What’s New in JFrog Artifactory and Xray?
2020 is definitely a year to remember for all of us. Like you, we’ve been working from home and dealing with all kinds of new challenges and processes. But while we’re working through it side by side with you, we’ve continued to drive exceptional value with enhancements to the JFrog Platform. This includes changes in all products that allow better CI/CD orchestration, better binary management, innovative distribution, enhanced security, creative hybrid architectures and a better end-to-end platform experience. Here are all the new features we will cover in this webinar:
Artifactory
- New supported package types: Alpine, Docker OCI, Helm v3
- Docker rate limits adjustments
Xray
- New Reports Infrastructure (fully supported also with API )
- Ignore rules enhancements (fully supported also with API , advanced capability only in API – e.g ignore by base docker image)
- Stability and Performance improvements
Webinar Transcript
Hi, everyone. I’m very excited to be here with you today and present you what’s new in JFrog Xray. We had a really exciting year. We released many features, which I cannot cover everything today. We released about every two weeks, so many exciting things in Xray. I chose three important features that will help you to manage your findings in Xray, which will give you better workflows and better usability. So, without further ado, let’s start.
The agenda for today: I will present the first feature, which is Xray Reports, which includes three new reports for Xray: vulnerabilities reports, license due diligence report, and violations report. Next, we’ll move on to Ignore Rules. Many new exciting features around the Ignore Rules mechanism: better granularity, time-based ignore. And last, we’ll talk about the multiple license new permissive approach. That’s it, so let’s start with the Xray Reports.
First, those are brand new reports. We didn’t have those kind of reports in the past to help you collect and view insights about your Xray findings. Xray detects vulnerabilities licenses. It allows you to define policies on your compliance or security that creates many violations. Until now, you could see those findings either in a level of an artifact or a build or a package, or in the level of your watch, which is a scope that you define your policies in.
Now, with the new reports, you can create your own scope, which can contain either repositories, several repositories, several repo path, or several builds or release bundles if you’re using our JFrog distribution. So it will help you gain insight on a bigger scope and it will also allow you to define advanced filters to narrow down to those findings that you’re looking for, let’s say by severity or by a certain CVSS score or a list of licenses that in your interest.
The reports will also allow you to share your reports with others. You can export the reports to CSV file, JSON, or PDF, and then you can share it either with other people or with other applications, so we can take the data and slice and dice it in any format that you want.
Those new reports will require a new permission role that we created. This permission role is called “Manage Reports”, and you can give it either in a user level or in a group level. Everything I just told you about regarding the reports, of course, is also available through our APIs, the same as all capabilities of JFrog products are first thing available in REST APIs.
I think, without further ado, let’s move to the Xray reports demo. Let me share my screen. Okay. This is the JFrog platform. You can see here in the security and compliance navigation, you have a new navigation that we didn’t have before, which is the reports.
One thing before I start: the actual reports is actually serves as a point in time reports. So once you are generating the reports on any scope or filters that you choose, once it’s being generated, it cannot be changed. It takes a snapshot of the data in that point of time, and that way, you can save reports and also have historical data on what was the state of your data in that point of time which you generated the report. It’s not like a live report that is being updated every time. The live data you can see through the platform from anywhere you want, but the reports are just generating and are being saved at that point of time.
Here we are in the report section. You can see that we have the list of already generated reports and we can generate a new report. Let’s start with the vulnerabilities report.
You can see here that you can choose the type of report and the scope that I was talking about. Now, you can choose either a set of repositories builds or release bundles, in case you’re using distribution. Let’s look at selecting repositories. I can select from the list of available repositories, and I can also define, exclude, or include sub path in this repository.
Once I’m choosing the scope, I’m getting new advanced filter section, and I can narrow down my results in a better way. I can filter by vulnerable component, which is the component that the vulnerabilities were actually detected on. I can filter by the impacted artifact. I can filter by a certain CVE if I’m looking for one, or an issue ID if I know the issue ID in Xray. I can filter to see the reports of only maybe the high vulnerabilities, or medium, or from a certain score range. Let’s say eight to 10 CVSS score. I can filter a range of time of the published date of the vulnerabilities if I’m interested, for example, only on new vulnerabilities that were published in the last period. I can filter by the scan date of the artifacts or the scan date of my builds, and I can choose to see all the vulnerabilities, or maybe only those who have a fix, or maybe to look for those who doesn’t have it fixed.
Let’s generate the report. Once I’m clicking the generate, the reports will start running. I will see the progress. I will see how many rows were generated to my report. I can either just click on the report and see the UI representation of the report. You can see here part of the information, whatever, can fit in the UI, but you can also click on “show more” and see more information. Almost any information that we have on those vulnerabilities in your scope, you can see here. The scores, the references, the description, provider, and many, many more.
You can see here a nice representation of your score. The score actually is calculated from many vectors. So you can see here how it’s being divided to the vectors, both the CVSS two and three. You can see, of course, severity, vulnerable component, impacted artifact, path, what is the fixed version of those vulnerabilities when it was published, and more. You can, of course, export the report either to PDF, CSV, and JSON, and you can choose your own name of file. And that’s it.
Moving on to the next report, you can create due diligence report. License due diligence report will take all your component in the scope that you choose and will show you what licenses were detected on those components. This way you can create some kind of an SBOM of your software. Let’s say, license. Demo.
Let’s now look at how I choose build scope. Here I have the available build names, but I can also choose to use patterns. If I know that all my builds start with, let’s say, “Xray-” or any other prefix or any type of pattern, I will choose now by name. Sorry, I’ll take this one. And I can choose either to run the report only on my latest build, which makes sense that this is what I will want to do, but maybe on several last versions of the build, maybe five last versions or 10. Whatever you want to choose.
And then I have the advanced filter of this report. I can choose either to narrow it down to a list of licenses that I’m interested in, artifact like we had before, the scan time, and I can also choose to filter by components that license were not found on, which is “unknown licenses”, and maybe licenses that we detected, but are not recognized in our license management list in Xray. So this is two more filters that might be interesting filters.
Let’s just generate the report. Again, the report starts to run. I can see that progress, and this one have 2,363 rows. From here again, I can view it. I see the details. The details will show me, because from that point on, as we said, it’s a snapshot of that point of time. I can always see, what was my scope, what was my filter, what exactly I defined for this report. I can export, and I can delete it if this is maybe an old report that I’m no longer interested in.
This is how the license report look like. I see the license name. I see what component it was detected on, what artifact is impacted by it, which here it’s the build that I chose. It can be a list of builds, of course. And the license references. And here I have whether it is a recognized or unrecognized license. I can find maybe unknown components with unknown license. Those are components that license was not detected on. And if I assigned a custom license to any component, I can see that as well.
Last report is the violation report, which again, I can choose the scope. I will do it really quickly. Here I can choose filters regarding violations. I can choose to see only violations on security, or only violations on licenses, or both. I can filter by policies or watches. I can even define the pattern on a watch. So if I want all the watches of a certain team, and it starts with a certain prefix or something like that, I can try that one. I can, again, filter by component or impacted artifact. And then I have here the filters divided by the type of violations, so I can choose how I want to filter the security violation and how I want to filter the license violations. Again, those are the same as the filters that we had in each one of those reports.
Let’s say I want just the eight to 10 and any license, that I will generate a report. Okay. This is how the violation report looks like. When looking at the security violation, I still have all the security information, and let’s sort it by license violations. So in that case, I will see what license failed this policy, what severity did this violation get, on what artifact, and so on.
One kast thing regarding the reports. In our last release, we also added impact path, which is in case a certain violation was created from different components or from component that appear in different path of the… Let’s say it’s a Docker image, and you have the same component in several locations in that Docker image. Then you will see all the different impact path of that vulnerable component, or the component with the license that is not allowed, so you can go to each one of those location and fix it. This is available in the export format and in the API.
I will stop my screen share and let’s move on to the ignore rules.
Okay. What are ignore rules, before I describe the feature? An ignore rule is a way to whitelist or accept a certain violation that was already created. It can be approved by maybe the security persona or the legal persona in your organization, or maybe by the development team.
It can be from several reasons. Let’s say you have a vulnerability, which is real, but in your environment, you found a way to protect against this vulnerability, so you can just ignore this violation. Maybe the conditions of your environment or software don’t meet the conditions that this vulnerability actually happens. Maybe it’s a vulnerability which is valid, but it’s not a showstopper, and I’m going to handle it in the future, maybe in the few weeks. For now, I don’t want it to fail my build or to block my downloads, which is what some of the actions that our policy allows. It might be that I have enough SLA to fix this and I have three weeks, so I want to ignore it, but just for a period of time, and once this time is exceeded, I want to get this violation again.
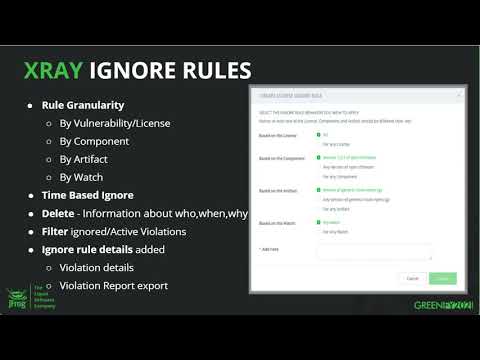
So from all that reasons, we have the ignore rule feature, and our customers requested a better granularity to define this ignore rule. In the past, you could only ignore a security violation on a certain vulnerability in a level of a watch or on a certain license, regardless on what component it was found, license in the level of a watch. That was not flexible at all, because let’s say you know that you can whitelist a certain component with this GPL license, but other components you want to know about. You want violations to be created. You need to know. You need to alert about it. So if you are ignoring the GPL, but not just on this specific component, but on all your watch, then it’s not enough. You’re losing your control over your compliant. So for that, we added a better granularity.
Now you can define your rule almost on any criteria that you can think of. You can choose either to ignore it by a certain vulnerability, or a certain license that the violation was actually created on, or on any of them, and then just create the ignore rule on the component or artifact level.
You can choose to ignore it only on the specific component in that specific version that it was found on, or maybe you want to ignore it on any version that you will ever get of this component. Let’s say now you found a vulnerability on a certain component in version 107, but it’ll not be fixed until 2.X. So you don’t want for every version new version of this component that you will use for this violation to be created over and over again. You can say, “Okay, for any version of this component, I don’t want this vulnerability to be trigger a violation.”
Or you can choose any component at all. In my system, I know that I can handle this vulnerability, so please don’t alert on any component with this vulnerability or license. I can also choose to do it on any version of artifact or any artifact at all, and this can also be defined on builds.
The last scope is either to ignore it only in the scope of that watch that created this violation, or maybe to extend it to any watch, which means on all my organization, all my system. I will have to define a reason why I’m ignoring it. And with that new ignore rule granularity, we also started saving the ignored violations so you can view them. You can filter and see what is ignored, what is active. You can see them in the reports that I showed you before. And you can see all the information about who ignored it, when, why, and even if an ignore rule was deleted, this is also being audited and being saved to see who deleted it, when, and why.
The last thing that we added is time-based ignore, which gives you the option to ignore it, but not permanently. You can define a point of time, let’s say in three weeks from now, and once this time is being exceeded, any artifact that will be scanned from that point on will start creating the violation again. So the whitelist will be over after a period of time.
Let’s see it in demo. Okay, perfect. Let’s say I’m looking now on… Just a second. Okay. I’m looking at an NPM build on Xray data tab on violations. So I can see the list of violations. I have here both licensed and security violations. I can see here already one ignored violation. Let’s see; how am I ignoring a licensed violation? You see here, I have a new icon in the end of a violation row. It’s an “ignored violation” icon. When I’m clicking on it, I’m getting this new granularity of defining my rule. I can define it, as we said, by license, by component, by build, or by watch or any watch. It is mandatory to explain why am I ignoring it, so let’s say I have an approval from the legal team. I can also choose to ignore it just for a period of time or just permanently, and create. Once this ignore rule is defined, this violation will no longer be created.
Now let’s look at a security ignore. So now it will be based on vulnerability or any vulnerability. And again, all those other scopes as before.
Now, once I have the ignore violations, I can filter by the ignored ones. I can see the ignored, and let’s click on one of them. You can see all the details about the violation, but also new details about the ignore rule that caused this violation to be ignored. I can see here who created this ignore rule, when, what was the reason, and what was the scope?
Okay. One last note. I will stop sharing my screen. This is, of course, everything I showed you is available through the APIs, and the ignore information and the ignore filter are available also in the reports, which is very important to know. And that’s it.
Let’s move on to our last feature, which is multiple license permissive approach. Sometimes we have components that have dual or even multiple licenses, and those licenses can be a mix of a more permissive and more restrictive license. It can be maybe MIT together with GPL. So in the past, the Xray policy was always going with the more restrictive approach, and if I defined a policy rule that doesn’t allow, let’s say, GPL, a component with GPL and MIT was always creating a violation because one of the licenses is not allowed.
We got a request from many customers that made us realize that most of the times, organizations would want to go with the more permissive approach. So if I have a choice between two available licenses, I will probably go with the permissive one, and those violations that were created just caused the need to ignore it because I have another license which is allowed, and so on.
So we created a new criteria in our license policy rules which allows you to choose the permissive approach. You can see here in the screenshot, it’s just another checkbox. Here, I can choose the list of my allowed licenses, or I can choose the list of the banned licenses. But when I choose this multiple license permissive approach, if at least one of those multiple licenses detected on a component is allowed, the component will go through without triggering a violation, and it will go through because it has at least one allowed license. This, of course, will reduce the need to ignore violations on multiple licenses component and will be much more accurate to your use cases. It is also available through the APIs. And that’s it, actually.
I hope that those are some good news about Xray. Of course, we have many, many other features. You are welcome to the look at our documentation and release notes. Without further ado, I’m handing over to my colleague, Ben, to talk about JFrog Artifactory and new features. Thank you.
Thank you, Dganit. Hi, everyone. Thank you for joining this webinar or watching. I’m Ben. I’m a product manager in Artifactory team, and today I plan to share with you a lot of valuable information about latest new packages, types, support, and important improvements that we also released lately. But before I start with the juicy part, I wanted to take advantage of one minute of this opportunity as a product manager to share with you what leads us when we build our road map; when we do everything, especially when we are releasing new technologies.
For those who might know Artifactory for a while, so since probably its founding and until today, we always walk with the same mindset and the same North Star. And it is to stay relevant and to stay the best tool that helps developers and dev teams, DevOps engineers and teams, to automate and simplify their DevOps pipeline.
With that, I want to go with you over our latest releases of new package types and important enhancements that we made in some supported ones that we already have today.
I’m going to start with the new technologies. Very excited to announce on those: OCI and Alpine. Then I will briefly touch in some improvements we made in Helm V3 and RubyGems repositories, that of course, for a long while already supported. Lastly, I will touch briefly on the latest Docker changes, with regards to the new rate limits, how does it meet JFrog’s platform, and what we did in order to make sure our customers know and are able to use Artifactory best with it and in light of those changes.
I’ll start with a short description of Alpine for those who don’t know it as a technology. Alpine is a very lightweight Linux distribution. Most of you probably using it as a base layer for Docker images and for some other similar use cases. Artifactory now supports hosting of private packages and proxying them from remote resources as well. Of course, we already released the virtual repository with that to help you aggregate all of those self-hosted packages and to proxy those third-party applications, third party packages, that you want to fetch in order to build your project.
Without further ado, I want to jump to short demo, and to show you how I’m going to use Alpine as a new repository in Artifactory. Give it one more second for the screen to be shared. Okay.
Alpine is honestly very, very similar to the use of Debian APT commands most of you are probably familiar with, so I’m going to cover the basic flows with Artifactory and with Alpine client using Artifactory. Yeah.
I’m starting with creating the three repositories of Alpine. As you can see, we added the repository in the “create repositories” screen. I’m using the quick “set me up” in order to create those three together: the local, the remote, and the feature repository. Going to the tree browser, I’m filtering out the Alpine repositories to make it easier to see. Right now I’m running on it pretty fast. As you can see, the remote repository already created with the needed branches and architectures that are part of the usage of Alpine, and as you can find it in the Alpine org, the known public registry.
Moving on. Going to the virtual repository. “Set me up”. I’m entering my credentials in order to use them embedded inside the commands. Will help me easily to copy from the “set me up” section and to use it in the terminal. Taking the command, going to a simple Linux container I use to run the Alpine client.
Running the first command to just connect my client with my Artifactory instance. I’m going to the repositories list in the client and tagging out those two default repositories to make sure I’m using Artifactory for the next flows. I’m running now APK update that will help me to make sure I’m using the client with everything I need, and again, configuring and fetching with the configured repository an Alpine package.
As you can see, I just ran an APK add cURL with the “allow untrusted” flag. Of course, just the flow that I needed to go over, to use the cURL for the next steps. The “allow untrusted” flag is an important part. I want to touch it a bit later.
I’m going back to the “set me up” section. As you saw before, I used the untrusted method, which means I’m not using right now RSA keys to sign my index file. You can see it also in the “set me up” section that we are explicitly saying that there is no RSA key pair defined for this specific repository. I’m going for a deploy flow. Taking the command, going back to the client.
Yeah. Running the same command.
Now I’m pushing the APK package I just fetched from Alpine Linux to my Artifactory instance. I get the full information from the terminal. Everything looks good. Going to the Alpine local, and I can find over here, the APK just pushed Artifactory. Everything is included, of course. The package already indexed. The properties are included as well and listed as part of the package metadata. Yeah. And that’s about it from this part.
Now I’m going back to my Artifactory instance. I’m running another update with the “allow untrusted” flag, and I’m fetching, again, an APK package from Artifactory.
Now you can see that I just fetched the exact package I used before. You can see in the downloads count that it jumped to one, which helps me to understand that I did this process successfully and I used the package that I wanted. I think that’s it with that specific flow.
I want to jump quickly to the next one and to speak a bit about RSA signing. We added some new capabilities in Artifactory in order to house multiple RSA keys and to help you guys to sign your indexes if you want to use the packages in sign method. Again, I’m using the same local repository we just created in the previous flow. You can see, again, the same package. It’s right now unsigned, of course, without any RSA key. Entering my credentials, copying the command, going back to the terminal.
Running, again, against my client. Going to the repositories list. Making sure the repositories that I don’t want to use right now are tagged out as we wanted. Artifactory is there. It’s great. And I’m running an APK update once again. You can see over here the untrusted signature, which helps me to understand that I’m still in an unsigned mode.
Over here, you can see the comment that I just mentioned a minute ago, to make sure you know that you are using right now an unsigned repository, and the index is unsigned, and you’re not using any of your RSA keys.
So I’m going to the Artifactory administration, and for a new section, we added in the security section that these RSA key pairs. I’m going to the new screen of adding new RSA keys. As you can see, you can use all the fields to push and to add multiple RSA keys if you would like. Of course, the private section and the public key. Then I add the alias and the key pair name, that are mandatory, of course. The passphrase is just if your company organization is using those.
Okay, we added the RSA key. I’m going back to the repository and I’m linking the local repository. Then we created RSA key. I’m saving those two together. Now I’m going back to the tree browser to make sure that I signed the repository as I wanted. As you can see, the index file is already signed with the RSA public key, and right now, I can make each command using the “set me up” in a sign method that is correlated with the private key that is existed in my client. Right now, you can see also the comment in the “set me up” change that helps you to understand that you’re using right now a repository that is signed with an RSA key pair.
Running the command to configure first the repository, and you can see the same flow right now of fetching an APK package in a sign method. The unsigned signature is not here anymore. That’s it from this specific flow.
The result is the same command. After associating the RSA key pair with the local repository, I know that I can run the other way and to be sure that I’m using a sign method of fetching or deploying APK packages.
Before moving to the next one, I want just to make sure if you know. Drop some questions in the QA section. If you have some, we will take those in the end of the session.
I’m jumping right to the next subject that is OCI. Very, very happy to announce on it. Right now, Artifactory is officially an OCI registry. We have added support for OCI images in our Docker repository, which means you can push your own OCI images, pull from other registries, and cache them to your Docker repository.
For those who haven’t heard yet on OCI, although I know most of you are probably familiar with it, it’s a community-based project that came to improve the runtime of containers that have different implementations and needs, and it simply came to standardize the format of container images, container image formats, and runtimes. Your OCI image can hold whatever you need and would like. It can be in Helm Chart, it can be a Docker image, and even customize an object. Every resource that it means something to save by layers, you can do it by the new format of OCI images, and now you can host it also in Artifactory.
Clients, we added support, of course, for all clients that are aligned with the OCI spec; for example, Podman, ORAS, containerd, Docker, and so on. We also chose to add Podman to the “set me up section” – I will show you in a second – because it’s one of the most common used today, and we plan to add more in the future. Depends on our customers’ and users’ voices.
I’m moving again to show you a quick demo of a usage of OCI with my Artifactory instance. Again, I’m using a Linux container to run my client. It’s a Podman, as I mentioned. A simple command of a pull for random image. I’m taking Alpine for this sake of the demo. Next I’m going to tag the Alpine package that I just fetched to my Linux container, and I will tag it with the full flow of the repository, as we know and we do for Docker images. Then I’m going to first log in to my instance, and then push the same image that I just tagged to my local repository. Those are my credentials. Logging in.
Okay. I’m running the push command for this specific tagged image. Not found. Oh, of course. I need to make sure I have the repository. Just wanted to use and to mention. I’m going back now to my Artifactory instance. I’m creating the repository. Local. It’s a Docker one. I will name it for the demo. No other configurations required. Okay.
Going back to the terminal, running the same command of the push of the tag, the Alpine package image, and I’m going back to the UI to make sure it’s there.
Going to tree browser, filtering out Docker. It’ll be much easier to see it over here like that. As you can see, the image is already here with the new symbol of the OCI images. You can see the manifest.JSON. That is part of the image, of course. The layers under it. All of the needed information of the image that indexed already. Can see the layers of the image.
Also, from the package view, it’s easy to search for this new image I just pushed. I will search by type. OCI. That is new. And here it is: the Alpine image that I just pushed to my local repository. And can go back to see some builds associated with it, Xray data if I have some. It’s connected with the previous demo that we had. And that’s about it.
I want to share a few more items from the tree browser, so I’m going back to the same local repository, and if I will search for the specific local, I can find the Alpine image. I’m going to the manifest.JSON, and to make sure I pushed it correctly with the right schema and OCI, the metatype is aligned. You can see the layers beneath it.
I think that’s about it about OCI. So with the short time we had left, I’m switching back and going to speak about some interesting enhancements and improvements we have made with current supported repositories.
The first one is around RubyGems. After getting several requests from our customers that support for an additional support for Bundler clients, we added a new index. We actually rewrite the index of the RubyGems repositories, the three of them, of course: remote, local, and virtual; and to support compact index for all three repositories. Providing you with the latest versions of packages that is compatible, which your installed Ruby version of your package, and the project. And this type of usage done by, of course, the known Bundler client that was supported already in Artifactory before, but right now, we added the support also for compact index as well.
Next, I’m going to briefly touch on latest improvements we did with Helm. We added support for Helm V3, Helm 3 formats. Helm 3 is, of course, the API version V2. A bit confusing. Chart that was introduced in our 711 release, all of Artifactory in JFrog platform. The main change was that the dependencies was extracted now from the Chart.yaml, and for the V2 instead, it was hosted in the requirements.yaml for Helm V1 one charts. We also added new fields to the index.yaml; for example, dependencies, annotations, types, cube version. We also added some AQL searchable properties to help you use them as well. We added annotation and type and API version. For the full field and list, please visit the wiki. It’s all there.
I will jump right into the next topic, that is probably the most interesting in this part of improvements. It’s, of course, the latest announcement of Docker that a lot of you are using, and I just want to give some context before moving on to the changes we did in Artifactory and the changes we did for our cloud users.
We just announced a big move and partnered with Docker that exempts cloud users of the JFrog DevOps platform from this Docker hubs image pool limits. Some context: last year, Docker announced a new consumption-based limits on containing images pulled from Docker Hub. Specifically, anonymous users are limited to 100 pulls per six hours, and authenticated users are limited to 200 pulls per six hours.
We wanted to go farther and to remove any friction our customers could encounter in these flow and as part of their production environments and development pipeline, so we announced that our cloud users – those are that latest tellers from the most important sites – our cloud users will not be affected at all, even those who are using the free subscription offered on all cloud providers, which means if you’re using the cloud installation, you don’t need to worry at all about those new pull limits. You don’t need to be authenticated, and we will set it up for you to make sure you’re using and you can fetch as many images you want in any timeframe.
At a very high level, it means that it lowers your organization risk by giving you an access [inaudible 00:52:54] to the Docker Hub images that you need, and to prevent interruptions in your build and production environments.
We also did some changes, technical changes, in Artifactory itself to make sure our own prime users are not affected as they should be. So we introduced several new features. The first one is the usage of HEAD request. Before that, Artifactory didn’t use at all HEAD request, and we routed all requests as a get request. In light of those changes, we wanted to make sure that you are using your get request wisely and properly. So right now, you can use Docker Hub through Artifactory, and not to worry about any unnecessary get requests sent from your instance to Docker Hub.
This second thing with it is to increase the default retrieval cache period that is configured automatically in a remote repository created that is pointing Docker Hub, of course. We did anything in order to make sure that you are not going to fetch and to request some unnecessary get request that will be counted as get request from your own private capacity.
We already, in the last three versions, added some new logging and messaging that helps you to monitor and to understand each new response from Docker Hub or from Docker client to make it broader and easier to understand why are you failing, and maybe you reach to the specific limit you are using right now.
Lastly, we added new use of Digest Header that called the Docker content Digest, which represent the manifest.JSON body digest and compare the two: the remote and the cached manifest.JSON using the SHA value of the other. With that, we can defer those two and to make sure we are sending a get request only when some change has occurred on the other side, to help you use Docker Hub properly.
Wow, that was fast. Now we can use the three more minutes we have for some questions if you have some. You can drop it via the Q&A. We’ll take them now. And of course, if we don’t have any time left, so we will, of course, reply via email to all of you guys. Personally, I want to say thank you, not only for being here; also for using our products and giving this incredible continuous feedback. It helps us to know what is important, what is our next moves, and thank you for that. Thank you for being here.