

Définition
La mise au point de ces modèles sur des ensembles de données étroitement ciblés leur permet d’acquérir une expertise approfondie du domaine, ce qui améliore considérablement leur précision et leur permet d’adopter un comportement finement adapté à des applications spécifiques.
Introduction au fine-tuning des LLM
L’avènement des modèles génératifs, notamment des grands modèles de langage (LLM) tels que ChatGPT et Bard, représente une avancée significative dans le domaine de l’intelligence artificielle. Ces modèles excellent dans la production de textes semblables à ceux des humains, transformant ainsi notre interaction avec la langue par le biais de machines. Cette analyse porte sur le réglage fin des LLM avec des ensembles de données personnalisés afin d’améliorer leurs performances et leur précision pour des applications spécifiques.
Comprendre les LLM et les modèles génératifs
Les LLM, pierre angulaire des modèles génératifs, sont conçus pour assimiler et générer du texte à partir de vastes ensembles de données. Leur application dans divers secteurs a permis d’améliorer considérablement l’expérience des clients et de donner aux entreprises un avantage concurrentiel inégalé. Qu’il s’agisse d’automatiser des dialogues complexes de service à la clientèle ou d’élaborer des contenus personnalisés, les LLM redéfinissent les capacités technologiques.
Nécessité d’affiner les LLM
Pourquoi affiner les LLM ? Malgré leurs vastes capacités, les LLM polyvalents ne parviennent pas toujours à accomplir des tâches spécialisées en raison de leur entraînement large et diversifié. La mise au point de ces modèles sur des ensembles de données étroitement ciblés leur permet d’acquérir une expertise approfondie du domaine, ce qui améliore considérablement leur précision et leur permet d’adopter un comportement finement adapté à des applications spécifiques.
Améliorer la performance des modèles via un fine-tuning
- Connaissances spécifiques à un domaine : Le perfectionnement confère aux LLM une compréhension approfondie des domaines spécialisés, qu’il s’agisse du jargon juridique, de la terminologie médicale ou des nuances du service à la clientèle.
- Amélioration de la précision et de la pertinence : En apprenant à partir d’exemples spécifiques à un domaine, les modèles affinés offrent des réponses qui sont non seulement précises, mais aussi très pertinentes pour la tâche à accomplir.
Généralisation vs spécialisation
L’équilibre entre la généralisation et la spécialisation est essentiel. Les modèles à usage général, bien que polyvalents, manquent souvent de la profondeur requise pour les applications de niche. Inversement, les modèles spécialisés s’épanouissent dans des contextes spécifiques, fournissant des informations et des solutions qui sont profondément alignées sur les exigences d’un domaine particulier. Le fine-tuning est le pont qui nous permet de tirer parti des forces des deux approches, en créant des modèles qui sont à la fois adaptables et hautement compétents.
Applications concrètes – La polyvalence à travers les secteurs d’activité
- Analyse de documents juridiques : les LLMs spécialisés sont capables d’analyser et d’interpréter des textes juridiques complexes, facilitant ainsi la recherche et la préparation des dossiers.
- Recherche médicale : les modèles perfectionnés peuvent passer au crible de vastes bases de données de recherche, identifier les études pertinentes et résumer les résultats en une fraction du temps qu’il faudrait à un être humain.
- Service à la clientèle : automatiser les réponses aux demandes des clients grâce à une compréhension nuancée et à la prise en compte du contexte, afin de réduire les temps d’attente et d’améliorer la satisfaction.
- Création de contenu : Produire des articles, des récits et des rapports adaptés à des publics, des styles ou des formats spécifiques, afin d’améliorer l’engagement et la portée.
- Soins de santé : résumer les dossiers des patients, la littérature et les résultats des recherches pour étayer les processus de diagnostic et de traitement.
Le processus de fine-tuning
La mise au point d’un LLM est un processus à multiples facettes, impliquant plusieurs étapes clés, de la préparation du dataset au déploiement du modèle et à l’optimisation continue.
Sélection d’un modèle à affiner
Le choix du bon modèle est la première étape du fine-tuning. Pour cet exemple, procédons au fine-tuning d’un LLM proposé par Hugging Face. Cette plateforme, bien connue pour sa riche bibliothèque de modèles open source et sa communauté active, est idéale pour débuter. Pour ce guide, nous allons affiner un LLM open source – le modèle DialoGPT-large de Microsoft pour sa robustesse et sa polyvalence dans la génération de texte.
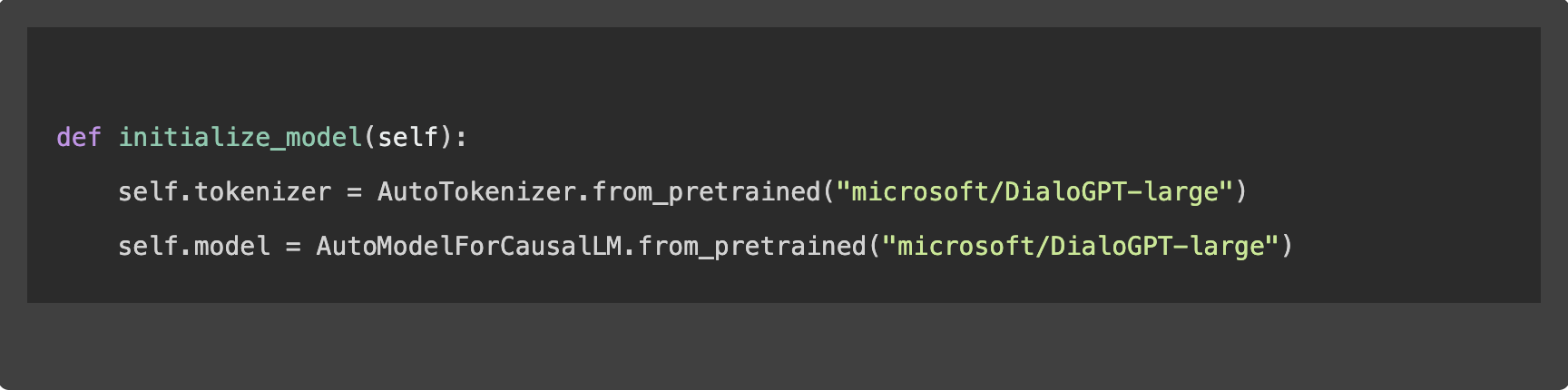
1. Initialisation du modèle
Pour lancer le processus de fine-tuning, chargeons d’abord le modèle sélectionné et son tokenizer, qui prépare le texte pour le modèle :
2. Fine-tuning du modèle
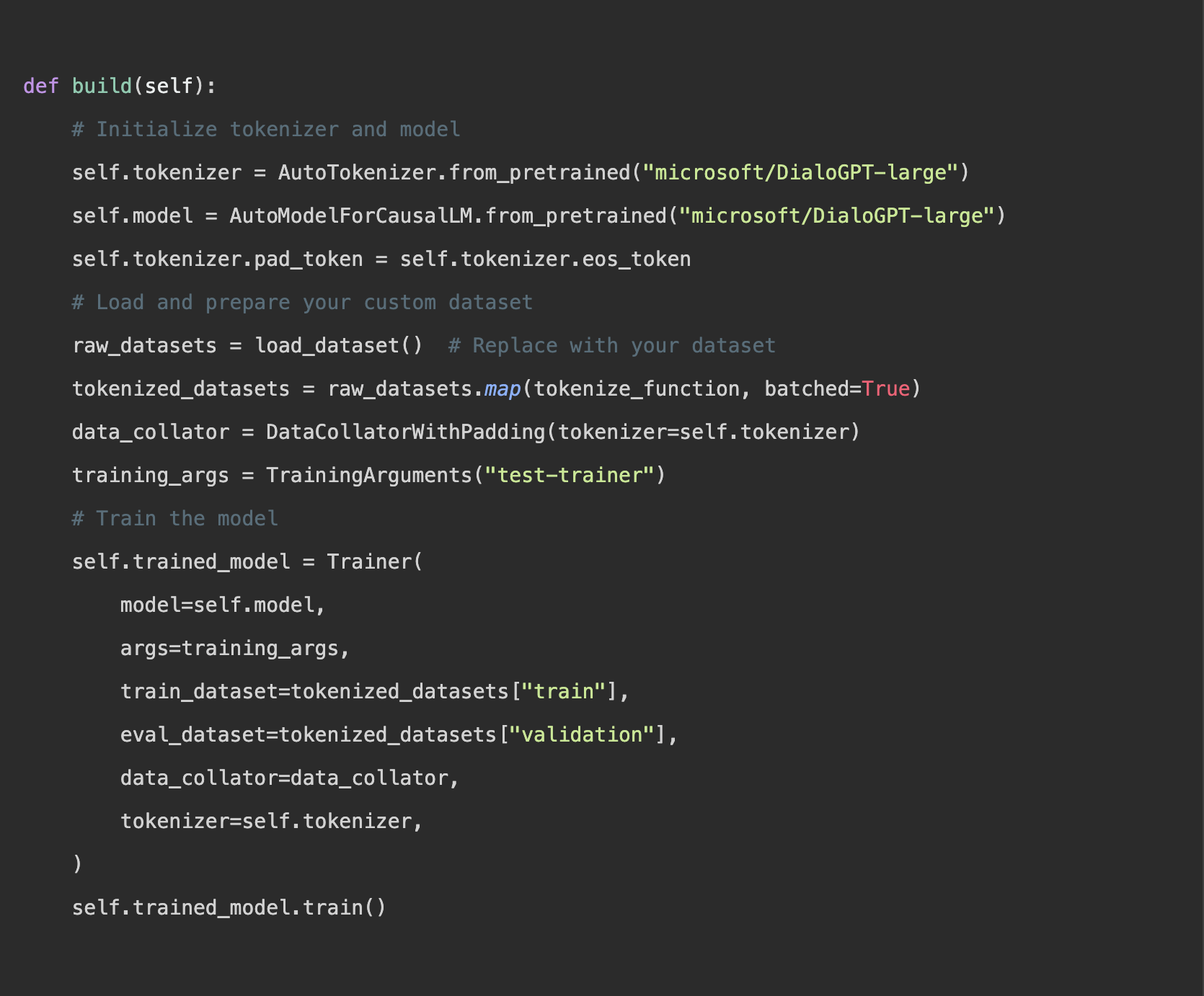
L’essentiel du fine-tuning consiste à adapter le modèle à votre dataset, ce qui lui permet d’apprendre à partir de vos données spécifiques et de mieux s’aligner sur la tâche à accomplir :
3. Préparation à l’inférence
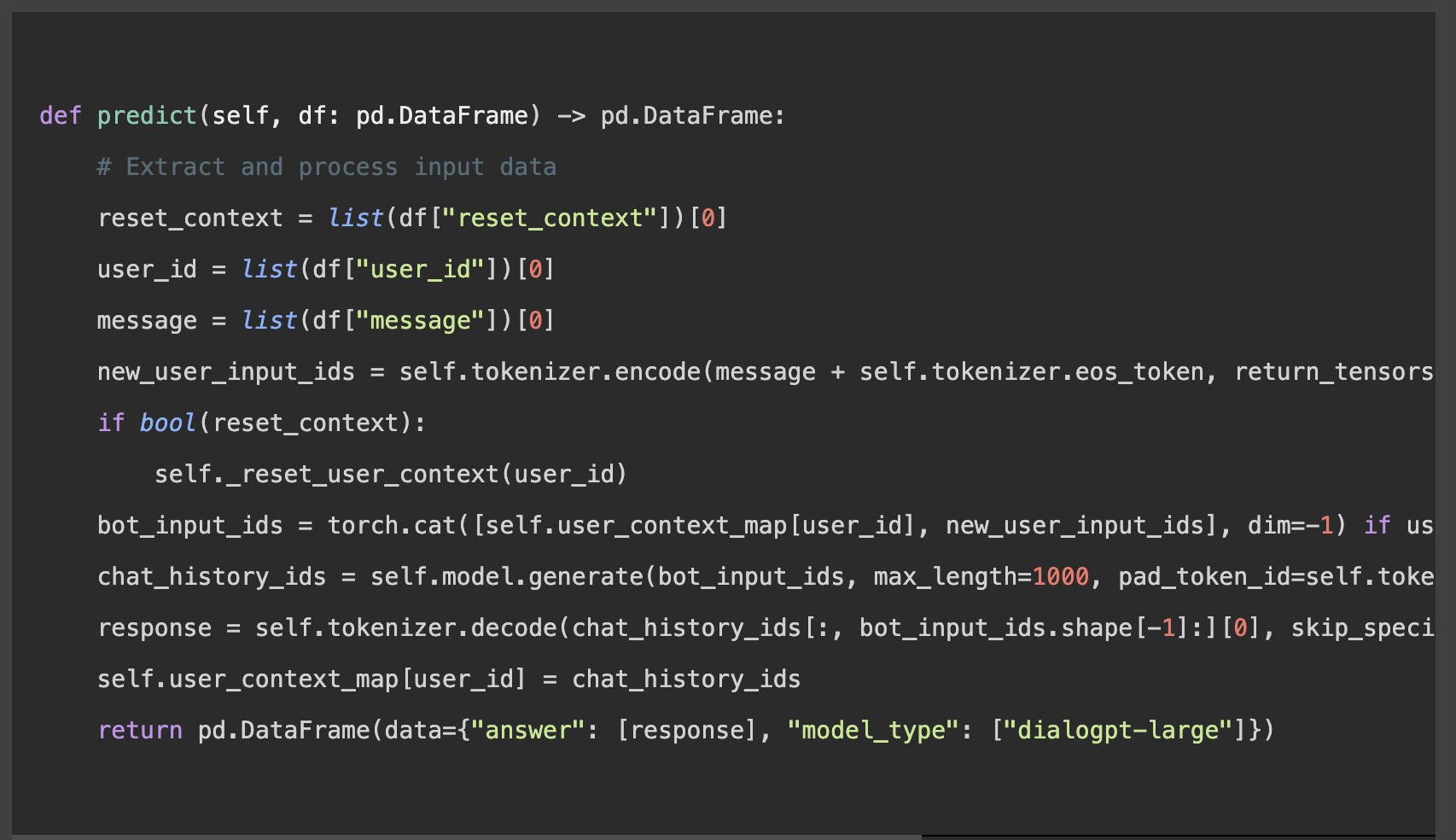
Afin de produire des prédictions fiables, il est essentiel que les données soient bien structurées pour conserver le contexte et faciliter l’interaction utilisateur :
4. Prédiction
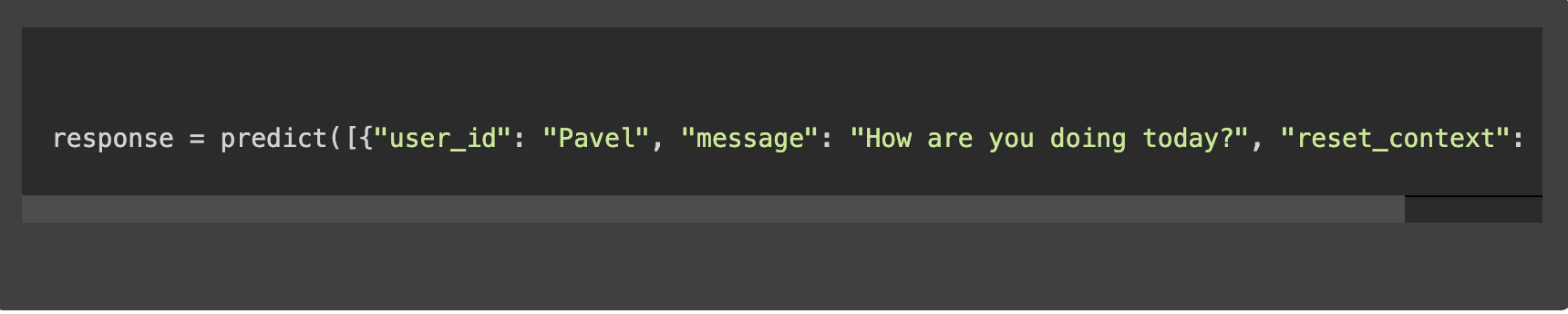
Un exemple d’invocation de la fonction de prédiction pourrait ressembler à ceci :
Facteurs clés à prendre en compte lors du fine-tuning d’un LLM
Préparation et sélection des données
La pierre angulaire d’un fine-tuning efficace est l’assemblage d’un dataset pertinente et de haute qualité. Cet ensemble de données guide non seulement le processus d’apprentissage du modèle, mais définit également les limites de son expertise.
Pour affiner un LLM afin d’améliorer les modèles, par exemple un chatbot d’assistance technique, le processus comporte plusieurs étapes rationalisées :
- Collecte des données : compiler un ensemble de données provenant des interactions avec le service clientèle, en vous concentrant sur les demandes et les réponses techniques, soit environ 50 000 entrées.
- Nettoyage des données : supprimer les détails non pertinents, tels que les informations personnelles et les discussions hors sujet, afin de vous assurer que le modèle apprend à partir d’un contenu utile.
- Annotation : il est possible de classer les données par catégories (par ex., par type de problème tel que les problèmes d’installation ou d’interface utilisateur) afin d’aider le modèle à comprendre les différents domaines de problèmes.
- Fractionnement de l’ensemble de données : diviser le dataset nettoyé en ensembles d’entraînement (80 %), de validation (10 %) et de test (10 %) afin de soutenir le processus d’apprentissage et d’évaluation du modèle.
- Prétraitement : utiliser le tokenizer du modèle pour convertir le texte dans un format qu’il peut comprendre, le préparant ainsi pour le processus de fine-tuning.
Cette approche garantit que le modèle de chatbot est spécifiquement adapté pour répondre aux problèmes logiciels, améliorant ainsi sa capacité à fournir une assistance pertinente et précise.
Ressources de calcul
Le fine-tuning des grands modèles linguistiques (LLM) requiert une puissance de calcul importante, nécessitant souvent des GPU ou des ressources informatiques basés sur le Cloud pour une gestion efficace du workflow. Pour répondre à ces exigences, l’utilisation de plateformes Cloud comme AWS et Google Cloud offre une puissance de calcul modulable. En outre, l’application de techniques d’optimisation de l’efficacité, telles que l’élagage et la quantification du modèle (en anglais, model pruning and quantization), permet de réduire la taille du modèle et les besoins de calcul tout en préservant les performances. Ces stratégies garantissent que le processus de fine-tuning est à la fois gérable et rentable.
Réglage des hyperparamètres et entraînement des modèles
- Taux d’apprentissage : détermine la taille des étapes du modèle lors de l’optimisation. Si elles sont grandes, le modèle risque de dépasser les solutions optimales ; si elles sont trop petites, l’apprentissage risque d’être trop lent. Par exemple, il est courant de commencer avec un taux d’apprentissage de 5e-5 et de l’ajuster en fonction des performances de validation.
- Taille du lot : le nombre d’exemples de formation utilisés dans une itération. Des lots de petite taille peuvent conduire à une convergence plus stable, tandis que des lots plus importants peuvent accélérer le processus d’apprentissage. Une taille de lot de 16 ou 32 est typique pour les tâches de fine-tuning.
- Nombre d’époques : indique combien de fois le dataset d’apprentissage est passé par le modèle. Un nombre accru d’époques peut favoriser l’apprentissage, mais au-delà d’un certain seuil, le modèle risque de surajuster (overfitting). Expérimenter avec 3 à 5 époques est souvent un bon point de départ.
L’ajustement de ces hyperparamètres nécessite un équilibre entre rapidité et précision. Un réglage efficace implique souvent l’exécution de plusieurs essais d’entraînement avec des paramètres variés, en contrôlant la perte de validation pour identifier la configuration optimale.
Expérimentation et validation
L’expérimentation et la validation sont des pratiques essentielles pour affiner les LLM afin de garantir que les modèles sont à la fois efficaces et généralisables.
- Tests A/B : il s’agit de mener des expériences où deux ou plusieurs ensembles d’hyperparamètres sont testés en parallèle afin de comparer leurs performances. Par exemple, on peut exécuter deux versions d’un processus de fine-tuning d’un modèle, la version A utilisant un taux d’apprentissage de 5e-5 et la version B de 3e-5. En comparant leurs performances sur un ensemble de validation, on peut déterminer quel taux d’apprentissage donne les meilleurs résultats.
- Ensembles de validation : partie essentielle de l’entraînement des modèles, les ensembles de validation sont utilisés pour évaluer les performances d’un modèle sur des données qu’il n’a pas vues pendant l’entraînement. Cette pratique est essentielle pour éviter l’ajustement excessif (overfitting), c’est-à-dire le fait qu’un modèle donne de bons résultats sur les données d’apprentissage, mais de mauvais résultats sur les données non utilisées. Par exemple, après chaque période d’entraînement, la précision ou la perte du modèle est évaluée sur l’ensemble de validation. Cette boucle de rétroaction permet de procéder à des ajustements avant l’évaluation finale, ce qui garantit que le modèle est robuste et qu’il fonctionne bien avec de nouvelles données.
Déploiement et optimisation continue
Après le processus méticuleux de sélection, d’initialisation et de mise au point du modèle, son déploiement dans un environnement réel marque une étape importante. C’est au cours de cette phase que le modèle commence à interagir avec les données réelles, qu’il s’agisse d’automatiser les réponses d’un service client ou de générer du contenu. Par exemple, le déploiement d’un modèle affiné pour améliorer un chatbot de service client implique non seulement l’intégration technique, mais aussi la préparation de l’infrastructure pour prendre en charge les interactions en temps réel, ce qui nécessite un mélange de compétences issues des équipes de data scientists et d’ingénieurs.
Néanmoins, le processus ne prend pas fin après le déploiement. L’optimisation continue joue un rôle crucial dans le maintien de la pertinence et de la performance du modèle. Ce cycle continu de suivi, d’évaluation et de mise à jour du modèle garantit son adaptation aux nouvelles données, tendances et besoins émergents. Par exemple, un système de recommandation pour l’e-commerce qui s’appuie sur les données des ventes passées devra être régulièrement mis à jour pour intégrer les nouvelles gammes de produits et l’évolution du comportement des consommateurs, afin de rester précis et efficace.
Gestion du cycle de vie
Une gestion efficace du cycle de vie, intégrant des outils de contrôle et un apprentissage continu, est essentielle. L’utilisation de plateformes telles que TensorBoard ou Weights & Biases permet aux équipes de suivre les mesures de performance et d’identifier les modèles susceptibles de dériver ou d’être moins performants. Cette approche proactive garantit que les modèles restent efficaces et performants longtemps après leur déploiement initial.
L’apprentissage continu, qui consiste à intégrer périodiquement de nouvelles données dans l’ensemble de formation, garantit que le modèle évolue en même temps que son domaine opérationnel. Cette capacité d’adaptation est essentielle dans des secteurs dynamiques comme l’agrégation d’actualités ou l’analyse financière, où rester à jour sur les dernières informations est crucial pour préserver performance et pertinence.
L’avenir des LLM et le rôle des praticiens ML
L’avenir des grands modèles linguistiques (LLM) promet des applications encore plus sophistiquées et polyvalentes dans divers secteurs. Au fur et à mesure que ces modèles évoluent, l’expertise des praticiens du machine learning (ML) devient indispensable pour plusieurs raisons :
- Orienter le développement : les praticiens ML jouent un rôle central dans l’orientation du développement des LLM vers des modèles plus efficaces, plus précis et plus sensibles au contexte. Par exemple, leurs idées peuvent aider à affiner des modèles tels que GPT-4 pour des tâches nuancées telles que l’analyse juridique ou l’éducation personnalisée, en veillant à ce que les modèles puissent comprendre et générer un contenu hautement spécialisé.
- Adaptation aux besoins spécifiques : grâce au fine-tuning, les praticiens ML adaptent des modèles généraux pour répondre à des besoins industriels spécifiques, comme la création d’un modèle adapté à l’aide au diagnostic médical en l’entraînant à partir d’une vaste littérature médicale et de données sur les patients. Leurs compétences en matière d’ajustement des hyperparamètres et de sélection des ensembles de données pertinents garantissent que les modèles fournissent des résultats précis et fiables.
- Déploiement éthique : il est primordial de veiller à ce que les LLM soient utilisés de manière responsable et éthique. Les praticiens ML sont à l’avant-garde de la prise en compte des considérations éthiques, telles que l’atténuation des préjugés et la protection de la vie privée. Par exemple, ils mettent en œuvre et supervisent des cadres d’évaluation de l’équité et des biais pour les modèles utilisés dans le recrutement, afin de prévenir les pratiques discriminatoires.
À mesure que les LLM s’intègrent de plus en plus dans le tissu des industries, le rôle des praticiens du machine learning dans l’exploitation responsable et innovante de leur potentiel ne cessera de croître, garantissant que ces outils puissants profitent à la société tout en respectant les normes éthiques.
Résumé
Le processus de fine-tuning des LLM sur des datasets personnalisés est un processus nuancé qui s’étend de la sélection et de la préparation minutieuses des données jusqu’au déploiement éthique et à la gestion continue du modèle. Ce processus permet non seulement d’améliorer les performances et la précision du modèle, mais souligne également le rôle essentiel des praticiens de du machine learning dans la gestion des complexités du développement, du fine-tuning et des considérations éthiques. Au fur et à mesure que les LLM évoluent, leur potentiel de révolution des industries s’accroît, promettant des applications plus sophistiquées et la nécessité d’une innovation continue et d’une gestion responsable dans le domaine de l’IA.


