

Critical Vulnerability in HAProxy (CVE-2021-40346): Integer Overflow Enables HTTP Smuggling

JFrog Security research teams are constantly looking for new and previously unknown vulnerabilities in popular open-source projects to help improve their security posture. As part of this effort, we recently discovered a potentially critical vulnerability in HAProxy, a widely used open-source load balancer proxy server that is particularly suited for very high traffic web sites and used by many leading companies. It is also shipped with most mainstream Linux distributions, and is often deployed by default in cloud platforms. JFrog Security responsibly disclosed this vulnerability and worked together with HAProxy’s maintainers on verifying the fix.
The vulnerability, CVE-2021-40346, is an Integer Overflow vulnerability that makes it possible to conduct an HTTP Request Smuggling attack, giving it a CVSSv3 score of 8.6. This attack allows an adversary to “smuggle” HTTP requests to the backend server, without the proxy server being aware of it. The smuggled requests have various impacts, depending on HAProxy’s configuration and the backend web server configuration:
- Bypassing security controls, including any ACLs defined in HAProxy
- Gaining unauthorized access to sensitive data
- Executing unauthorized commands or modifying data
- Hijacking user sessions
- Exploiting a reflected XSS vulnerability without user interaction
and more.
This vulnerability was fixed in versions 2.0.25, 2.2.17, 2.3.14 and 2.4.4 of HAProxy, see also the Fixes and Workarounds section at the bottom for a solution if you are using HAProxy but cannot upgrade to any of the new versions.
As this vulnerability is a bit complex, we will begin with a technical background and then deep-dive to the technical details.
Technical Background
As previously mentioned, the integer overflow vulnerability can lead to an HTTP Request Smuggling attack (HRS). We will first briefly describe:
- HTTP Request Smuggling
- HAProxy’s HTTP request processing phases (simplified)
HTTP Request Smuggling
HTTP Request Smuggling is an attack technique that emerged in 2005. It is based on interfering with the processing of HTTP requests between the frontend server (i.e. HAProxy) and the backend server. An adversary typically exploits this technique by sending a specially crafted request that includes an additional request in its body. On a successful attack, the inner request is smuggled through the frontend (that considers it as only the request’s body) but is consumed as a normal request by the backend.
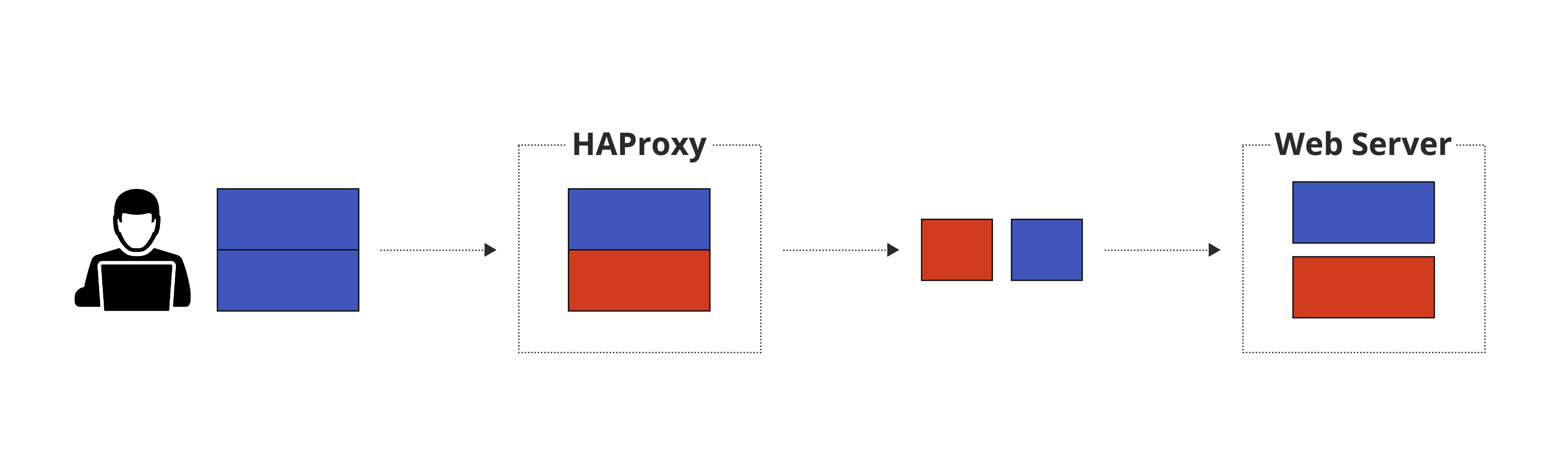
In most cases, the smuggling technique is done by supplying both the Content-Length and Transfer-Encoding headers with contradicting lengths in the same request and aiming for parsing inconsistencies between the frontend and backend servers. In our case, however, the attack was made possible by utilizing an integer overflow vulnerability that allowed reaching an unexpected state in HAProxy while parsing an HTTP request – specifically – in the logic that deals with Content-Length headers.
An important enabler condition that makes this class of attacks possible is that when the frontend server forwards HTTP requests to the backend, it uses the same established TCP connection instead of wasting time on opening and closing sockets. The requests are sent back to back and it is up to the backend server to decide where a request ends and the next one begins.
HAProxy’s HTTP request processing phases (simplified)
The HAProxy load balancer’s most basic functionality is proxying HTTP requests arriving from a client to some backend server. The HTTP request handling logic can be simplified to two phases – Initial parsing and further processing (simplified, with a focus on the Content-Length header):
Phase 1: Initial minimal parsing of the HTTP request:
- Upon finding a Content-Length header, its length value is saved aside. This size determines the length of the request body to be read from the client and sent towards the backend.
- In case additional Content-Length headers are encountered – if they have a different value, the request is dropped. Otherwise, they are ignored.
- The entire request is parsed into an internal representation – stored as an array of htx block structures (a block for each header, for the request body, etc.) to be processed in Phase 2.
Phase 2: Main processing of the request
- The code goes over the htx blocks array for processing the request and preparing the request that will be forwarded to the backend
- When encountering the first Content-Length header block, the code takes its value string for use in the Content-Length header string of the forwarded request.
- Further Content-Length headers encountered are ignored (skipped)
Notice that Phase 1 makes sure the Content-Length value is coherent (only one header and a single value will be passed further).
Attack Scenario – Bypassing http-request ACLs
This scenario demonstrates triggering an HTTP request smuggling attack to bypass ACL rules that were defined by HAProxy.
First, we consider a sample HAProxy instance that denies requests to paths beginning with /admin/ or including an HTTP header abc with value xyz:
http-request deny if { path_beg /admin/ }
http-request deny if { req.hdr(abc) -m str xyz }

Next, we send the following specially crafted message to HAProxy:
POST /index.html HTTP/1.1
Host: abc.com
Content-Length0aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa:
Content-Length: 60
GET /admin/add_user.py HTTP/1.1
Host: abc.com
abc: xyz
What happens inside HAProxy
Let’s focus on the Content-Length0aaa… header. In phase 1 of the parsing, it is treated as any other simple header and is just stored in its htx block structure. The structure encodes header name length into only 8 bits (should be under 256 characters), so due to the fact that this header’s name is of 270 bytes, it causes an unsigned integer overflow and its name length is saved in the htx block as 14 (270 modulo 256). Its value length is stored as 1 – it should have been 0 (no characters after the ‘:’), but the overflown bit from the name field is flowing to the value length and sets the value length to 1.
HAProxy then sees the special header Content-Length with value 60 and uses it as the body length (to read 60 remaining bytes from the packet and later send them to the backend). It reads and stores the body and finishes phase 1.
Then, at phase 2 – while iterating over the htx blocks array, it encounters the Content-Length0aaa… header, reads 14 characters for getting the name and treats it as a legitimate Content-Length header! It reads its value (which should start after the name, and of length 1) which is 0, and thus adds the string content-length: 0 while creating the to-be-forwarded request.
Next, it encounters the Content-Length: 60 header but just ignores it (according to the original logic).
The resulting request that will be sent towards the backend is as follows:
POST /index.html HTTP/1.1
host: abc.com
content-length: 0
x-forwarded-for: 192.168.188.1
GET /admin/add_user.py HTTP/1.1
Host: abc.com
abc: xyz
Upon receiving the request, the backend server correctly parses the POST request as having no body. Then, it expects the next request to arrive on the same connection, thus treating the GET that was previously considered the POST’s body as a new and legitimate HTTP request! This new request bypassed HAProxy’s ACL filtering as we showed above and was parsed successfully by the backend.
Getting the HTTP response for the smuggled request
As explained in the above scenario, HAProxy is only aware of a single HTTP request being forwarded and thus only returns a single HTTP response (the first) from the backend server back to the client.
If we were also interested in receiving the HTTP response for the smuggled request, we could achieve it by sending two consecutive requests:
- The first request is very similar to the specially crafted HTTP request from earlier, but will leave an unfinished request in the input buffer of the backend server, causing the backend server to wait for more input before processing the smuggled request. The request will be unfinished because we will not end it with the double CRLF that marks the end of the HTTP GET request headers. (In case of a smuggled POST request, supply a body that’s shorter than the smuggled request’s Content-Length). In addition, we end this request with a partial header line (DUMMY:) without a line break (CRLF), and also omit the Host header from the smuggled request – these will be explained at the end of this section.
POST /index.html HTTP/1.1 Host: example.com Content-Length0aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa: Content-Length: 39 GET /admin/secret.html HTTP/1.1 DUMMY:
- The second request will be a simple legitimate GET request that reaches the same backend. The backend server will treat this request as the continuation of the previous partial smuggled request.
GET /index.html HTTP/1.1 Host: example.com
- The second request will be concatenated to the first smuggled request and its double CRLF will cause the completion of the smuggled request. This will cause the smuggled request to be processed by the backend, and return an HTTP response that will be returned to the client. The complete smuggled request will look as follows in the backend server:
GET /admin/secret.html HTTP/1.1 DUMMY:GET /index.html HTTP/1.1 Host: example.com
The reason for including the partial header DUMMY: line is for keeping the request valid. The backend does not expect an HTTP request line (e.g. GET /index.html HTTP/1.1) inside the header section. The partial header causes the request start-line to be parsed as just the DUMMY header’s value, making the request valid. Omitting the Host header from the smuggled request was done for avoiding duplicate Host headers of the complete smuggled request – as the second request already has a Host header.
Attack demonstration – ACL bypass

Vulnerability Details
Additional details about CVE-2021-40346 that complement the explanation above –
The unsigned integer overflow vulnerability occurs in the line that sets the header’s name and value lengths to the htx block info in the htx_add_header function that is called as part of the initial parsing:
blk->info += (value.len << 8) + name.len;
To explain the function and the bug, it is important to understand the way the block info field works. This information comes from the htx-api documentation and is copied here:
* Block's info representation :
0b 0000 0000 0000 0000 0000 0000 0000 0000
---- ------------------------ ---------
type value (1 MB max) name length (header/trailer - 256B max)
----------------------------------
data length (256 MB max)
(body, method, path, version, status, reason)
Supported types are :
- 0000 (0) : The request start-line
- 0001 (1) : The response start-line
- 0010 (2) : A header block
- 0011 (3) : The end-of-headers marker
...
The htx_add_header function works as follows:
It receives strings representing the header name and header value as parameters. It first creates a new block with type header (0010 binary). Then, it adds to the info field the sum of the header name’s length and the header value’s length shifted left 8 bits. This complies with the info representation above. Then, the header’s name is copied lowercase into the block’s payload, and right after it, the value is copied into the block. For example, the header “Myheader: Myvalue” will be represented as follows:
block->info: (2 << 28) + (7 << 8) + 0x08 == 0x20000708 block data/payload: myheaderMyvalue
As shown in the demonstration above, since the header name’s length is not checked, it is possible to pass a header with a name longer than the maximum 255 bytes to overflow the header name field and make phase 2 processing see a different header name than phase 1 parsing.
Automating the Discovery
A method to automate the discovery of this and similar integer overflow vulnerabilities could consist of searching for a pattern where a variable is shifted left and then another variable is added to the result as in the pattern below, and the conditions below apply.
RESULT = (A << SHIFT_AMOUNT) + B
Additional conditions: the added variable (B) arrives from user input, its size isn’t restricted to be less than the SHIFT_AMOUNT bits can hold, and its type is bigger than the space created by the left shift (more bits than SHIFT_AMOUNT).
The presence of this code in an interesting area such as HTTP parsing may help highlight it compared to other similar findings that fit the above conditions. As part of the research work, JFrog utilizes the vulnerabilities discovered by its security research team to enhance its upcoming automatic zero day detection capabilities, including for this type of vulnerability where an integer overflow leads to a logic bug and not only memory corruption.
Fixes and Workarounds
As advised by HAProxy, the best solution is to upgrade to HAProxy version 2.0.25, 2.2.17, 2.3.14 or 2.4.4, which completely fixes the issue by adding size checks for the name and value lengths.
If upgrading is not possible, adding the following line to HAProxy’s configuration should mitigate all variants of this attack that we’ve encountered:
http-request deny if { req.hdr_cnt(content-length) gt 1 }
http-response deny if { res.hdr_cnt(content-length) gt 1 }
Contextual CVE scanning can automatically identify if such a mitigation is in place when scanning an uploaded artifact, and notify the user accordingly.
If you are not sure of the version you have, consider using SCA tools such as Xray to determine the version and whether your artifacts are affected.
Acknowledgement
We would like to thank Willy Tarreau, HAProxy CTO, and the HAProxy security team for promptly and professionally handling this issue.


