Turns out 78% of reported common CVEs on top DockerHub images are not really exploitable
JFrog Advanced Security series - Contextual Analysis


By
15 min read

Research motivations
Similarly to our previous research on “Secrets Detection,” during the development and testing of JFrog Xray’s new “Contextual Analysis” feature, we wanted to test our detection in a large-scale real-world use case, both for eliminating bugs and testing the real-world viability of our current solution.
However, unlike the surprising results we got in our Secrets Detection research (which were – much more active tokens than we bargained for), in this case, the results were in line with what we were seeing as security engineers for many years now. Namely – when the metric for a vulnerable system is simply “package X is installed,” – we expect the vast majority of security alerts to be false positives.
In this post we will detail our research methodology and findings and offer some advice for developers and security professionals looking to reduce the amount of CVE false positives.
Actually exploitable vs. “vulnerable package is installed”
Before diving in, let’s briefly look at some example vulnerabilities to understand cases where a CVE report could be considered a false positive, even when a vulnerable component exists.
This is not an exhaustive list by any means, but it does cover the most prominent instigators of CVE false positives –
Library Vulnerabilities

Does the fact that a vulnerable version of Lodash is installed guarantee a vulnerable system?
No! By definition, we cannot determine whether a CVE in a library is exploitable simply by noting that the library is installed. This is because a library is not a runnable entity; there must be some other code in the system that uses the library in a vulnerable manner.
In the example above, even if Lodash is installed, the system may not be vulnerable. There must be some code that calls the vulnerable function, in this case, template(), from the vulnerable Lodash library. In most cases, there are even additional requirements, such that one of the arguments passed to template() would be attacker-controlled.
Other code-related prerequisites may include –
- Whether a mitigating function is called before the vulnerable function
- Whether specific arguments of the vulnerable function are set to specific vulnerable values
Service configuration

Does the fact that a vulnerable version of Cassandra is installed, guarantee a vulnerable system?
No! In most modern service vulnerabilities (especially ones with severe impact) the vulnerability only manifests in non-default configurations of the service. This is due to the fact that the default and sane configuration is often tested the most, either by the developers themselves or simply by the real-world users of the service.
In the example above, to achieve RCE the Cassandra service has to be configured with three non-default configuration flags (one of them being quite rare).
Other configuration-related prerequisites may include –
- Whether the component is being run with specific command line arguments or environment variables
- Whether the vulnerable component was compiled with specific build flags
Running environment

Does the fact that a vulnerable version of Apache Hadoop is installed, guarantee a vulnerable system?
No! In the example above, the vulnerability only manifests in a Microsoft Windows based environment. Therefore if the vulnerable component is installed in a Linux environment, it cannot be exploited.
Other environment-related prerequisites may include –
- Whether the vulnerable component is running in a specific Distribution (ex. Debian)
- Whether the vulnerable component is compiled for a specific architecture? (ex. 32-bit ARM)
- Whether a firewall blocks communication to the vulnerable service
Our research methodology
In this research, we are setting out to find what percentage of vulnerability reports actually indicate that the vulnerability is exploitable, when considering two reporting techniques –
- Naive – The vulnerability is reported whenever a vulnerable component is installed in the relevant (vulnerable) version range. This is how almost all SCA tools work today.
- Context-sensitive – The vulnerability is only reported (or – said to be applicable) if the context of the image indicates vulnerable usage of the component. This takes into account factors that were discussed in the previous section (code prerequisites, configuration prerequisites, running environment)
We are interested in testing the above in common real-world environments, and performing this test on as many environments as possible.
We realized that looking at DockerHub’s top “community” images should satisfy both of these requests, since –
- These images are used extremely frequently. For example the top 25 images currently have more than 1 billion downloads.
- Community images usually contain both an interesting component and the code that uses the component to some end, which provides a realistic context. This is unlike “official” docker images that usually contain standalone components that are left unused and in their default configuration. For example, an Nginx web server by itself with default configuration would probably not be susceptible to any major CVE, but it does not provide a realistic scenario.
From these decisions, our methodology emerged –
- Pull DockerHub’s top 200 community images, in their “latest” tag
- Gather from these images, the top 10 most “popular” CVEs (sorted by CVE occurrence across all images)
- Run our contextual analysis on all 200 images
- Calculate the percentage of the naive method false positive rate, by diving “non applicable occurrences” by “total occurrences” for each of the top 10 CVEs
What were the top 10 popular CVEs?
When scanning DockerHub’s top 200 community images, these are the CVEs that appeared in the highest number of images –
| CVE ID | CVSS | Short Description |
| CVE-2022-37434 | 9.8 | zlib through 1.2.12 has a heap-based buffer over-read or buffer overflow in inflate().
Only applications that call inflateGetHeader are affected. |
| CVE-2022-29458 | 7.1 | ncurses 6.3 has an out-of-bounds read and segmentation violation in convert_strings() |
| CVE-2021-39537 | 8.8 | ncurses through v6.2 nc_captoinfo() has a heap-based buffer overflow |
| CVE-2022-30636 | N/A | Golang x/crypto/acme/autocert: httpTokenCacheKey allows limited directory traversal on Windows |
| CVE-2022-27664 | 7.5 | Golang net/http before 1.18.6 DoS because an HTTP/2 connection can hang |
| CVE-2022-32189 | 7.5 | Golang math/big before 1.17.13 Float.GobDecode and Rat.GobDecode DoS due to panic |
| CVE-2022-28131 | 7.5 | Golang encoding/xml before 1.17.12 Decoder.Skip DoS due to stack exhaustion |
| CVE-2022-30630 | 7.5 | Golang io/fs before 1.17.12 Glob DoS due to uncontrolled recursion |
| CVE-2022-30631 | 7.5 | Golang compress/gzip before 1.17.12 Reader.Read DoS due to uncontrolled recursion |
| CVE-2022-30632 | 7.5 | Golang path/filepath before 1.17.12 Glob DoS due to stack exhaustion |
So – how many CVEs were actually exploitable?
We deliberately chose to run the contextual scanners on their most conservative setting – more on that in the next section.
The contextual scanner for each CVE was defined as follows –
| CVE ID | Contextual Scanner |
| CVE-2022-37434 | Check for 1st-party code that calls “inflateGetHeader” and “inflate” |
| CVE-2022-29458 | Check for invocations of the ncurses “tic” CLI utility |
| CVE-2021-39537 | Check for invocations of the ncurses “captoinfo” CLI utility |
| CVE-2022-30636 | Check for Windows OS + 1st-party code that calls “autocert.NewListener” or references “autocert.DirCache” |
| CVE-2022-27664 | Check for 1st-party code that calls “ListenAndServeTLS” (HTTP/2 is only available over TLS) |
| CVE-2022-32189 | Check for 1st-party code that calls “Rat.GobDecode” or “Float.GobDecode” |
| CVE-2022-28131 | Check for 1st-party code that calls “Decoder.Skip” |
| CVE-2022-30630 | Check for 1st-party code that calls “fs.Glob” with non-constant input |
| CVE-2022-30631 | Check for 1st-party code that calls “gzip.Reader.Read” |
| CVE-2022-30632 | Check for 1st-party code that calls “filepath.Glob” with non-constant input |
Running the contextual scanners on all 200 images gave us the following results, per CVE –
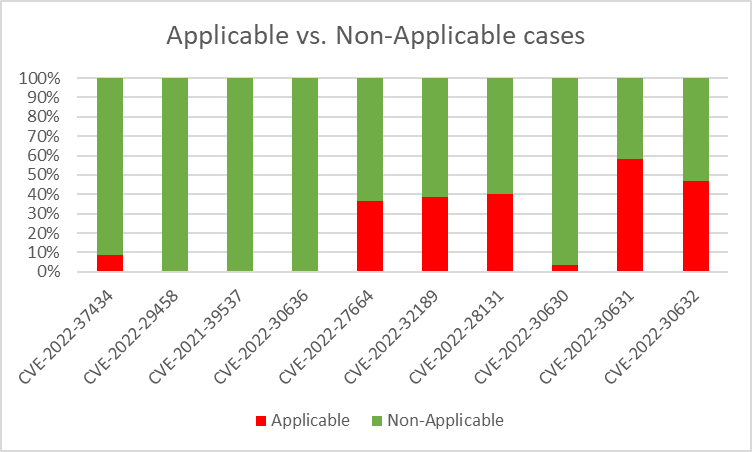
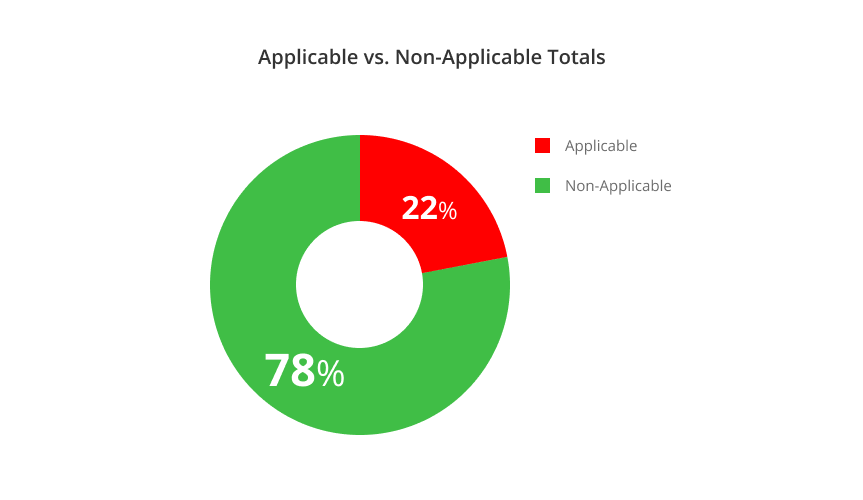
And when tallying the results of all top 10 CVEs together, 78% in CVE cases were found to be non-applicable!
Differentiating between 1st-party and 3rd-party code
The contextual analyzer uses Xray’s SCA capabilities in order to differentiate between 1st-party and 3rd-party code, with a file-level granularity.
We define 1st-party code as the vendor’s own code, meaning the code that was directly written by the vendor that’s running the contextual analyzer (as opposed to 3rd-party OSS code that the vendor uses).
When we are performing contextual analysis on code (as opposed to configuration or environment contextual analysis) we are only interested in looking at how the 1st-party code interacts with 3rd-party components.
For example, for the following CVE in lodash (an npm library), we can see that the file “/project-two/main.js” is making the vulnerable API call –
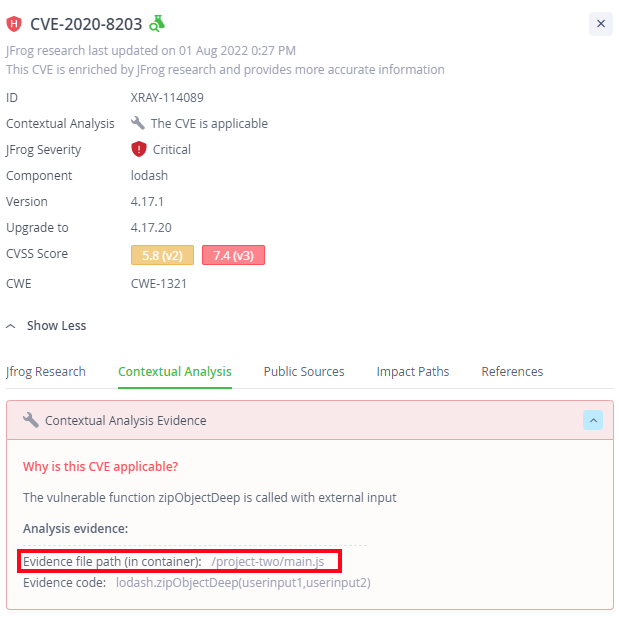
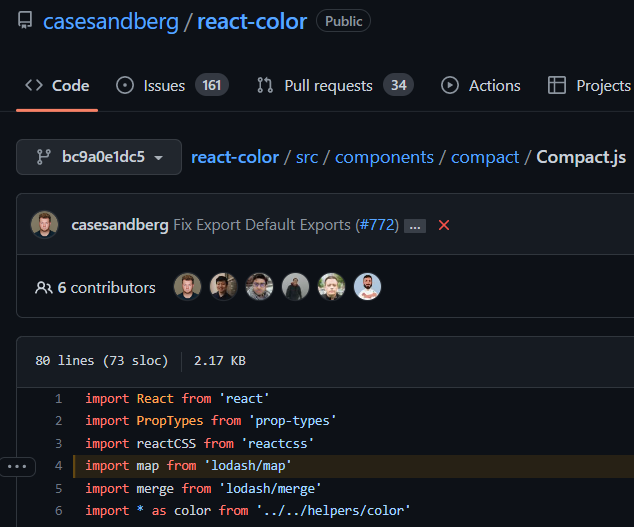
This is a 1st-party file that doesn’t belong to any OSS component, and therefore it was included in the contextual scan. In contrast to this, if the same Docker container would also include the react-color npm package (which depends on lodash), then a file like Compact.js would not have been scanned since it is part of the react-color 3rd-party component (even though the file uses lodash API calls) –
Why are we not scanning the usage of 3rd-party components by 3rd-party components? There are a few reasons –
- Scope – When a popular library or application is vulnerable to a specific issue/CVE, it is up to the maintainer of that library/application to fix the issue and release a new version of the library. This information is stored, for example, in the CPEs list for that CVE. For example, the CPEs for the Log4Shell vulnerability (CVE-2021-44228) which directly affects the Log4j Java library, also contain the following entry for Cisco WebEx:
 It would be redundant for the contextual analyzer to analyze CVE-2021-44228-related API calls on (3rd-party) files related to Cisco Webex, since we already know the vulnerable versions of Cisco Webex via these CPEs.
It would be redundant for the contextual analyzer to analyze CVE-2021-44228-related API calls on (3rd-party) files related to Cisco Webex, since we already know the vulnerable versions of Cisco Webex via these CPEs. - Performance – In almost all modern software projects, the amount of 3rd-party code usually dwarfs the amount of 1st-party code (think of a one-line program that links against the entire C library). Scanning all 3rd-party code would be extremely redundant and would not allow us to achieve our desired artifact scan time
- Licensing – In cases where proprietary 3rd-party components are used (ex. in binary format), the 1st-party vendor may not have the approval to analyze the proprietary 3rd-party component.
Looking at the current limits of contextual analysis
Let’s examine CVE-2022-30631, which had an exceptionally high applicability rate.
The CVE was the only one that crossed 50% applicability. In layman’s terms, the prerequisite for this CVE to be exploitable is “Golang is used to extract an attacker-controlled gzip archive”, in reality – the scanner will alert if 1st-party Golang code tries to extract any gzip archive. This is done since guaranteeing whether a file is attacker-controlled is a very hard task, due to the multitude of possible sources affecting the file. When trying to determine whether a variable comes from constant input or external/attacker-input, this can be achieved for example via data flow analysis (which is performed by some of our scanners, for example CVE-2022-30630 which had a much lower applicability rate) –
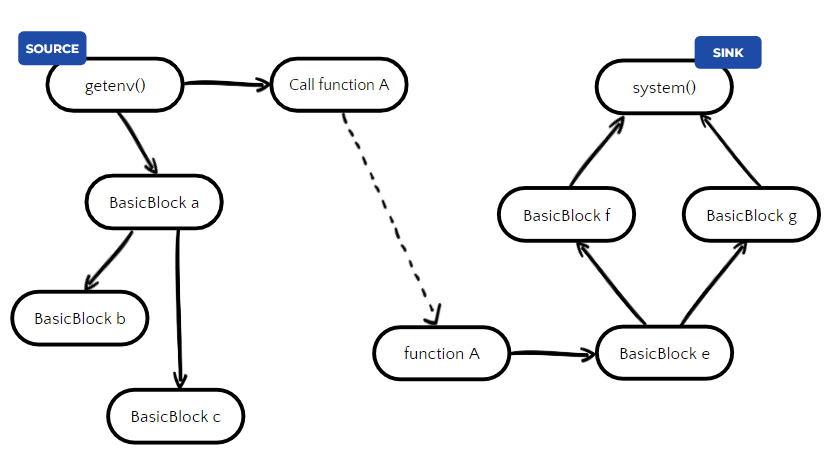
But, when dealing with files, even if the function’s file path argument is constant, there is no guarantee that the file is not attacker-controlled, and vice versa. Therefore, we expect the real-world applicability of this CVE to be even lower.
Why 78% is actually a conservative number
From the example above, we can see that some CVEs may have an exaggerated applicability rate, meaning the real-world applicability may be even lower. It is important to discuss why (in the common case) it still makes sense to run conservative scanners –
Preference towards false positives and not false negatives
Realistically, any technology has its limitations, and this is doubly true when trying to solve computationally-infeasible problems such as “can a certain input be controlled by external sources”. In certain cases, the easier ones, we can make certain assumptions that make the computation of the solution possible with extremely high confidence. However, we surmise that in the harder cases, where 100% confidence is not guaranteed, we should do two things –
- Prefer scanners that tend to show false positives (in our case, show results as applicable when in reality they are not). This is done since in this case, the result will be examined by an engineer and evaluated whether it is really applicable or not. In the opposite case, where the vulnerability would be flagged as “non-applicable”, the engineer will assume it can be ignored, and thus it will be left vulnerable, which is a much more severe scenario.
- Whenever possible, provide the confidence rate and/or the reason for low confidence in a specific finding, so that even applicable results can be prioritized by security/DevOps engineers.
Performance considerations
A contextual scanner that’s based on data-flow-analysis (for example, a scanner that’s trying to determine whether a specific function’s argument is coming from attacker-controlled input or not) will always have an option in its implementation whether to provide more accurate results or to run faster. For example, the most accurate type of contextual scanner must at last –
- Allow for an infinite call depth when trying to build an intra-module data-flow graph between an attacker-controlled source and the requested sink
- Consider inter-module calls when building the data-flow graph
These operations greatly increase the scanner’s runtime.
When dealing with a great amount of scanned artifacts per minute (as may be requested from a JFrog Artifactory/Xray instance) there must be a delicate balance between the accuracy and the speed of the contextual scanner.
Even when considering the discussed limitations, 78% is still a massive number of vulnerabilities that can be either de-prioritized or ignored, and we expect this number to get higher as technology advances and as less “applicable by default” CVEs are discovered.
In 2022 – ignoring the context doesn’t make sense
As time moves on, we are seeing less and less vulnerabilities that are exploitable without any preconditions. Library vulnerabilities will always have a code precondition (someone must use the library in a vulnerable manner) and Daemon vulnerabilities are very unlikely to be exploitable in the default configuration, as that configuration is usually highly audited.
As we can see from our research results, the amount of non-applicable CVEs is simply staggering, even in a common use case and when using conservative, high-accuracy analysis techniques.
We believe these facts have been well-known by many security engineering professionals for a while now, since they are “in the trenches” each day trying to separate the wheat from the chaff. It’s time to move on from the completely manual approach and integrate better DevSecOps methodologies into the vulnerability remediation process.
Research is the heart of contextual analysis
Unfortunately, today it is still impossible to automatically define the needed rules for performing precise contextual analysis. Almost all vulnerability advisories do not contain formatted fields (or even free text) that provide the information needed for performing contextual analysis for each CVE. For example – what are the vulnerable functions or the vulnerable configuration of the affected component.
While generic techniques are possible (for example – checking if the vulnerable library is even imported or checking whether the vulnerable service is actually started via runtime hooks) they will never give the needed accuracy that’s possible only with a per-CVE contextual scanner.
One of the much-welcomed pioneers in this field are the maintainers of the Go Vulnerability Database where each security advisory also contains the list of vulnerable functions. Although this doesn’t solve 100% of the cases, this is an amazing start and we applaud them for cataloging this data.
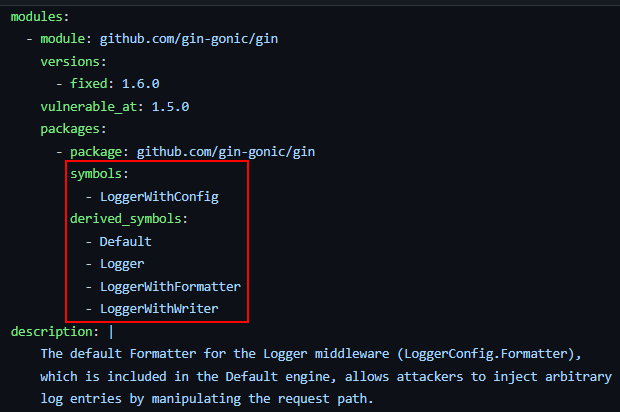
JFrog’s contextual analysis is based on the daily work of JFrog’s security research team, which analyzes each new vulnerability on the same day it is disclosed, to provide the fastest and most accurate contextual analysis.
Contextual Analysis With JFrog Advanced Security
This research was powered by the new “Contextual Analysis” feature which is included in the recently announced JFrog Advanced Security set of capabilities for JFrog Xray. This release takes JFrog Xray out of its familiar software composition analysis space and into the realm of advanced software supply chain security.
Contextual Analysis uses the context of the artifact to identify whether vulnerabilities are applicable or not. This process involves running automated contextual scanners on the container image to determine reachable paths and the configuration settings for the analyzed vulnerabilities. Xray automatically validates high and very high impact vulnerabilities, such as those that have prerequisites for exploitations, and provides contextual analysis information to assist in figuring out which ones are applicable or not. This saves developers from a lot of wasted time and effort.
- Save developer time by only remediating vulnerabilities that are applicable
- Analyze the finished code (binary) the same way an attacker would
- Know which CVEs are exploitable and their potential impact
- Test a vulnerability in the context of the complete artifact, build or Release Bundle
- Enable action and remediation in the context of the artifact, build or Release Bundle


