Understanding Shift to Custom Kubernetes Resources with Oum Kale @ Cloud Native London
6月 8, 2023
2 min read
Understanding Shift To Custom Kubernetes Resources (Kale Oum Nivrathi, JFrog)
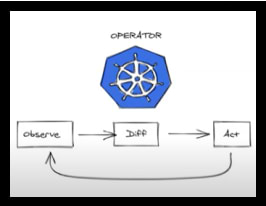
In the era of containerization and orchestration, Kubernetes is highly brisking. The future of the orchestration platforms will be Custom Resources Definitions (CRD) and APIs. Whereas writing k8s operator is the best way of extending APIs for our application, Operators are clients of the Kubernetes API that act as controllers for a Custom Resource. Operator lets us extend the functionality of the Kubernetes API, enabling it to configure, create, and manage instances of applications automatically using a structured process. In this talk, we will take a deep dive into the capabilities of Kubernetes controllers, and lifecycle management, including backup, recovery, and automatic configuration tuning. We will also explore the uses of Kubernetes Operator Writing Controller logic and its unique way to manage application deployments as a use case.
Linting Rego with Rego! Introducing Regal the Rego linter (Anders Eknert, Styra)
With origins in logic programming and Datalog, Rego is a powerful language for asking queries on structured data, such as that commonly represented as JSON or YAML. Logic programming is however an unfamiliar domain for most developers, and learning both a new domain and a new language requires good resources for learning. While documentation and style guides are great, what if we could automate parts of the learning process? In this first-ever talk, Anders will introduce you to Regal — a new (and first!) linter for Rego, with the goal of providing “guardrails for your guardrails” — i.e. your Rego policies, as well as to be a learning tool for people new to the language. What’s more, Regal itself is written mostly in Rego!
Platform engineering in cloud repatriation era (Bartek Antoniak, VirtusLab)
This presentation delves into the journey from infrastructure baseline via developer community to its current state of platform engineering.It highlights the advantages of platform engineering over the do-it-yourself approach and how enabling teams can seamlessly integrate with platform engineering.The second part of the presentation focuses on the measures how we assist application teams in public cloud and how platform engineering can be effectively implemented in the cloud repatriation era.Finally, we’ll explore the relevance of public cloud and the current trends among technology organisations. By providing a comprehensive overview, this as a whole should make the question: “Where do we go from here?” much easier to answer.
Speakers



Oum Kale