Highly Available PostgreSQL Cluster using Patroni and HAProxy
By Dmitry Romanoff, Tech Lead @JFrog
8月 22, 2022
11 min read

Introduction:
High availability is a vital part of today’s architecture and modern systems. This blog post describes a possible approach to create a highly available PostgreSQL cluster using Patroni and HAProxy. The high availability allows a PostgreSQL DB node to automatically reroute work to another available PostgreSQL DB node in case of a failure. It’s important to note that this blog is not associated with JFrog products, but rather my personal experience.
Description:
This article is a step-by-step guide on how to create a highly available PostgreSQL cluster architecture using Patroni and HAProxy.
Patroni is an open-source python package that manages Postgres configuration. It can be configured to handle tasks like replication, backups, and restorations.
Etcd is a fault-tolerant, distributed key-value store used to store the state of the Postgres cluster. Using Patroni, all of the Postgres nodes make use of etcd to keep the Postgres cluster up and running. In production, it makes sense to use a larger etcd cluster so that if one etcd node fails, it doesn’t affect Postgres servers.
With the Postgres cluster set up, we need a method to connect to the master regardless of which of the servers in the cluster is the master. This is where HAProxy steps in. All Postgres clients/applications will connect to the HAProxy which will provide a connection to the master node in the cluster.
HAProxy is an open-source, high-performance load balancer and reverse proxy for TCP and HTTP applications. HAProxy can be used to distribute loads and improve the performance of websites and applications.
Schema:

Architecture:
OS: Ubuntu 20.04
Postgres version: 12
Machine: node1 IP: <node1_ip> Role: Postgresql, Patroni
Machine: node2 IP: <node2_ip> Role: Postgresql, Patroni
Machine: node3 IP: <node3_ip> Role: Postgresql, Patroni
Machine: etcdnode IP: <etcdnode_ip> Role: etcd
Machine: haproxynode IP: <haproxynode_ip> Role: HA Proxy
Step-by-step instructions guide
Step 1 – Setup node1, node2, node3:
sudo apt update
sudo hostnamectl set-hostname nodeN
sudo apt install net-tools
sudo apt install postgresql postgresql-server-dev-12
sudo systemctl stop postgresql
sudo ln -s /usr/lib/postgresql/12/bin/* /usr/sbin/
sudo apt -y install python python3-pip
sudo apt install python3-testresources
sudo pip3 install --upgrade setuptools
sudo pip3 install psycopg2
sudo pip3 install patroni
sudo pip3 install python-etcd
Step 2 – Setup etcdnode:
sudo apt update
sudo hostnamectl set-hostname etcdnode
sudo apt install net-tools
sudo apt -y install etcd
Step 3 – Setup haproxynode:
sudo apt update
sudo hostnamectl set-hostname haproxynode
sudo apt install net-tools
sudo apt -y install haproxy
Step 4 – Configure etcd on the etcdnode:
sudo vi /etc/default/etcd
ETCD_LISTEN_PEER_URLS="http://<etcdnode_ip>:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://<etcdnode_ip>:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://<etcdnode_ip>:2380"
ETCD_INITIAL_CLUSTER="default=http://<etcdnode_ip>:2380,"
ETCD_ADVERTISE_CLIENT_URLS="http://<etcdnode_ip>:2379"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
sudo systemctl restart etcd
sudo systemctl status etcd
curl http://<etcdnode_ip>:2380/members
Step 5 – Configure Patroni on the node1, on the node2 and on the node3:
sudo vi /etc/patroni.yml
scope: postgres
namespace: /db/
name: node1
restapi:
listen: <nodeN_ip>:8008
connect_address: <nodeN_ip>:8008
etcd:
host: <etcdnode_ip>:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator <node1_ip>/0 md5
- host replication replicator <node2_ip>/0 md5
- host replication replicator <node3_ip>/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: <nodeN_ip>:5432
connect_address: <nodeN_ip>:5432
data_dir: /data/patroni
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: ************
superuser:
username: postgres
password: ************
parameters:
unix_socket_directories: '.'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
sudo mkdir -p /data/patroni
sudo chown postgres:postgres /data/patroni
sudo chmod 700 /data/patroni
sudo vi /etc/systemd/system/patroni.service
[Unit]
Description=High availability PostgreSQL Cluster
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /etc/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=multi-user.targ
Step 6 – Start Patroni service on the node1, on the node2 and on the node3:
sudo systemctl start patroni
sudo systemctl status patroni
dmi@node1:~$ sudo systemctl status patroni ● patroni.service - High availability PostgreSQL Cluster Loaded: loaded (/etc/systemd/system/patroni.service; disabled; vendor preset: enabled) Active: active (running) since Tue 2022-06-28 06:20:08 EDT; 24min ago Main PID: 3430 (patroni) Tasks: 13 (limit: 2319) Memory: 95.9M CGroup: /system.slice/patroni.service ├─3430 /usr/bin/python3 /usr/local/bin/patroni /etc/patroni.yml ├─4189 postgres -D /data/patroni --config-file=/data/patroni/postgresql.conf --listen_addresses=192.168.1.139 --port=5432 --cluster_name=postgres --wal_level=replica --h> ├─4197 postgres: postgres: checkpointer ├─4198 postgres: postgres: background writer ├─4199 postgres: postgres: walwriter ├─4200 postgres: postgres: autovacuum launcher ├─4201 postgres: postgres: stats collector ├─4202 postgres: postgres: logical replication launcher └─4204 postgres: postgres: postgres postgres 192.168.1.139(50256) idle Jun 28 06:43:46 node1 patroni[3430]: 2022-06-28 06:43:46,405 INFO: Lock owner: node1; I am node1 Jun 28 06:43:46 node1 patroni[3430]: 2022-06-28 06:43:46,410 INFO: no action. i am the leader with the lock Jun 28 06:43:56 node1 patroni[3430]: 2022-06-28 06:43:56,450 INFO: Lock owner: node1; I am node1 Jun 28 06:43:56 node1 patroni[3430]: 2022-06-28 06:43:56,455 INFO: no action. i am the leader with the lock Jun 28 06:44:06 node1 patroni[3430]: 2022-06-28 06:44:06,409 INFO: Lock owner: node1; I am node1 Jun 28 06:44:06 node1 patroni[3430]: 2022-06-28 06:44:06,414 INFO: no action. i am the leader with the lock Jun 28 06:44:16 node1 patroni[3430]: 2022-06-28 06:44:16,404 INFO: Lock owner: node1; I am node1 Jun 28 06:44:16 node1 patroni[3430]: 2022-06-28 06:44:16,407 INFO: no action. i am the leader with the lock Jun 28 06:44:26 node1 patroni[3430]: 2022-06-28 06:44:26,404 INFO: Lock owner: node1; I am node1 Jun 28 06:44:26 node1 patroni[3430]: 2022-06-28 06:44:26,408 INFO: no action. i am the leader with the lock
Step 7 – Configuring HA Proxy on the node haproxynode:
sudo vi /etc/haproxy/haproxy.cfg
Replace its context with this:
global
maxconn 100
log 127.0.0.1 local2
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen postgres
bind *:5000
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server node1 <node1_ip>:5432 maxconn 100 check port 8008
server node2 <node2_ip>:5432 maxconn 100 check port 8008
server node3 <node3_ip>:5432 maxconn 100 check port 8008
sudo systemctl restart haproxy
sudo systemctl status haproxy
● haproxy.service - HAProxy Load Balancer Loaded: loaded (/lib/systemd/system/haproxy.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2022-06-28 06:54:22 EDT; 7s ago Docs: man:haproxy(1) file:/usr/share/doc/haproxy/configuration.txt.gz Process: 1736 ExecStartPre=/usr/sbin/haproxy -f $CONFIG -c -q $EXTRAOPTS (code=exited,status=0/SUCCESS) Main PID: 1751 (haproxy) Tasks: 3 (limit: 2319) Memory: 2.1M CGroup: /system.slice/haproxy.service ├─1751 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock └─1753 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock Jun 28 06:54:22 haproxynode systemd[1]: Starting HAProxy Load Balancer... Jun 28 06:54:22 haproxynode haproxy[1751]: [NOTICE] 254/065422 (1751) : New worker #1 (1753) forked Jun 28 06:54:22 haproxynode systemd[1]: Started HAProxy Load Balancer. Jun 28 06:54:23 haproxynode haproxy[1753]: [WARNING] 254/065423 (1753) : Server postgres/node2 is DOWN, reason: Layer7 wrong status, code: 503, info: "HTTP status check returned code <3C>503<3E>"> Jun 28 06:54:24 haproxynode haproxy[1753]: [WARNING] 254/065424 (1753) : Server postgres/node3 is DOWN, reason: Layer7 wrong status, code: 503, info: "HTTP status check returned code <3C>503<3E>">
Step 8 – Testing High Availability Cluster Setup of PostgreSQL:
http://<haproxynode_ip>:7000/>
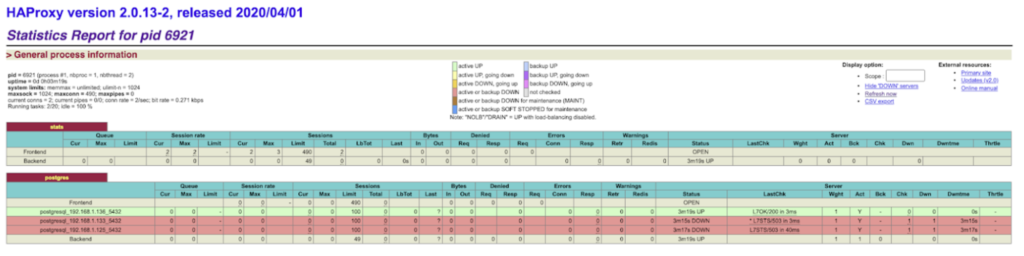
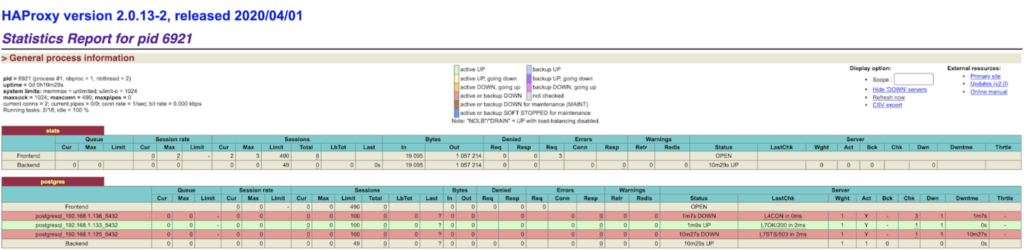
Simulate node1 crash:
sudo systemctl stop patroni
In this case, the second Postgres server is promoted to master.
Step 9 – Connect Postgres clients to the HAProxy IP address:
psql -h <haproxynode_ip> -p 5000 -U postgres
dmi@dmi-mac ~ % psql -h 192.168.1.115 -p 5000 -U postgres
Password for user postgres:
psql (12.4)
Type "help" for help.
postgres=#
dmi@dmi-mac ~ % psql -h 192.168.1.115 -p 5000 -U some_db
Password for user some_user:
psql (12.4)
Type "help" for help.
some_db=>
dmi@node1:~$ patronictl -c /etc/patroni.yml list
+ Cluster: postgres (6871178537652191317) ---+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+--------+---------------+---------+---------+----+-----------+
| node1 | 192.168.1.139 | Replica | running | 2 | 0 |
| node2 | 192.168.1.110 | Leader | running | 2 | |
| node3 | 192.168.1.146 | Replica | running | 2 | 0 |
+--------+---------------+---------+---------+----+-----------+
dmi@node1:~$
Step 10 – Failover test:
On one of the nodes run:
sudo systemctl stop patroni
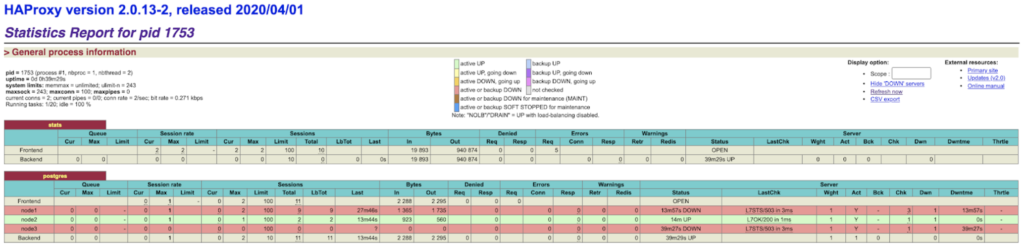
Summary:
In this post, it was demonstrated how to deploy a high available PostgreSQL Cluster using Patroni and HAProxy. It examined the highly available PostgreSQL Cluster setup, connecting the PostgreSQL client to the HAProxy IP address, and failover was tested. The key concept can be easily applied to a bigger number of nodes in the PostgreSQL Cluster. An additional possible step to improve the availability of the system is to add nodes to the etcd and to add an HAProxy server for IP failover.



