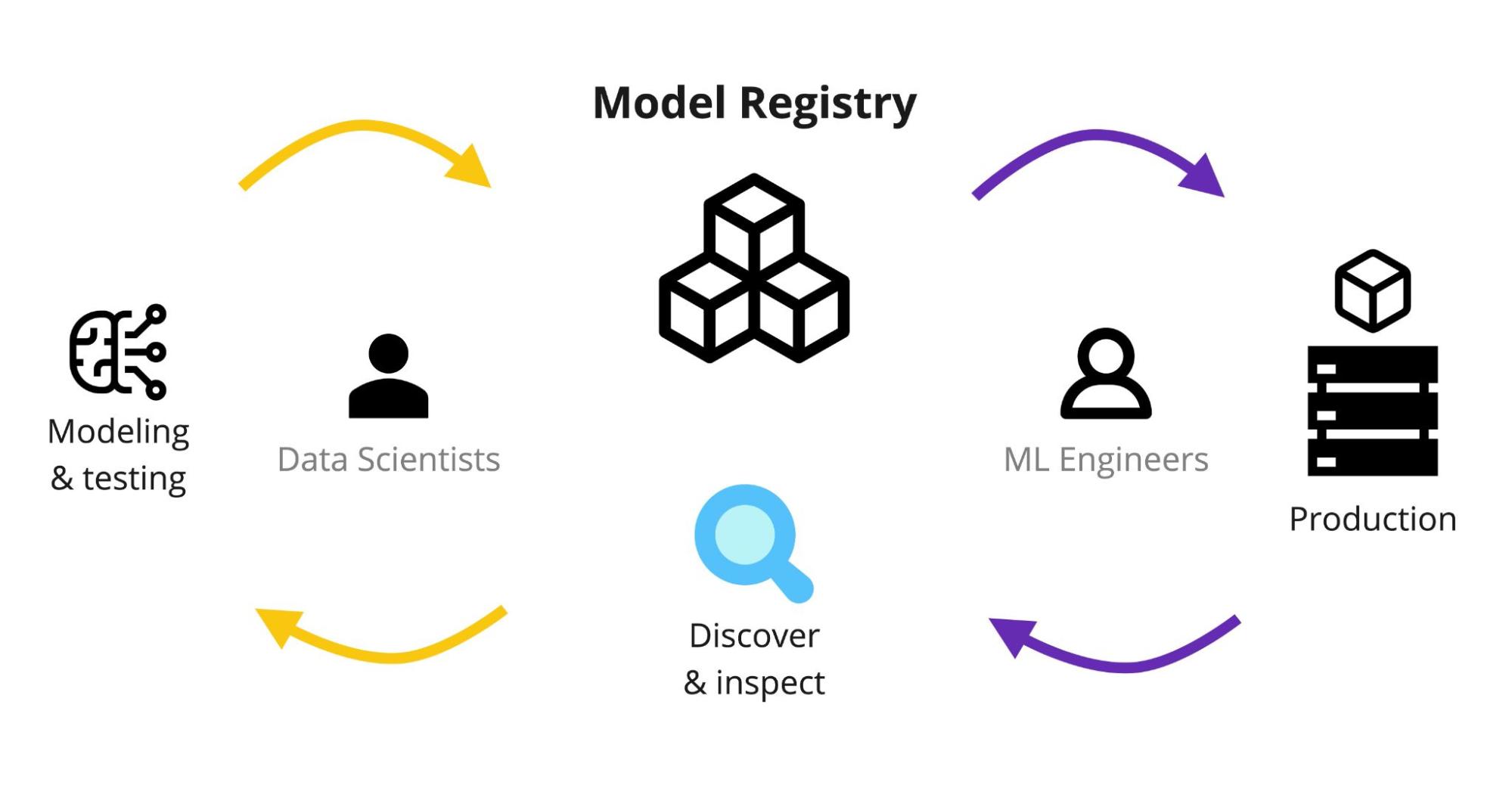
L’objectif principal d’un registre de modèles est d’offrir un environnement sécurisé et bien structuré pour le stockage et le suivi des modèles d’apprentissage automatique. Il rationalise le processus d’accès et de déploiement des modèles pour les data scientists, les ingénieurs et les autres parties prenantes, ce qui contribue à promouvoir la cohérence et la fiabilité dans l’ensemble de l’organisation.
Pourquoi avez-vous besoin d’un registre de modèles ?
Les principales caractéristiques d’un registre de modèles comprennent l’intégration avec les pipelines CI/CD, le contrôle des versions, la gestion des métadonnées des modèles, le suivi de l’évolution des modèles et la prise en charge de divers formats et cadres de modèles. L’utilisation d’un registre de modèles présente de nombreux avantages, notamment :
- Amélioration de la collaboration – Il facilite la collaboration et le partage des connaissances entre les équipes de data science en fournissant un dépôt centralisé pour la découverte et l’accès aux modèles existants. Cela permet également d’éviter les redondances et encourage la réutilisation.
- Amélioration de la reproductibilité – Un registre de modèles améliore la reproductibilité et la transparence car il simplifie le suivi des modifications, la reproduction des résultats et la compréhension de l’évolution des modèles grâce à la gestion de l’historique des versions et à l’enregistrement des métadonnées.
- Renforcement de la gouvernance et du contrôle – Un registre de modèles renforce également la gouvernance et le contrôle du cycle de vie de l’apprentissage automatique. Il aide les organisations à mettre en œuvre les meilleures pratiques, les règles et les politiques de sécurité en définissant les contrôles d’accès, les autorisations et les capacités d’audit.
Pour ces raisons, un registre de modèles est considéré comme un outil indispensable pour gérer et organiser efficacement les modèles d’apprentissage automatique (machine learning (ML) models). L’utilisation d’un registre de modèles peut considérablement améliorer la collaboration, la reproductibilité et la gouvernance dans les initiatives de science des données.
Gestion d’un registre de modèles
La première étape de l’utilisation d’un registre de modèles consiste à enregistrer le modèle. Il s’agit d’enregistrer des informations détaillées sur le modèle, comme son nom, sa description et les métadonnées pertinentes, afin de s’assurer que toutes les informations nécessaires sont facilement disponibles pour une référence ultérieure.
Une fois les modèles enregistrés, ils peuvent être gérés dans le registre de modèles. Il s’agit notamment de la gestion des versions, qui permet de suivre et de contrôler les différentes versions d’un même modèle. Il est important de conserver un historique des changements et de s’assurer que les expériences de ML peuvent être répétées.
L’intégration avec une plateforme MLOps est un autre aspect important d’un registre de modèles. Les plateformes MLOps simplifient le développement, le déploiement et la gestion des modèles ML en production. En s’intégrant aux plateformes MLOps, un registre de modèles facilite la collaboration et le déploiement en toute transparence, garantissant que les modèles de ML sont facilement disponibles pour utilisation, mise à jour et même rollback, si nécessaire.
Lorsqu’il est correctement exploité, un registre de modèles peut permettre aux équipes de partager, de suivre et de déployer facilement des modèles ML, ce qui accélère l’innovation et améliore les délais de mise sur le marché.
Les défis de la gestion des modèles sans registre de modèles
La gestion des modèles d’apprentissage automatique sans registre de modèles présente plusieurs difficultés qui peuvent compliquer le processus de développement et de déploiement. Voici quelques-unes des principales difficultés :
Difficultés liées au contrôle des versions : Sans registre de modèles, le suivi des différentes versions des modèles peut s’avérer fastidieux. Il est difficile de gérer les itérations, les mises à jour et les rollbacks, qui sont essentiels pour maintenir l’intégrité des modèles en production.
Manque de reproductibilité : La reproduction des résultats et des modèles peut s’avérer problématique en l’absence d’un registre centralisé. En effet, les configurations spécifiques, les versions de données et les paramètres utilisés pour former les modèles peuvent ne pas être systématiquement enregistrés ou facilement accessibles.
Une collaboration inefficace : La collaboration entre les membres des équipes peut être entravée par la complexité du partage des modèles et de leurs mises à jour respectives en l’absence d’un système centralisé. Cela peut entraîner des incohérences dans le développement et le déploiement des modèles entre les différents membres des équipes ou les différents services.
Défis liés au déploiement : Déployer la bonne version du modèle en production ou sélectionner le bon modèle pour un cas d’utilisation spécifique peut être source d’erreurs et prendre du temps sans un registre clair qui détaille les mesures de performance et les caractéristiques de chaque modèle.
Problèmes de mise à l’échelle : Au fur et à mesure que le nombre de modèles augmente, leur gestion sans registre peut entraîner des problèmes d’évolutivité. Il devient de plus en plus difficile de contrôler, de mettre à jour et de gérer efficacement un portefeuille de modèles en expansion.
Échecs en matière de conformité et d’audit : Garantir la conformité aux exigences réglementaires et mener des audits peut s’avérer difficile sans un registre de modèles. Un registre permet de conserver une trace claire de l’utilisation, des modifications et des performances des modèles, ce qui est essentiel à des fins de conformité et d’audit.
Difficulté à contrôler les performances des modèles : Le contrôle continu des performances des modèles en production peut s’avérer plus difficile sans registre. Un registre de modèles facilite généralement le suivi des performances au fil du temps et peut déclencher des alertes en cas de dégradation des performances d’un modèle.
Dans l’ensemble, l’absence d’un registre de modèles peut entraîner des inefficacités, un risque accru d’erreurs et des progrès entravés dans le développement et le déploiement de modèles, ce qui affecte l’efficacité globale des initiatives d’apprentissage automatique au sein d’une organisation.
Garantir la reproductibilité et l’évolutivité
Un registre de modèles est également important pour garantir la reproductibilité et l’évolutivité. La reproductibilité est cruciale dans l’apprentissage automatique pour maintenir la cohérence et la fiabilité. Un registre de modèles facilite le suivi des versions exactes des modèles utilisés pour la formation et les tests, ce qui simplifie la reproduction et la validation des résultats. En outre, un registre de modèles favorise l’évolutivité en fournissant une source unique de vérité pour tous les modèles, ce qui permet aux équipes d’accéder facilement aux modèles et de les déployer dans différents environnements.
Importance du contrôle et du suivi des versions des modèles
En l’absence d’un système centralisé, il est extrêmement difficile de suivre les différentes versions des modèles, ce qui peut être source de confusion et d’erreurs. Le contrôle des versions est essentiel pour garantir que le bon modèle est déployé dans la production, et que toutes les modifications apportées peuvent être suivies et annulées si nécessaire.
Registre de modèles et MLOps
Le registre de modèles et les MLOps constituent l’épine dorsale du développement et du déploiement des logiciels modernes. Ils jouent un rôle essentiel dans la gestion et l’organisation des modèles d’apprentissage automatique, en favorisant la reproductibilité et en facilitant la collaboration entre les data scientists, les ingénieurs et les autres parties prenantes.
Niveaux de maturité des MLOps
Les organisations passent généralement par trois niveaux de maturité lorsqu’elles s’efforcent de mettre en place une initiative MLOps intégrée.
Niveau 0 : Le registre de modèles sert de dépôt centralisé où les modèles formés sont stockés, mis à jour et partagés. Il normalise l’organisation des modèles et des métadonnées qui leur sont associées, telles que les mesures de performance, les données de formation et les informations sur le déploiement.
Niveau 1 : Le registre de modèles permet aux organisations de suivre l’ensemble du cycle de vie d’un modèle, du développement au déploiement et au-delà. Il permet aux équipes de gérer différentes versions de modèles, de suivre les modifications et de revenir aux versions précédentes si nécessaire. Le registre de modèles sert de source unique de vérité pour tous les modèles, garantissant la reproductibilité et facilitant la collaboration.
Niveau 2 : Le MLOps comprend les méthodologies et les outils utilisés pour déployer et gérer efficacement les modèles d’apprentissage automatique dans un environnement de production. Il couvre l’ensemble du cycle de vie d’un modèle, y compris la formation, les tests, le déploiement, la surveillance et le réentraînement périodique. Le MLOps veille à ce que les modèles soient mis en œuvre et maintenus à grande échelle, avec une gouvernance et une supervision appropriées.
Avantages pour les data scientists et les ingénieurs ML
Les scientifiques des données, qui sont les principaux développeurs et déployeurs de modèles d’apprentissage automatique, peuvent considérablement améliorer leur flux de travail et leur productivité grâce à un registre de modèles fiable. Voici quelques avantages clés que les scientifiques des données peuvent tirer d’un registre de modèles :
Renforcer la collaboration et le partage des connaissances
En créant un environnement où le partage des connaissances est prioritaire, les scientifiques des données et les ingénieurs ML peuvent tirer parti d’une expertise et de perspectives diverses, ce qui conduit à des solutions plus innovantes. Les outils et les plateformes qui facilitent une communication transparente et le partage des données peuvent aider à synchroniser le travail des différents membres de l’équipe, à réduire les redondances et à accélérer le processus de résolution des problèmes. Cela permet non seulement d’accélérer les délais des projets, mais aussi d’améliorer la qualité globale des modèles développés.
Améliorer la gouvernance et la conformité des modèles
Alors que le déploiement de modèles d’apprentissage automatique se banalise, il est crucial de s’assurer que les modèles sont conformes aux politiques internes et aux normes réglementaires. Des cadres efficaces de gouvernance des modèles permettent de suivre les versions des modèles, de gérer les autorisations et d’auditer leur utilisation. Cela permet non seulement de répondre aux exigences de conformité, mais aussi de maintenir l’intégrité et la fiabilité des modèles. Pour les data scientists et les ingénieurs ML, une gouvernance solide signifie moins de temps consacré aux processus bureaucratiques et plus à l’innovation et à l’optimisation des modèles.
Rationalisation du déploiement et de l’inférence des modèles
La rationalisation du processus de déploiement des modèles garantit que les modèles passent de la phase de développement à la phase de production en douceur et avec un délai de commercialisation réduit. La simplification du processus de déploiement permet également aux ingénieurs ML et aux data scientists de se concentrer davantage sur l’affinage des modèles et moins sur les aspects techniques du déploiement. En outre, un déploiement efficace est directement corrélé à l’amélioration des performances du modèle et à des temps d’inférence plus courts, ce qui est essentiel pour les applications nécessitant un traitement des données en temps réel.
En se concentrant sur ces domaines clés, les data scientists et les ingénieurs ML peuvent non seulement améliorer leur productivité, mais aussi s’assurer que leurs modèles sont robustes, conformes et rapidement intégrés dans les environnements de production, maximisant ainsi l’impact de leur travail.
JFrog comme registre de modèles
JFrog permet aux entreprises non seulement de bénéficier d’un registre de modèles, mais aussi de gérer, de tracer et de sécuriser le flux de toutes les dépendances qui permettent aux modèles de fonctionner de manière sûre et prévisible au sein des applications. JFrog permet de sécuriser les projets de logiciels alimentés par l’IA en versionnant et en empaquetant les modèles de la même manière que n’importe quel autre binaire de logiciel. Il permet également d’assurer la traçabilité et la provenance à des fins de conformité.
La gestion des modèles ML de JFrog simplifie l’intégration des opérations d’apprentissage automatique pour les équipes DevOps et de sécurité en utilisant la plateforme JFrog existante, permettant ainsi aux ingénieurs ML et aux data scientists d’incorporer de manière transparente leurs flux de travail, en étendant les pratiques sécurisées de la chaîne d’approvisionnement logicielle au développement de modèles ML. En outre, JFrog Xray introduit des fonctions de sécurité ML qui permettent aux organisations d’identifier et d’empêcher l’utilisation de modèles sous licence malveillants ou non conformes.
Intégration de JFrog aux outils ML existants
En outre, JFrog s’intègre de manière transparente à vos flux de travail ML existants, ce qui simplifie la gestion et le déploiement de vos modèles d’apprentissage automatique. Avec JFrog, vous pouvez facilement importer des modèles à partir de votre environnement de développement préféré et les intégrer dans vos pipelines ML existants. Notre API et nos SDK complets permettent une intégration aisée avec les frameworks ML les plus courants, garantissant ainsi la compatibilité et l’efficacité.


